·电商网站:如淘宝、天猫、京东、Amazon……
·生活服务:如美团、饿了么、携程、小红书……
·视频:如抖音、快手、优酷……
·音乐:如网易云音乐、QQ 音乐……
·资讯:如今日头条……
·金融科技:理财产品……
一般来说,推荐算法的种类繁多,主要有基于内容的推荐,基于社交场景的推荐等等,以协同过滤算法[1] (Collaborative-based Filtering, CF)来说,这种方法是依赖于用户过去的行为,如用户收藏过的文章,购买过的商品,浏览某商品的次数等等。
协同过滤算法主要分为两类:
·基于用户的协同过滤算法:给用户推荐与其兴趣相似的用户喜欢的物品。
·基于商品的协同过滤算法:给用户推荐与其之前喜欢的物品相似的物品。
例如,某平台在某档期共上了4部电影:《八角笼中》《封神第一部》《碟中谍7》以及《长安三万里》。现假设,有一名用户 E 访问了该网站,推荐系统需要决定《碟中谍7》是否要推荐给用户 E 。
推荐系统可以利用的数据有,用户 E 对档期内影片的历史评价数据,以及其他用户对档期影片的历史评价数据。
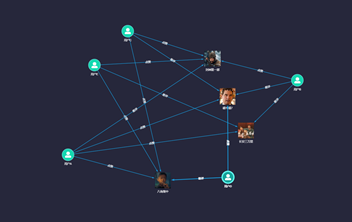
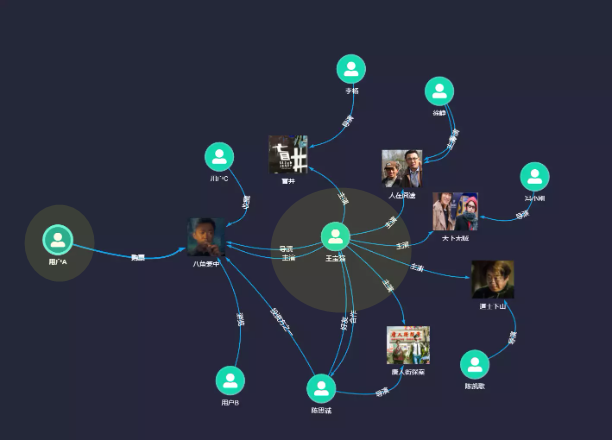
图1:在图中,用户、影片、评价,这三方是直观呈现的
在图1中,我们简单用“点赞”和“差评”进行表示,并且能直观地看出用户、影片和评价记录构成了带有标识的有向图[2] 。
接下来,为了方便计算,我们将图1转换成矩阵的形式(这个矩阵表示了物品共同出现的情况,因此被称为“共现矩阵”)。
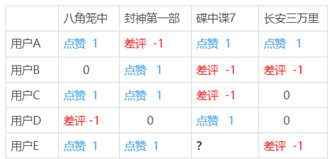
表1:将图转换为表形式
其中,影片作为矩阵行坐标,用户作为列坐标,我们再把“点赞”和“差评”的用户行为数据转换为矩阵中相应的元素值。这里,我们将“点赞”的值设为 1,将“差评”的值设为 -1,“无数据”置为 0。推荐问题就转换成了预测矩阵中问号元素的值的问题。由于在协同过滤算法中,推荐的原理是让用户考虑与自己兴趣相似用户的意见。因此,我们预测的第一步就是找到与用户E 兴趣最相似的 n 个用户,然后综合相似用户对“碟中谍7”的评价,得出用户E对“碟中谍7”评价的预测。见下图2。
-副本.png)
图2:协同过滤(Collaborative-based Filtering, CF)步骤
从上图/上表可以看出,用户B 和用户C 由于跟用户E 的行向量近似,被选为 Top n(这里假设 n 取 2)相似用户,接着在图 (e) 中我们可以看到,用户B 和用户C 对“碟中谍7”的评价均是负面的。因为相似用户对该影片的评价是负面的,所以我们可以预测出用户E 对该电影的评价也是负面的,于是,推荐系统就不会向用户E 推荐《碟中谍7》了。
协同过滤算法也存在着一些不足,除了冷启动问题(新用户、新标的物没有相关行为信息,这时系统怎么给用户推荐、怎么将新标的物推荐出去?所以在推荐系统的落地过程中,需要做结合业务场景的特殊处理,才能为用户提供好体验!)还有稀疏性的问题,尤其是那些用户基数大、标的物数量大,特别是资讯类或短视频类的物品,一般用户只对很少量的标的物产生操作行为,这时用户操作行为矩阵就是非常稀缺的,而太稀缺的行为矩阵,往往会导致计算出来的标的物相似度不精准,这就会影响到推荐结果的精准度了!
