近日,由DataFun主办的2023知识图谱峰会召开,学者孙宇熙受邀参加,并发表题为《图数据库查询与算法正确性验证》的演讲。
本次峰会共涉及六大论坛,包括统一知识表示与复杂推理、大规模知识图谱构建与更新、海量知识存储与计算、知识问答与推荐、知识图谱与AIGC、最佳行业知识图谱实践,共邀请20余位来自一线的知识图谱专家学者分享交流。
演讲全文
图数据库查询与算法正确性验证
导读
随着图结构数据在大数据、人工智能等领域的广泛应用,一个算法可靠的高性能图数据库也就成为了图数据探索、挖掘与算法应用的基石。然而,考虑到图结构数据的错综复杂与诸多变化,图算法计算的正确性校验本身就是一个难点,也是众多企业在图数据库技术选型时所面临的问题。在本次分享中,高性能实时图数据库嬴图的创始人孙宇熙,就为我们带来了嬴图团队在图计算结果正确性验证方面的经验总结与思考。
目录
· 图论与图计算的发展历程
· 图计算中存在的典型问题
· 图计算错误分析与验证示例
· 如何优化图计算算法
01| 图论与图计算的发展历程
图计算的数学基础图论最早脱胎于数学家欧拉于1836提出的哥尼斯堡七桥问题,到了上世纪80年代开始,图计算得到了快速的发展。在谷歌的PageRank、Web2.0 社交网络分析等领域都证明了图计算的强大能力。
而对应于存储图数据的图数据库反而出现较晚。图数据库的国际标准GQL要在2023年底或2024年出现正式的1.0的版本。
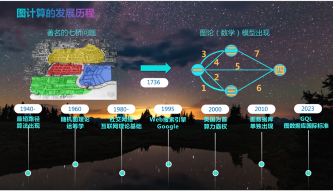
图1:图计算之发展历程
02| 图计算中存在的典型问题
在图计算的实际落地应用中,往往存在着一些常见的问题
1. 构图问题
在实际的业务应用场景中,图结构的定义与构建并不简单。
.png)
图2:单边图(简单图)& 多边图(复杂图)
例如:要为两个账户以及他们之间的一千笔转账交易关系构图,就存在两种解决方案。一种是将账户与转账都设计为节点,构建成一个包含1002个节点、2000条边的异构单边图。而另一种则是构建成一个包含2个节点和1000条边的同构多边图。其中,单边图往往在边的过滤能力上存在局限,且计算复杂度也会更高。
更广泛地来说,这就涉及到了如何把传统的关系型数据库中的结构化数据转化为图结构数据的问题。
在实际情况中,我们会发现,构图建模的方案并不唯一。而常用来构图的高维数据也会增加构图方案的多样性。在下面这个例子中,就表明了单边图与多边图在构图建模时的差异。
.png)
图3:关系型数据库(二维)VS.图数据库(高维)
同时,在构建多边图时,我们需要注意图数据库是否对边有足够强的处理能力;同时可以对边赋予权重、属性;可以在查询过滤时对点、边进行无差别的过滤。
同时,构图时的经验积累也非常重要,需要具备足够的工程经验,以便给出经过工程实践过的最佳构图方案。
2. 图计算框架与图数据库的区分
在实际的图计算应用场景中,往往同时会出现图计算框架与图数据库两种技术架构。在这里我们也需要对这两个概念加以区分。
图计算框架的出现要早于图数据库,主要着力于图计算算法的实现与优化。而图数据库则是一个处理图架构数据的“图计算系统”,包括了数据存取读写、算法计算、数据检验、可视化绘图的全面功能。因此,从功能上来说,图计算框架可以说是图数据库的一个子集。下表中就完整地对比了图计算框架与图数据库的差异。
.png)
表1:图计算框架与图数据库的区别
3. 图遍历问题
在图计算中,最基本的算法就是广度优先(BFS)和深度优先(DFS)两种遍历算法。这两种算法所提供的思路可以广泛应用于查询、社团识别、影响力等模型识别与归因分析。而不同的图数据库在基础算法的实践中其实也会存在差异。
.png)
图4:广度优先(BFS)与深度优先(DFS)是图计算的两种算法
4. K跳与K邻
在图论中,沿着一条边游走一个单位路径被称之为一跳(hop)。在对图中的顶点进行遍历时,就会涉及到多跳的问题。在图论中一段游走的路径就是多步跳(跃)的过程。如果用关系型数据库的语言来组织的话,这则是一个多重表连接 Join 的过程。
.png)
图5:图数据库的K邻与关系型数据库的多重表连接Join对比
定义了K跳就可以定义K邻(K-Hop):如果从顶点 A 到顶点 B 需要最少 K 跳,则顶点B 是顶点 A 的 (第)K 跳邻居。
.png)
图6:在图数据库中基于广度优先遍历的K邻查询
