概述
K 最近邻(kNN,k-NearestNeighbor)算法也称邻近算法,是根据一个给定样本的 K 个最相似(例如余弦相似度)样本的分类来决定该样本的分类。该算法由 IEEE 会员 T. M. Cover 和 P. E. HART 于 1967 年提出,是一种最简单的数据分类技术。
虽然名称中包含“邻居”,但 K 最近邻算法在计算相似样本时并不依赖样本之间的关联关系,在图中这意味着 K 最近邻与节点之间的边无关。
算法的相关资料如下:
- T.M. Cover, P.E. Hart, Nearest Neighbor Pattern Classification (1967)
基本概念
选拔相似节点
Ultipa 的 K 最近邻算法将样本定义为图中的节点,用节点的余弦相似度(可阅读《余弦相似度》章节)作为样本的相似度,选出与给定节点 x 相似度最大的 K 个节点 y,即为 K 个最近邻 Kx。
选举分类
用节点的某个属性作为节点所属的分类标签,对选拔出来的 K 个最近邻节点的标签进行统计,将出现次数最多的标签作为 x 的标签:
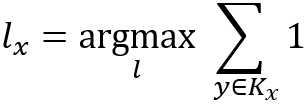
如果出现次数最多的标签有多个,则选取其中相似度相最高的点的标签。
特殊处理
孤点、不连通图
K 最近邻的计算理论上不依赖图中边的存在,无论待计算的节点是否为孤点或处于哪个连通分量中,都不影响它的 K 最近邻的计算。
自环边
K 最近邻的计算与边无关。
有向边
K 最近邻的计算与边无关。
结果和统计值
以下面包含 5 个产品点的图为例(已忽略边),产品有四个属性 price、weight、width 和 height:
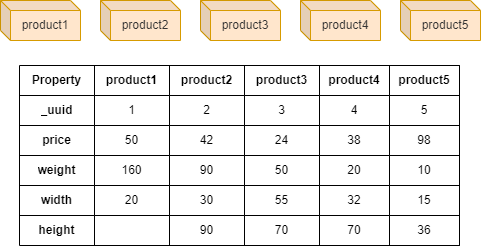
算法结果:给定 product1 节点,基于属性 price、weight 和 width 选出与 product1 最相似的 3 个节点,并指定 height 属性为分类标签
- 选拔出的标签
attribute_value及其在 3 个最近邻中出现的次数count:
| attribute_value | count |
|---|---|
| 70 | 2 |
- 选拔出的 3 个最近邻
node及其与 product1 间的余弦相似度similarity:
| node | similarity |
|---|---|
| 4 | 0.6348920499152856 |
| 3 | 0.7811137489489366 |
| 2 | 0.9763079726833555 |
注:product5 与 product1 的余弦相似度为 0.404234826778782,因此不在 3 个最近邻中。
算法统计值:无
命令和参数配置
- 命令:
algo(knn) params()参数配置项如下:
| 名称 | 类型 | 默认值 |
规范 | 描述 |
|---|---|---|---|---|
| node_id | _uuid |
/ | 必填 | 待计算节点的 UUID |
| node_schema_property | []@<schema>?.<property> |
/ | 数值类的点属性,需LTE,至少需填写两个属性,schema 与点 node_id 的 schema 相同 | 参与余弦相似度计算的点属性 |
| top_k | int | / | >0,必填 | 选取多少个相似节点进行标签选举 |
| target_schema_property | @<schema>?.<property> |
/ | 需LTE,schema 与点 node_id 的 schema 相同,必填 |
标签所在的点属性 |
示例,通过点 UUID = 1 的属性 price、weight 和 width,推算属性 height 的值
algo(knn).params({
node_id: 1,
node_schema_property: [@product.price,@product.weight,@product.width],
top_k: 4,
target_schema_property: @product.height
}) as height return height
算法执行
任务回写
1. 文件回写
配置项 |
各列数据 | 描述 |
|---|---|---|
| filename | 第一行:attribute_value,第二行开始:_id,similarity |
第一行为选中的标签,第二行开始为选拔出的每个相似节点的 ID 以及其与给定节点间的余弦相似度 |
示例:通过点 UUID = 1 的属性 price、weight 和 width,推算属性 height 的值,将算法结果回写至名为 knn 的文件
algo(knn).params({
node_id: 1,
node_schema_property: [@product.price,@product.weight,@product.width],
top_k: 4,
target_schema_property: @product.height
}).write({
file:{
filename: "knn"
}
})
2. 属性回写
算法不支持属性回写。
3. 统计回写
算法不支持统计回写。
直接返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | KV | 选拔出的标签及其在 K 个最近邻中出现的次数 | attribute_value, count |
| 1 | []perNode | 选拔出的 K 个最近邻及余弦相似度 | node, similarity |
示例:通过点 UUID = 1 的属性 price、weight 和 width,推算属性 height 的值,将算法结果定义为别名 a1 和 a2 并返回
algo(knn).params({
node_id: 1,
node_schema_property: [@product.price,@product.weight,@product.width],
top_k: 3,
target_schema_property: @product.height
}) as a1, a2 return a1, a2
流式返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | KV | 选拔出的标签及其在 K 个最近邻中出现的次数 | attribute_value, count |
示例:通过点 UUID = 1 的属性 price、weight 和 width,推算属性 height 的值并更新该点属性 height 的值
algo(knn).params({
node_id: 1,
node_schema_property: [@product.price,@product.weight,@product.width],
top_k: 3,
target_schema_property: @product.height
}).stream() as a1
with a1.attribute_value as value
update().nodes(1).set({height: value})
实时统计
算法无统计值。