在图数据库中,除了可以通过编写UQL查询语句来实现较为简单的协同过滤,还可以使用嬴图提供的KNN(K Nearest Neighbor,K最近邻)算法直接实现上述的推荐运算,用户不需要任何的数据训练,就可以用自然语言的方式找到数据:
algo(knn).params({
node_id: '用户E',
node_schema_property: ['八角笼中', '封神第一部', '长安三万里'],
top_k: 1000,
target_schema_property: @user.`碟中碟7`
}) as result return result不仅如此,用户还可以通过嬴图Manager(高可视化前端管理平台)直观地看到查询结果,同时,所有步骤均可呈现(见下图)——这也是作为Graph技术区别于目前AI大模型工具黑盒化、不可解释的突出优势之一。
-副本.png)
图3:嬴图Manager 【如果你对高可视化感兴趣,可阅读:走进 嬴图Manager 之 高可视化系列文章】
从上图中,我们可以看到,图[3]是一种表示实体之间的复杂关系的高维呈现。【关于图知识,可点击图观 | 从电影《满江红》看图数据库的高维力或 嬴图的官方文档《嬴图快速入门—图数据的基本构成-技术篇》】
在智能推荐系统中,图技术可以解决传统方法的缺点和提升推荐系统的性能,利用各种算法构建推荐模型,提升推荐的精准度、惊喜度、覆盖率等,甚至是实时反馈用户的兴趣变化。
1、推荐精准度的问题
推荐精准度的问题,需要通过构建好的推荐算法来实现。在真实的应用场景中,常常会出现用户刚购买完一双皮鞋,但是系统后续又陆续推荐了很多双皮鞋给用户。而精准的推荐应该是系统将鞋塞、鞋拔、鞋刷、鞋油、鞋布等周边推荐给用户。还有诸如应用关联规则进行像“啤酒与尿布[4]”这样的将看上去毫不相干的商品进行关联陈列的算法,进而可以精准地通过强大的算法以辅助商超的工作人员,进行科学、洞察地对货架进行摆放并提升销售额。
推荐精准度的问题,一方面是需要通过构建好的推荐算法来实现(嬴图建有上百种的图算法库,这是目前全球范围内最丰富的图算法库);另一方面还有算力的问题,就是能将“海存”的数据进行“深算”的能力,即通过深度挖掘数据,将最终的推荐变成点石成金的关键!【感兴趣的读者可以详细阅读:高并发图数据库系统是如何实现的?】
此外,评估推荐算法的价值也很重要。如,推荐系统如何服务于业务?如何衡量推荐系统的价值产出?如何通过指标在提升推荐系统效果的同时促进业务发展?…… 这些都是摆在开发人员面前的重要问题。
2、大规模计算与存储的问题
大量的用户和大量的标的物,对数据处理和计算会造成非常大的压力,所以落地推荐系统的执行效果,其背后是非常考验企业搭建的大数据分析处理平台的能力的。
目前国内很多采用的是Hadoop、Spark等来做数据存储、处理、计算等,但务实地说,Hadoop生态中的解决方案,甚至包括Spark,动辄就会用几十台甚至上百台机器,实际上每台机器的利用率都十分低下——软件根本无法充分利用底层硬件的高并发、低延时能力。或许大家应该思考下,为什么有的人在多年前就说过“Hadoop已死!”【更多关于“Hadoop已死!”的话题,点击《关于开源和闭源的探讨(上)》阅读】
GraphX 是Apache Spark的图计算组件,支持PageRank网页排序、Connected Component联通分量、Triangle Counting三角形计算等非常浅层的计算,一旦涉及到例如全图K-hop、Random Walking随机游走、鲁汶社区识别等任何关于深层计算时就无能为力了。这也是“大规模分布式”系统的一个通病,对于浅层(短链)的存储、查询与算法可以较好去支持,但是一旦进入深度(长链)的查询、分析与计算时,效率就变的极为低下——因为深度关联分析意味着系统的多个实例间需要频繁的交互,进而导致效率大幅降低,反应时长大幅增加……直至无法返回计算结果。不知道那些在GraphX 之上做开发的厂家,是否能够突破GraphX的这诸多限制?【更多扩展阅读,可点击图数据库知识点4 | 图计算与图数据库有区别吗?】【图数据库知识点5:图数据库只存不算?】
3、实时的问题
推荐系统更新的时延,经常是以小时或天来衡量的(所以,如果给用户提供实时的个性化推荐,尤其对大规模用户要做到实时响应,需要实时收集、处理用户的反馈,做到更及时、更精准的推荐,为用户提供强感知的推荐服务……这对算法、计算、工程都是相当大的挑战!)嬴图可以实时(毫秒级-秒级)完成。
比如在一些依托工商图谱的审核、投研、行研等场景中,要查找上市企业或待上市企业实体与自然人之间的全部关联路径。假如4,000家企业与10,000个自然人之间进行全量计算,就需要查询40,000,000次最短路径,如果平均每对路径查询返回10条路径,全部结果有4亿条路径,即便是1条路径需要0.1秒,也需要2年的时间才能够完成计算,其计算复杂度可想而知。而数仓批处理的方式,根本无法及时完成这种面向海量数据的复杂查询,这个时候,只有实时图数据库(图计算)系统才能做到赋能客户以彻底解决算力不足的痛点。某大型金融行业客户通过使用嬴图高密度并发查询,实现了T+0(分钟级)完成以上所述的大规模批量查询,平均每组路径查询耗时仅0.1毫秒,较原使用的某知名美国图数据库系统的性能提升超过1,000倍。【更多扩展阅读,可点击文库 | 深“图”遍历挖出最终受益人】