然而,图往往包含着更多复杂的结构与属性,例如:边的有向、无向;边的属性权重;k邻是否包含k-1邻;如何处理计算环路,等等。这些问题会导致K邻的实际计算也会存在差异。
此外,在一些实际场景中,图自身拓扑结构的变化;过滤条件的设定;节点、连边属性的变化都会影响到K邻计算的结果。
在了解上述概念与基本应用场景之后,就可以对图计算中的错误进行分析,并对计算结果加以验证。
5. 技术总结
相关技术算法可以简单地总结为一张图示:
.png)
图7:不同的路径查询算法
03| 图计算错误分析与 验证示例
1. 在有向图、多重边的图网络中做K邻查询
以上文提到的K邻计算为例,在一个有向图网络中,如果两个节点双向联通,就意味着两个节点之间存在两条方向相反的边。
.png)
图8:源数据中顶点关联的边(Twitter)
而在K邻查询时,这种关系的处理差异则会影响到结果的正确性。
.png)
图9:正确的K-Hop查询结果(4种查询方式 · Ultipa可视呈现结果)
而在数据库层面还是在应用开发层面去解决这个问题,也都会带来不同的效率性能上的差异。
2. 最短路径查询
最短路径也是一个典型的BFS搜索,在最短路径查询中,边是否具备权重、是否是有向边,都会对最短路径的查询结果带来影响。
.png)
图10:权重图举例
而且,在最短路径的结果返回中,我们需要给出路径上的全部节点。因为在实际的图算法应用中,如交易链条追踪就需要获知路径中的全部实体(节点)。
.png)
图11:有权、无权最短路径的计算过程
此外,最短路径还可以应用于股权穿透查询,如持股、投资查询。这些查询问题在投研和行研领域都极其重要。
3. Jaccard相似度算法
Jaccard(杰卡德相似度)是一种数学上非常简单的计算图上两个节点相似程度的算法,使用顶点与边进行表示。给定两个顶点邻居的交集除以并集:
.png)
而这一计算方式除了直接调用封装完备的算法之外,还可以通过前文提到的K邻查询的思路,以图查询的方法来实现这一问题。
在嬴图中,就支持以多种方式实现Jaccard相似度算法,且都能给出一致的结果。
4. 原因分析(错误类型)汇总
数据加载错误:数据加载不完整 ,例如,如果存在双向的边,但只加载了单向边,就会导致只能单向遍历的问题;另一方面,可能是因为底层存储数据结构的问题导致了数据本身就存在错误。
算法实现错误:1. 混淆了广度优先与深度优先算法,从而导致给出的是局部而非全局的结果;2. 不支持点、边属性数据的过滤,或者给出了错误的过滤结果;3. 代码实现错误也是常见的问题。
错误的应用导致的错误:考虑到图上算法的多样,图数据库的使用者调用了错误的函数接口也是一个常见的问题;使用者在对查询返回结果进行约束、进行统计时也会带来错误。
查询语言限制带来的错误:由于各个图数据库的查询语言并不一致,查询语言的歧义也会带来错误的结果。
有意(无心)为之的错误:技术的局限性也会带来不同的结果,例如处于性能的考虑将全局算法改为局部算法;或者接口的设计过于封闭限制了使用者调用算法的灵活程度。
04| 如何优化图计算算法
1. 图数据库开发实现层面
站在使用者的角度,我们可以对多种图数据库厂商实现的GQL语言进行对比。
.png)
图12:多种图查询语言之间的对比:Cypher VS. GSQL VS.UQL
从图中,我们可以直观地看到,嬴图的UQL(全称 ying Tu Graph Query Language,是通用图操作语言 GQL 的一种)查询语言的语法更为清晰,也更符合我们对图结构数据“点-边-点”的认知直觉。
此外,也不太可能有一个图数据库能支持全部主流的GQL语法——如果考虑到查询语法和图数据存储结构的关联,支持多种GQL语法往往是以性能的牺牲为代价的。
而图查询性能方面的优化可以分为以下几个方面的问题:
1、数据结构极大地影响着系统的性能,那么是什么数据结构支持最低成本的并发读(写)?
2、面对一个网络直径较大、度分布不均衡等特点的图网络时,如何实现实时高性能的递归算法?
3、在分布式计算中,网络通信成本和数据迁移的成本往往是不容忽视的,如何降低跨实例通信与协同的成本?
2. 编程语言与存储介质层面
数据库作为一个底层的信息系统,除了系统设计层面的问题之外,图计算加速优化的重要影响因素还包括:软硬件接口层面直接面向硬件处理器的指令集代码开发能力和对计算机多级存储资源的调度利用能力。
.png)
图13:高密度并发图计算 & 多级存储加速
以上就是今天分享的内容,谢谢大家。
分享嘉宾|孙宇熙
出品社区|DataFun