Ultipa Graph HTAP System(以下简称 Ultipa Graph)是一套超高性能原生图数据库与计算系统。
Ultipa Graph 产品生态包含:
- 业界最高性能的实时图计算引擎;
- 高性能、高可用、持久化存储服务;
- 简洁、流畅的用户图形操作界面与知识图谱系统;
- 功能全面的命令行工具;
- 灵活的快速导入导出工具;
- 可一键部署的 docker 镜像;
- 各种流行编程语言的 SDK、API 开发工具;
- 本文所重点讲述的图操作语言(GQL)UQL。
Ultipa Graph 支持丰富的查询方式、大量的高性能图算法以及对海量数据的实时处理,真正意义上把非常耗时的非实时工作提升为实时(real-time)处理的操作,为用户节省大量时间成本,为图计算产品适用于更广阔的商业和大数据分析场景带来无限可能。
什么是 UQL
UQL 全称 Ultipa Graph Query Language,是通用图操作语言 GQL 的一种。UQL 是 Ultipa 独有的高性能查询与管理语言,其极低的学习成本能使开发人员快速上手使用 Ultipa 图系统。UQL 支持对 Ultipa 图系统的查询、删除、修改、添加、图遍历、路径查找、子图匹配、图集管理、schema 管理、属性管理、引擎管理、索引管理、各类任务管理、权限管理等功能。用户可以通过 Ultipa CLI(命令行工具)、Ultipa Manager(高可视化数据库查询与管理工具)或者 Ultipa Drivers(SDK、APIs等规范)运行 UQL,UQL 将很快实现图灵完备,给开发者提供更好的使用体验。
Ultipa 团队已经作为 LDBC(Linked Data Benchmark Council,国际关联数据基准委员会)的一员参与图查询语言 GQL 标准的制定。该标准预计在 2024 年推出,UQL 在整体功能与兼容性上将和 GQL 国际标准保持同步。
常用术语
| 名称 | 类型 |
|---|---|
| GQL | Graph Query Language,即图查询语言,也是继 SQL(Structured Query Language)之后唯一会成为数据操作标准的语言。 |
| UQL | Ultipa Graph Query Language,属于 GQL 的一种,可以全方位地查询与操作 Ultipa 图系统。 |
| 点 (Node) | 代表真实世界中的实体,即图论中的顶点 (vertex),在 Ultipa 图系统中也称作节点。 |
| 边 (Edge) | 代表真实世界中实体间的关系,即连接两个节点的边。Ultipa 图系统中的边均为有向边(见下面 "入边、出边、左向边、右向边" 的解释)。边的两个端点可以相同也可以不相同,相同时边称为自环边(loop)。 |
| 元数据 (Metadata) | 即点、边数据的统称。 |
| 路径 (Path) | 有确定的起点和终点、由点边交替相连构成的序列称为路径,路径中的点可以重复出现,边不能重复出现。路径中的点、边序列即可看作路径的唯一标识符。 |
| 中介点 (Intermediate Node) | 一条(或一段)路径中除了起点、终点以外的其他节点。 |
| 环路 (Circle) | 当路径的中介点与其他点重复时,称该路径含有环路成分。如果仅仅是起点与终点重复,则不含环路。 例如: 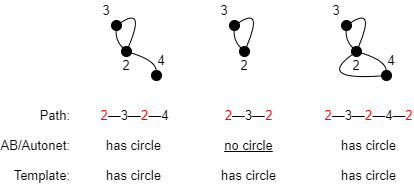 (进行路径查询时,含有环路成分的路径在使用查询参数 no_circle() 时会被过滤掉,不会被返回。) |
| 最短路径 (Shortest Path) | 从起点经过最少的边(至少一条边)达到终点时,所构成的路径称为该起点到该终点的最短路径。当边带有权重时,“最少的边”应理解为“权重和最小的边”。 |
| 图 (Graph) | 由点和边组成的数据集称为图,图也可以看成由多条路径相交组成的数据集合,图的最小单位是点。图不一定是连通的。 |
| 子图 (Subgraph) | 子图由全图的一部分点和边组成,点查询、路径查询的结果都可以看作是一张子图。 |
| 图集 (GraphSet) | 一个图集包含一张图,以及图模型(schema及属性的定义)、在该图上创建的索引、LTE操作、全文索引、算法任务等内容。 |
| 图系统 (Graph System) | 即 Ultipa 图数据库与计算系统,也简称 Ultipa Graph。通常构建在一个服务器集群之上,由图查询引擎、图算法引擎、全文索引引擎等构成,实际使用中的 Utlipa 图系统还包含多个图集、策略及用户、安装的算法包等。 |
| 实例 (Instance) | Ultipa 图系统服务实例,即 Ultipa Server 的运行程序;每个实例一般运行在一台虚拟或者物理主机之上,多个实例可以组成一个集群系统。 |
| 模式 (Schema) | 点、边所代表的实体、关系的类型,由多个属性构成,一个点或边只能属于一个 schema。 |
| 属性 (Property) | Schema 的某个维度的数据项。属性分为系统属性(System Property,见下面 "唯一标识符"、"边起点"、"边终点" 的解释)和自定义属性(Custom Property)。 |
| 图模型 (Graph Model) | 图中所有schema、属性的定义,表达了图所描述的具体场景。 |
| 属性索引 (Property Index) | 对元数据的属性值创建索引并存储到磁盘中,能提高全图元数据查找时的属性过滤效率。 |
| 全文索引 (Full-text Index) | 对元数据的属性值进行分词处理、创建反向索引并存储到磁盘中,能提高长文本的关键词查询效率与准确率。全文索引支持不同的字典,以便针对不同的数据集作出切词优化。 |
| 引擎索引 (Engine Index) | 将属性值或其某种形式的索引加载到计算引擎(内存,见下面 "LTE" 的解释)中,从而降低磁盘 IO 成本,提高路径查询、深度图检索的效率。通常能使效率提升几个数量级,在进行步间比较、步间过滤、权重最短路径查询时必须使用。 |