注意,以下图为例,这是在一个百万-千万量级的点、边的图中(中等大小),而在Python或其它图计算系统中,这个过程通常都长达数个小时或者更久,甚至无法返回任何结果。
-副本.png)
图4:在图上通过高度并发而加速实现的鲁汶社区识别(实时或近实时完成) 来源:《图数据库原理、架构与应用》
在图5中,从全图中抽样了5,000个顶点来实时绘制它们所构成的鲁汶社区的空间拓扑结构关系,嬴图应用CRBR(Community Recognition Based Recommendation,基于社区识别的推荐),对全部商品(和用户)进行鲁汶社区识别(Louvain Community Detection),并按照用户的商品行为(浏览、购物车、购买等)进行分组等。先找到所有用户和商品所形成的紧密关联社群,然后再根据额外的信息来优化协同过滤的推荐逻辑,例如用户的属性信息、商品的分类信息等,通过嬴图计算引擎,以上操作可以以图模板搜索的方式实时完成,实时的用户行为、商品信息可以动态的插入或更新到图中。
-副本.png)
图5:在嬴图manager 上操作基于鲁汶的社区识别与可视化 来源:《图数据库原理、架构与应用》
还有基于图嵌入的推荐——GEBR(Graph Embedding Based Recommendation)。就图上的深度学习而言,这极有可能代表着AI发展的突破方向。【此处不展开,感兴趣的读者可以阅读嬴图的官方相关的文档——《可解释人工智能与图学习》】
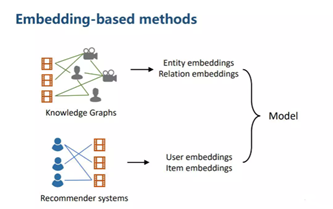
图6:图嵌入
此外,实现实时与直观的数据建模和深入的查询优化有着强关联关系。对此嬴图自研并创建了面向业务层的UQL图查询语言,它支持Demi-schema,更符合复杂的数据处理需求,满足复杂图操作的需求,可以轻松描述图查询时的过滤条件等优势,并与人脑思维模式保持一致,且易读、易写、易学。
这大大区别于传统SQL,比如其阅读起来与人脑呈相反逻辑,理解难度大,如嵌套语句、连表搜索等,还有SQL 方式的路径查询过于复杂低效,无法明确表达高维数据以及其组合,如路径、点、边、原子值、聚合运算结果的集合等。
UQL图查询语言的应用,在使用的效率上是飞跃性的,比如过去一名程序员要进行关联查询时,需要编写上百行的SQL代码,构造很多张临时表,进行大量的表连接操作,而用UQL,程序员只需敲一行代码即可轻松搞定。值得一提的是,图操作查询在现实中的意义也是非同凡响的,例如协助执法部门调查电信诈骗,传统大数据技术框架之上的多节点间数据组网、穿透操作极为复杂,无法做到实时反馈,而用UQL查询语言的自组网模式仅需毫秒,也就是我们一次眨眼的时间,即能实时找到嫌疑人之间错综复杂的关联罪证。
4、服务质量的问题
如果你的产品有大量用户访问,那么构建一套高效的智能推荐系统,满足高并发访问,为用户提供稳定、快速、高效、精准的推荐服务是一个巨大挑战,我们基于传统类型的推荐系统所存在的问题,将关于图的推荐系统优势列举如下:
· 实时推荐能力、实时数据刷新能力(传统痛点:推荐无法做到实时,需进行预处理);
· 计算存储能力(传统痛点:存储成本大,大量冗余数据侵占存储空间);
· 与知识图谱的无缝结合,例如商品知识图谱;(传统痛点:基于SOL二维表的低维性表达, 图具有高维性的构建能力);
· 推荐的高度智能化(而不是基于统计学计算模型的那种机器“智能”);
· 推荐图谱 = 实时商品图谱+用户360图谱,也就是说一站式推荐解决方案可以在图上实现!
最后,文尾鸣谢嬴图Wanyi Sun对本文在技术严谨表述上的指导与贡献。
文/ Emma Ricky
注释:
【1】协同过滤:就是假定相似用户有相似偏好,根据用户历史行为算出用户相似度,并用相似度加权平均其他用户的评分来预测该用户未打分物体的评分。
【2】有向图:当图中的边有明确的方向时,且在图中的各类操作可以利用这种方向的时候,我们称其为有向图。
【3】图
【4】啤酒与尿布:该故事发生在20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难以置信的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中。这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。在有婴儿的美国家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去毫不相干的商品经常会出现在同一个购物篮的现象。沃尔玛发现了这一独特的现象,开始尝试在卖场将啤酒与尿布摆放在相同的区域,让年轻的父亲可以方便地同时找到这两件商品,并很快地完成购物。
链接:


_1.png)
