概述
重叠相似度(Overlap Similarity)是杰卡德相似度的一种延申,也叫 Szymkiewicz–Simpson 系数。它用两个集合的交集大小除以两个集合中较小的集合的大小,以此来表示两个集合的相似程度。
集合中的元素通常代表应用场景中实体的一系列属性,例如计算两个信贷申请之间的相似度时,这些元素就是申请表中填写的手机号、邮箱、设备IP、公司名称等。在一般的图应用中,这类信息通常会存储为节点的属性,但是在执行本算法时,这些信息需要设计为节点并入图。
重叠相似度的取值范围是 [0,1],数值越大越相似。
基本概念
集合
集合由多个元素构成;集合中的元素是无序的、互不相同的;集合 A 中元素的数量就是集合 A 的大小,记作|A|。
由所有既属于集合 A 又属于集合 B 的元素构成的集合称作 A 和 B 的交集,记作A⋂B。
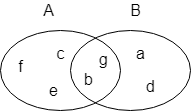
上图中,集合 A 为{b,c,e,f,g},集合 B 为{a,b,d,g},交集 A⋂B 为{b,g}。
重叠相似度
已知集合 A 和 B,它们之间的重叠相似度可以表示为:
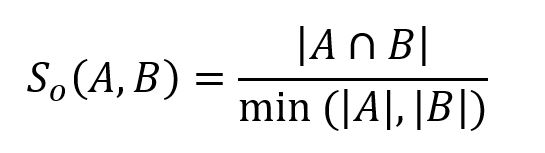
根据此定义,可计算出前面例子中集合 A 与 B 的重叠相似度:2 / 4 = 0.5。
邻居
用图中节点 x 的邻居集合 Kx 表示集合 A,节点 y 的邻居集合 Ky 表示集合 B。需要注意的是,Kx 和 Ky 均既不包含重复值,也不包含 x 和 y。因此,在图上按边查找邻居时需要排除以下干扰:
x、y与邻居之间的多条边x、y的自环边x和y之间的边

上图中,红色节点的邻居数为 3(排除绿色节点),绿色节点的邻居数为 5(排除红色节点),红、绿节点的共同邻居数为 2,这两个节点的重叠相似度为 2 / 3 = 0.6667。
特殊处理
孤点、不连通图
在实际应用中很少出现有计算价值的孤点(空集),有孤点则交集为空,重叠相似度为 0。
属于不同连通分量的两个点,它们的重叠相似度必然为 0。
自环边
节点的自环边不会增加节点的邻居数。
有向边
对于有向边,本算法会忽略边的方向,按照无向边进行计算。
命令和参数配置
- 命令:
algo(similarity) params()参数配置项如下:
名称 |
类型 |
默认值 |
规范 |
描述 |
|---|---|---|---|---|
| ids 或 uuids | []_id 或 []_uuid |
/ | 必填 | 指定计算的第一组节点 ID / UUID |
| ids2 或 uuids2 | []_id 或 []_uuid |
/ | 选填 | 指定计算的第二组节点 ID / UUID |
| type | string | cosine | jaccard 或 overlap 或 cosine 或 pearson 或 euclideanDistance 或 euclidean |
相似度度量标准: jaccard:杰卡德相似度 overlap:重叠相似度 cosine:余弦相似度 pearson:皮尔森相关系数 euclideanDistance:欧几里得距离 euclidean:标准化欧几里得距离 |
| node_schema_property | []@<schema>?.<property> |
/ | 数值类的点属性;需 LTE;是否携带 schema 均可 | type 为 cosine / pearson / euclideanDistance / euclidean 时,必须指定的构成向量的至少两个点属性,无该属性的点不参与计算;type 为 jaccard / overlap 时,此参数无效 |
| limit | int | -1 | >=-1 | 返回的结果条数,-1 表示返回所有结果 |
| top_limit | int | -1 | >=-1 | 仅选拔模式可用,每个选拔结果 top_list 的长度,-1 表示返回完整结果 |
计算模式
本算法有两种计算模式:
- 配对模式:配置有效的两组节点时,将第一组与第二组中的节点两两配对(笛卡尔乘积),逐对计算相似度
- 选拔模式:仅配置(第)一组有效节点时,对于其中每一个节点,计算其与图中其他所有点的相似度,返回相似度大于 0 的结果并按相似度大小降序排列
示例
示例图
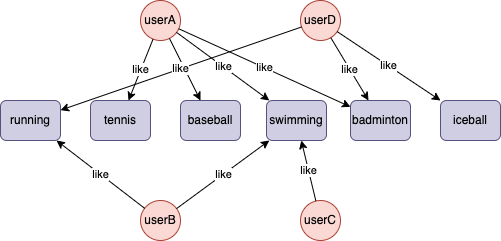
示例图展示 4 位用户 userA、userB、userC 和 userD(UUID 依次为 1、2、3、4)对各项体育运动的喜爱情况:
任务回写
1. 文件回写
| 计算模式 | 配置项 | 各列数据 |
|---|---|---|
