✕ 文件回写 ✓ 属性回写 ✕ 直接返回 ✕ 流式返回 ✕ 统计值
概述
GraphSAGE(SAmple and aggreGatE)是一种归纳式的学习框架,它不是为每个节点训练独立的嵌入,而是学习一连串函数,通过从节点的局部邻域中进行采样和聚合特征来生成嵌入,于是可以高效地生成新数据的节点嵌入。GraphSAGE 是由斯坦福大学的 W.H Hamilton 等人于 2017 年提出的。
- W.L. Hamilton, R. Ying, J. Leskovec, Inductive Representation Learning on Large Graphs (2017)
GraphSAGE 算法使用训练好的 GraphSAGE 模型来生成节点嵌入。训练过程在 GraphSAGE 训练算法中有详细说明。
基本概念
转导式与归纳式框架
大多数传统的图嵌入方法在迭代过程中利用所有节点的信息来学习节点嵌入。当新节点加入网络时,则必须使用整个数据集重新训练模型。这些转导式框架泛化性差。
GraphSAGE 却是一种归纳式框架。它训练出一组聚合函数,而不是为每个节点创建单独的嵌入,于是可以根据现有节点的特征和结构来推导新加入节点的嵌入,避免重新进行训练。这种泛化性对于拥有高吞吐量的机器学习系统至关重要。
GraphSAGE:嵌入生成
假设已经训练好了 K 个聚合器函数(表示为AGGREGATEk)和 K 个权重矩阵(表示为Wk)的参数。以下是 GraphSAGE 模型生成节点嵌入(即前向传播)的过程。
1. 邻域采样
在图 G = (V, E) 中,为了生成每个目标节点的嵌入,在其第 1 层直到第 K 层邻域进行采样:
- 在每层采样的节点数量固定为 Sk(k = 1,2,...,K)。
- 采样从第 1 层进行到第 K 层,得到一组节点集合 Bk(k = K,...,1,0)。
- 初始化时,将所有目标节点加入 BK。
- 在第 k 层进行采样时,取 BK-k+1 与在第 k 层采样到的节点集合的并集得到 BK-k。
- 通常采取均匀采样。如果某层的邻居节点数量小于设定的数量,则采取有放回的采样,直到达到所需数量为止。
GraphSAGE 的作者观察到,K 的值不必太大;使用较小的值,如 K = 2,并且 S1·S2 小于 500,就可以取得很好的效果。
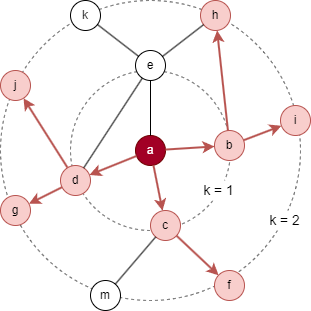
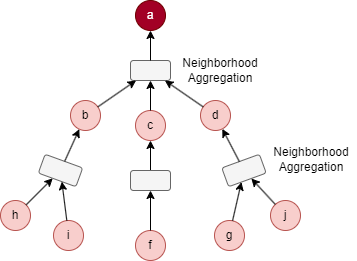
对于上图的目标节点 a,设置 K = 2,S1 = 3,S2 = 5。初始化 B2 = {a}。
- 采样从第 1 层开始:选择 3 个直接邻居,得到 N(a) = {b, c, d},于是 B1 = B2 ⋃ N(a) = {a, b, c, d}。
- 接着,在第 2 层进行采样:基于 N(a) 中的节点选择 5 个邻居,得到 N(b) = {i, h},N(c) = {f},N(d) = {g, j},于是 B0 = B1 ⋃ N(b) ⋃ N(c) ⋃ N(d) = {a, b, c, d, f, g, h, i, j}。
2. 特征聚合
对于每个节点 v ∈ B0,初始化它们的嵌入向量为各自的特征向量:
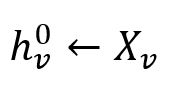
其中每个特征向量(Feature Vector)Xv 由若干指定的数值类点属性的值构成。
目标节点的最终嵌入是通过 K 轮迭代得到的。在第 k 次迭代(k = 1,2,...,K)中,对于每个节点 v ∈ Bk:
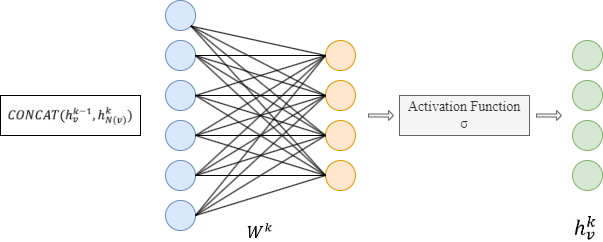
- 使用 AGGREGATEk 聚合器函数将其所有抽样邻居的第 (k-1) 轮向量聚合成一个邻域向量。
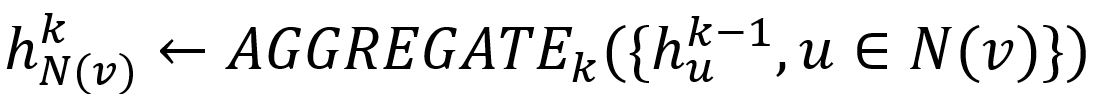
- 将节点的第 (k-1) 轮向量与聚合的邻域向量拼接起来。这个拼接向量接着会经过一个由矩阵 Wk 加权的全连接层和一个非线性激活函数(例如 Sigmoid、ReLu)。
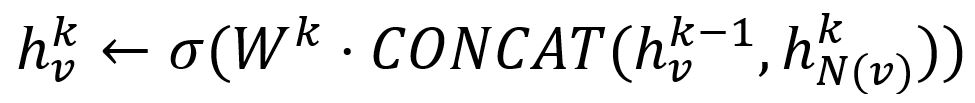
- 对 进行归一化处理:
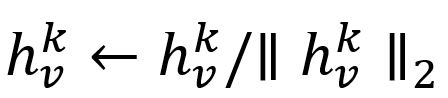
我们将示例中的特征聚合过程描述如下:
| 第 1 轮迭代 | 第 2 轮迭代 |
|---|---|
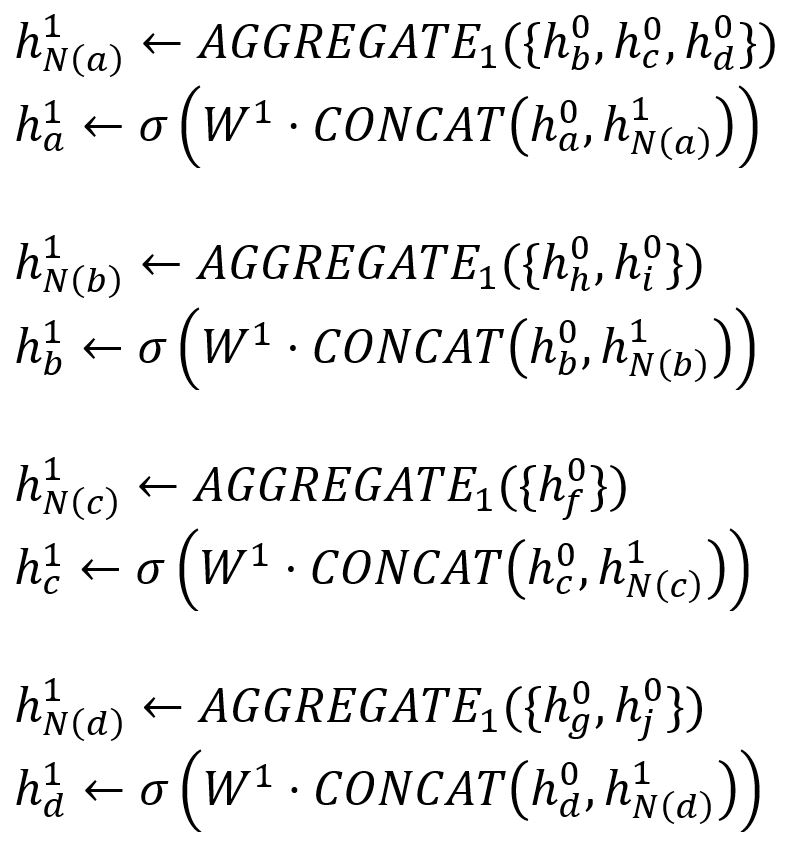 |
 |
特殊说明
- GraphSAGE 算法忽略边的方向,按照无向边进行计算。
语法
- 命令:
algo(graph_sage) - 参数:
名称 |
类型 |
规范 |
默认 |
可选 |
描述 |
|---|---|---|---|---|---|
| model_task_id | int | / | / | 否 | 用于训练模型的 GraphSAGE 训练算法的任务 ID |
| ids | []_id |
/ | / | 是 | 需要生成嵌入的节点 ID;忽略则为所有节点生成嵌入 |
| node_property_names | []<property> |
数值类型,需 LTE | 从模型读取 | 是 | 构成节点特征向量的多个点属性 |
| edge_property_name | <property> |
数值类型,需 LTE | 从模型读取 | 是 | 边权重所在的边属性;未设置时按照非加权图计算 |
| sample_size | []int | / | 从模型读取 | 是 | 列表中的元素依次是在第 K 层至第 1 层邻域的采样个数;列表长度就是采样邻域的层数 |
示例
属性回写
| 配置项 | 回写内容 | 回写至 | 数据类型 |
|---|---|---|---|
| property_name | 节点嵌入 | 点属性 | string |
algo(graph_sage).params({
model_task_id: 4785,
ids: ['ULTIPA8000000000000001', 'ULTIPA8000000000000002']
}).write({
db:{
property_name: 'embedding_graphSage'
}
})
结果:每个节点的嵌入回写至名为 embedding_graphSage 的点属性下