概述
LINE 是 Large-scale Information Network Embedding(大规模信息网络嵌入)的简称,作为一种图嵌入模型,它使用节点的 BFS 邻域信息(一阶或二阶相似度)构造训练样本,并使用和 Node2Vec 类似的方式训练得到节点的嵌入向量。LINE 算法能应用到各类非常大型的网络上,是由微软的 Jian Tang 等人于 2015 年提出的。
算法的相关资料如下:
- J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, Q. Zhu, LINE: Large-scale Information Network Embedding (2015)
基本概念
一阶相似性和二阶相似性
在图中,节点间的一阶相似性(First-order Proximity)取决于相连关系,节点间的边权重越大(无权重图的边权值视为 1;仅考虑非负权重值),一阶相似性就越高,如果没有边,一阶相似度为 0。一阶相似性用于表示局部结构。
二阶相似性(Second-order Proximity)则表示全局网络结构,它依赖于节点间的共同邻居。这个概念很容易理解,比如在社交网络中,两个人的共同好友越多,这两个人的相关性就越高。如果两个节点没有共同邻居,则它们的二阶相似度为 0。
下图中,边的粗细代表权重大小。节点 6 和 7 在嵌入空间的位置应该很接近,因为它们之间的边权重很高,具有一阶相似性;另外,虽然节点 5 和 6 之间没有边相连,但它们有很多共同邻居,也应该被嵌入到相互靠近的位置,它们具有二阶相似性。
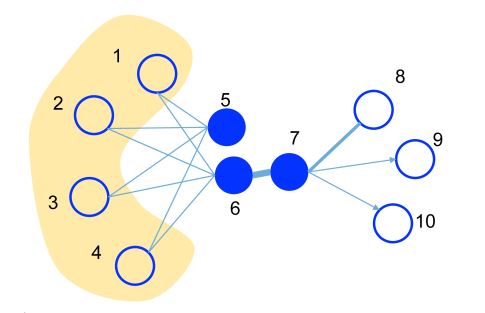
模型描述
我们分别介绍 LINE 模型如何保留一阶相似度和二阶相似度,以及合并这两种相似度的一种简单方法。
保留一阶相似度
对于图 G = (V, E),为描述一阶相似度,LINE 模型定义任意两个节点 vi 和 vj 间的联合概率分布为:
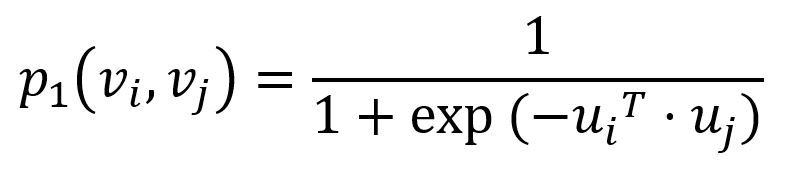
其中 u 是节点在嵌入空间的表示。对应的经验概率分布可以表示为:
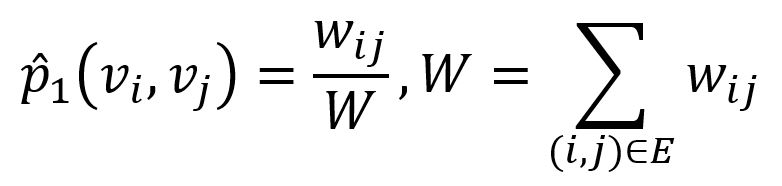
其中 wij 表示节点 vi 和 vj 间的边的权重。
为保留一阶相似度,一个直接的方法就是使上述两个概率分布的差异最小(即模型预测值接近于真实值)。LINE 采用 KL(Kullback-Leibler)散度衡量这个差异(忽略常数项):
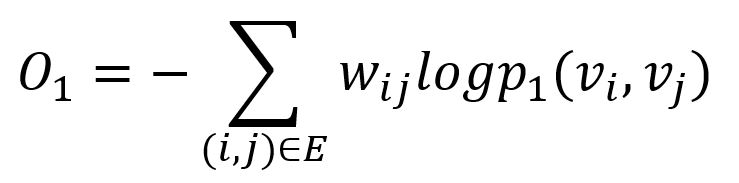
请注意,一阶相似度仅适用于无向图。
保留二阶相似度
每个节点可以有两种向量表示,一个是节点本身的向量表示,一个是节点作为其他节点的上下文时的向量表示。在“上下文”上具有相似分布的节点具有二阶相似度。给定节点 vi 时,产生其上下文(邻居)节点 vj 的概率定义为(为了不失一般性,假设图是有向的):
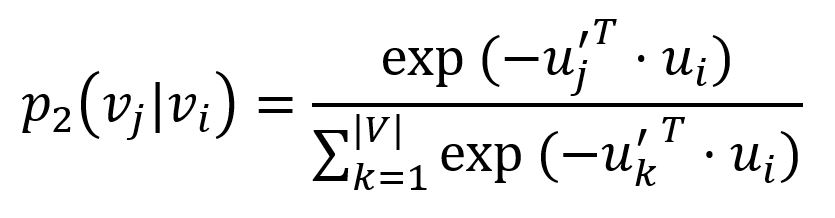
其中 u' 为节点被视为上下文时的向量表示,|V| 为图中的节点总数。对应的经验概率分布可以表示为:
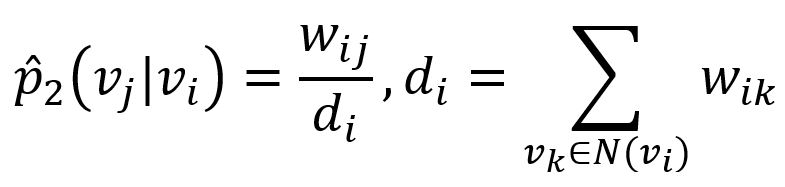
其中 wij 表示节点 vi 和 vj 间的边的权重,di 表示节点 vi 的出度。
类似地,LINE 采用 KL(Kullback-Leibler)散度衡量两个概率分布的差异(忽略常数项):
