我的uql:
find().nodes() as nodes limit 10
optional n(nodes).e(as e1).n(as n1)
return case n1
when 0 then ["isolated"]
else [n1.age, n1.name] end
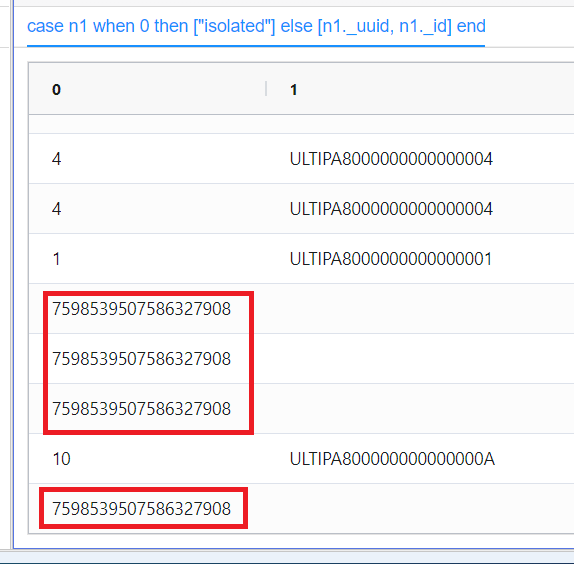
得到的结果是,所有 n1 为 0 的行都输出了 7598539507586327908 而非 isolated:
申请证书
证书详情
| ID | |
| 产品 | |
| 状态 | |
| 核数 | |
| Shard 服务最大数量 | |
| Shard 服务最大总核数 | |
| HDC 服务最大数量 | |
| HDC 服务最大总核数 | |
| 申请天数 | |
| 审批日期 | |
| 过期日期 | |
| MAC地址 | |
| 申请理由 | |
| 审核信息 |
用户邮箱:
当前未申请证书.
| Certificate | Issued at | Valid until | Serial No. | File |
|---|
| Serial No. | Valid until | File |
|---|
Not having one? Apply now! >>>
| ProductName | CreateTime | ID | Price | File |
|---|
| ProductName | CreateTime | ID | Price | File |
|---|
No Invoice
我的uql:
find().nodes() as nodes limit 10
optional n(nodes).e(as e1).n(as n1)
return case n1
when 0 then ["isolated"]
else [n1.age, n1.name] end
得到的结果是,所有 n1 为 0 的行都输出了 7598539507586327908 而非 isolated:
1 个回答
这是 TABLE 中同一列内的数据类型不一致造成的。
uql 语句中出现的形式为 [<element1>, <element2>, ...] 的内容会根据上下文解析为 TABLE 或 ARRAY。比如你语句中 then 后面的 ["isolated"] 和 else 后面的 [n1.age, n1.name] 就是 TABLE;再比如过滤器中的写法 {<alias> in [...] } 就是 ARRAY。
TABLE 和 ARRAY 均不要求其各行数组具有相同的元素个数,但 TABLE 要求各行数组在同一列内的数据类型一致。在你的 uql 中,["isolated"] 是长度为 1 的数组,第一个元素的类型为字符串,[n1.age, n1.name] 是长度为 2 的数组,第一个元素的类型为数字,这就出现了同一列内数据类型不一致的问题。
当 case 函数对数据列 n1 进行映射时,如果 n1 中的第一行被映射为 ["isolated"] ,则其后所有行的第一个值都按照字符串处理,如果 n1 中的第一行被映射为 [n1.age, n1.name] ,则其后所有行的第一个值都按照数字处理,第二个值都按照字符串处理。你的问题就是这里的第二种情况。
(ARRAY 既不要求各行数组具有相同的元素个数,也不要求各行数组在同一列内具有相同的数据类型。)