| 配对模式 | filename | node1,node2,similarity |
| 选拔模式 | filename | node,top_list |
示例:计算 userC 与 userA、userB、userD 两两之间的重叠相似度,将算法结果回写至文件
algo(similarity).params({
ids: "userC",
ids2: ["userA", "userB", "userD"],
type: "overlap"
}).write({
file:{
filename: "sc"
}
})
结果:文件 sc
userC,userA,0.25
userC,userB,0.5
userC,userD,0
示例:计算用户 UUID = 1,2,3,4 各自与其他所有节点的重叠相似度,将算法结果回写至文件
algo(similarity).params({
uuids: [1,2,3,4],
type: "overlap"
}).write({
file:{
filename: "list"
}
})
结果:文件 list
userA,userC:1.000000;userB:0.500000;userD:0.333333;
userB,userC:1.000000;userA:0.500000;userD:0.500000;
userC,userA:1.000000;userB:1.000000;
userD,userB:0.500000;userA:0.333333;
2. 属性回写
算法不支持属性回写。
3. 统计回写
算法无统计值。
直接返回
计算模式 |
别名序号 |
类型 | 描述 | 列名 |
|---|---|---|---|---|
| 配对模式 | 0 | []perNodePair | 各点对及相似度 | node1, node2, similarity |
| 选拔模式 | 0 | []perNode | 各点及其选拔结果 | node, top_list |
示例:计算用户 UUID = 1 与用户 UUID = 2,3,4 两两之间的杰卡德相似度,并按照相似性大小降序排列结果
algo(similarity).params({
uuids: [1],
uuids2: [2,3,4],
type: "overlap"
}) as overlap
return overlap
order by overlap.similarity desc
结果:
| node1 | node2 | similarity |
|---|---|---|
| 1 | 3 | 1 |
| 1 | 2 | 0.5 |
| 1 | 4 | 0.333333333333333 |
示例:分别选拔图中与节点 UUID = 1,2 间重叠相似度最高的节点
algo(similarity).params({
uuids: [1,2],
type: "overlap",
top_limit: 1
}) as top
return top
结果:
| node | top_list |
|---|---|
| 1 | 3:1.000000, |
| 2 | 3:1.000000, |
流式返回
计算模式 |
别名序号 |
类型 | 描述 | 列名 |
|---|---|---|---|---|
| 配对模式 | 0 | []perNodePair | 各点对及相似度 | node1, node2, similarity |
| 选拔模式 | 0 | []perNode | 各点及其选拔结果 | node, top_list |
示例:计算用户 UUID = 3 与用户 UUID = 1,2,4 两两之间的重叠相似度,仅返回相似度大于 0 的结果
algo(similarity).params({
uuids: [3],
uuids2: [1,2,4],
type: "overlap"
}).stream() as overlap
where overlap.similarity > 0
return overlap
结果:
| node1 | node2 | similarity |
|---|---|---|
| 3 | 1 | 1 |
| 3 | 2 | 1 |
示例:选拔图中与节点 UUID = 1 重叠相似度最高的两个节点
algo(similarity).params({
uuids: [1],
type: "overlap",
top_limit: 2
}).stream() as top
return top
结果:
| node | top_list |
|---|---|
| 1 | 3:1.000000,2:0.500000, |
实时统计
算法无统计值。