| 过滤器 (Filter) | 用于在图操作中对点、边进行过滤,通常出现在代表点、边的命令参数中。Ultipa Filter 本质上是一个逻辑树,使用各种条件操作符、逻辑操作符、数值运算符等对操作数进行运算并返回 true 或 false,详见《过滤器 | 操作符》一章。 |
| LTE | Load to Engine,将属性加载到计算引擎,即创建引擎索引。 |
| UFE | Unload from Engine,从计算引擎移除属性,即删除引擎索引。 |
| 入边 | 从其它点指向点 a 的边称为 a 的入边,或 a 的入方向的边,可表示为 a<--、-->a |
| 出边 | 从点 a 指向其它点的边称为 a 的出边,或 a 的出方向的边,可表示为 a-->、<--a |
| 左向边 | 在路径中从后面一个点指向之前一个点的边称为左向边,可表示为 a<--b |
| 右向边 | 在路径中从之前一个点指向后面一个点的边称为右向边,可表示为 a-->b |
| 唯一标识符 (ID) | 点、边的系统属性之一,包括点的 _id(string,最大长度 128 字节),以及点、边的 _uuid(uint64)。ID 不隶属于 schema,在全图范围内保持唯一。 |
| 边起点 (FROM) | 边的系统属性之一,有 _from、_from_uuid,即边起点的 _id、_uuid。 |
| 边终点 (TO) | 边的系统属性之一,有 _to、_to_uuid,即边终点的 _id、_uuid。 |
语法概述
UQL 的设计灵感来源于对图的深度理解,并结合了工业界对图的高维性、扩展性等需求。
链式表达 + 语义组装 + 别名调用
UQL 示例:
n({_id == "CA001"}).e({time > prev_e.time})[3].n(as target)
group by target.level with count(target) as quantity
order by quantity desc
return target.level, quantity limit 10
说明:
- UQL 的增、删、改、查功能是由风格为
[命令].[参数].[参数]…的 链式语句 执行的,即上面示例中的 n(... ).e(...)[3].n(...),一个 UQL 语句可以包含多个链式语句; - UQL 的查询结果通过 子句 进行加工和组装,即上面示例中的 group by ...,with ...,order by ...,return ...,limit ...;
- UQL 的查询结果通过 函数 进行运算,即上面示例中的 count(...),函数需要写在子句中;
- UQL 的各个链式语句、子句之间通过 自定义别名 来进行数据临时存储和传递调用,即上面示例中的 target、quantity,需使用关键词 as 先定义再调用;
- 模板内部可通过 系统别名
prev_n、prev_e来传递和调用数据,即上面示例中的 ...time > prev_e.time...; - UQL 语句中支持转义符
\、制表符\t、回车换行符\r\n以及注释符//、/*、*/。
UQL 设计逻辑:
- 清晰定义了点、边、路径、原子值、数组、表格等高级数据结构
- 可以查询获得上述数据结构中的一个或多个,并进行计算、返回
- 可以轻松描述图查询时的过滤条件,直接对接、适配高性能图计算引擎
- 链式表达、语义组装的语法结构,易读,易写,易学,与人脑思维模式保持一致
- 函数式风格更符合复杂的数据处理需求,可以提供无限的扩展空间
- 函数式风格允许用户自定义扩展语言语法特性,满足复杂图操作的需求
UQL 不使用 SQL like 作为基础的原因:
- 无法明确表达高维数据,以及其组合,如:路径,点,边,原子值,聚合运算结果的集合
- SQL 方式的路径查询过于复杂低效,如:路径搜索,模板搜索,图遍历
- SQL 阅读起来与人脑呈相反逻辑,理解难度大,如:嵌套语句,连表搜索等
UQL 语法特性
UQL 具备 DQL、DDL、DML、DCL 语法特性:
- DQL(Data Query Language):数据查询语法,如点、边、路径的查询;
- DDL(Data Definition Language):数据定义语法,如增删图集、修改 schema、定义属性、创建索引等;
- DML(Data Manipulation Language):数据操纵语法,如对图集的元数据等内容进行增、删、改;
- DCL(Data Control Language):数据访问控制语法,主要用于设置数据库的权限,如用户管理、角色管理、赋权与撤销等。
保留字 (Reserved Words)
创建 schema、属性、别名时需避免使用以下系统保留字:
| 分类 | 保留字 |
|---|---|
| 系统属性 | _id,_uuid,_from,_to,_from_uuid,_to_uuid |
| 系统表名 | _graph,_nodeSchema,_edgeSchema,_nodeProperty,_edgeProperty,_nodeIndex,_edgeIndex,_nodeFulltext,_edgeFulltext,_statistic,_top,_task,_policy,_user,_privilege,_algoList,_extaList |
| 系统别名 | this,prev_n,prev_e |
| 子句关键词(1) | in,nin,contains,xor,as,group by,order by,asc, desc,skip,limit,return,with,where, uncollect,union, union all,call |
| 函数关键词(1) | case,when,then,else,end |
| UQL 前缀(1) | exec task,explain,profile,debug |
| 链式前缀(1) | optional |
(1) 大小写不敏感的保留字