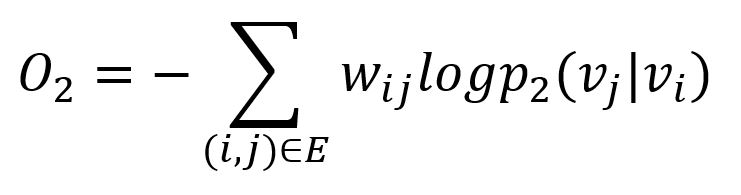
二阶相似度既适用于无向图,也适用于有向图。
合并一阶相似度和二阶相似度
为了在嵌入结果同时保留一阶相似度和二阶相似度,一个简单的方法是分别训练保留一阶相似度和二阶相似度的模型,然后将每个节点两个嵌入结果拼接。
模型优化
负采样
优化上述 O2 的计算量很大,因为计算条件概率 p2(·|vi) 需要考虑所有节点。为了解决这个问题,LINE 算法采用的优化方法是负采样。具体来说,从任意节点 vi 到 vj 的边的目标函数为:
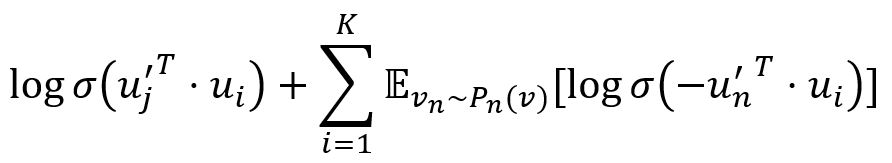
其中,σ 是 Sigmoid 函数,前半部分是观察到的边,后半部分是 K 个负样本(边),负样本的概率分布为 Pn(v) ∝ dv3/4,dv 是节点 v 的出度。
关于负采样,读者可参考文档——Skip-gram 模型优化。
特殊处理
孤点、不连通图
孤点没有邻居节点,与其他任何节点都没有一阶相似度或二阶相似度。
节点只会与同一连通分量内的节点有一阶相似度或二阶相似度。
自环边
节点的自环边不影响它与其他节点的一阶相似度或二阶相似度。
有向边
一阶相似度仅适用于无向图。二阶相似度既适用于无向图,也适用于有向图。
命令和参数配置
- 命令:
algo(line) params()参数配置如下:
| 名称 | 类型 |
默认值 |
规范 |
描述 |
|---|---|---|---|---|
| edge_schema_property | []@<schema>?.<property> |
/ | 数值类的边属性,需LTE | 边权重所在的一个或多个属性名称,带不带 schema 均可,无该属性的边不参与计算;忽略表示不加权 |
| dimension | int | / | >=1 | 节点嵌入向量的维度 |
| resolution | int | / | >=1 | 如:10、100 |
| learning_rate | float | / | (0,1) | 初始学习率,每次迭代后学习率都会降低,直至减到 min_learning_rate |
| min_learning_rate | float | / | (0,learning_rate) |
最小学习率 |
| neg_num | int | / | >=0 | 负采样时负样本数量,建议 0~10 |
| train_total_num | int | / | >=1 | 模型训练次数 |
| train_order | int | 1 | 1 或 2 | 相似度类型,1 代表一阶相似度,2 代表二阶相似度 |
| limit | int | -1 | >=-1 | 需要返回的结果条数,-1 或忽略表示返回所有结果 |
算法执行
任务回写
1. 文件回写
配置项 |
各列数据 |
|---|---|
| filename | _id, embedding_result |
2. 属性回写
算法不支持属性回写。
3. 统计回写
算法无统计值。
直接返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | []perNode | 各点及其图嵌入结果 | _uuid, embedding_result |
流式返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | []perNode | 各点及其图嵌入结果 | _uuid, embedding_result |
实时统计
算法无统计值。