.png)
大家好,见字如面。我是教授老边。本专栏将基于我个人的观察,为大家带来关于图数据库技术的分享。从基础概念出发,深入剖析算法逻辑,分享实际应用案例,探讨市场现状,展望未来趋势,希望能为大家带来图相关知识,引发思考与启发。让我们一同踏上这场图数据库技术的探索之旅 。
2024年诺贝尔物理学奖颁发给了机器学习与神经网络领域的研究者,这是历史上首次出现这样的情况。这项奖项原本只授予对自然现象和物质的物理学研究作出重大贡献的科学家,如今却将全球范围内对机器学习和神经网络的研究和开发作为了一种能够深刻影响我们生活和未来的突出成果。比如,DeepMind开发的AlphaFold,它是一种革命性的人工智能(AI)系统,一举解决了过去50年都无法完成的蛋白质折叠问题,可以准确预测蛋白质的结构。

图1:世界上最有影响力的科学期刊Nature将其评价为:它将改变一切
在现实环境中,越来越多的商家、企业喜欢使用机器学习来增强它们对于商业前景的可预测性,有的采用了深度学习、神经元网络的技术来获取更大的预测能力。围绕这些技术手段,以下3个问题一直萦绕不断:
1、生态中的多系统间割裂问题(siloed systems within AI eco-system)|
2、低性能(low performance AI)
3、黑盒化(black-box AI)
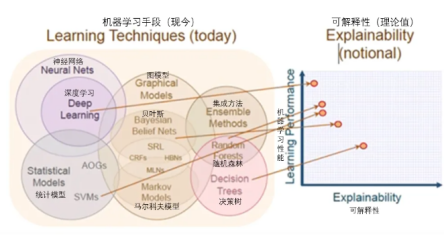
图2:AI机器学习技巧以及性能与可解释性
图2就很好地呼应了上面提到的3大问题。首先,机器学习的技巧很多,从统计学模型到神经元网络,从决策树到随机森林,从马尔科夫模型到贝叶斯网络到图模型,不一而足,但是这么多零散的模型却并没有一个所谓的一站式服务平台。大多数的AI用户和程序员每天都在面对多个相互间割裂的、烟囱式的系统——每个系统都需要准备不同类型、不同格式的数据、不同的软件硬件配置,大量的ETL或ELT类的工作需要完成。
其次,基于机器学习和深度学习的AI还面临性能与解释性的双重尴尬,所谓高准确率的深度学习往往并不具备良好的过程可解释性,这在各类神经元网络中体现得尤为强烈——人类用户作为最终的决策者是很难容忍过程不可解释、非白盒化的AI解决方案的。这也是为什么在欧洲、美国、日本、新加坡等地,金融机构、政府职能部门都在推动AI技术与应用落地时的白盒化、可解释性。
最后,性能问题同样不可忽视,数据处理、ETL、海量数据的训练和验证,整个过程是复杂和漫长的。这些问题都是不可忽视的存在。理想状态下,我们需要基础架构层的创新来应对并解决这些挑战。
图数据库恰好就是那个基础架构层的创新。我们在本文中会解读为什么和如何解决以上的问题。
传统意义上,数学和统计学的操作在图(数据集)上是非常有限的。在以前的文章中,我们也介绍过图数据结构的演进路线,感兴趣的读者可以翻阅。简而言之,在相邻矩阵或相邻链表类的数据结构中,很少的数学和统计学的操作可以被完成,在灵活性与性能上也存在很多挑战。为了在图数据集上可以支持更丰富的数学、统计学的计算与操作,引入向量型数据结构有其必然性与合理性,图嵌入也应运而生。
图嵌入是近几年来图计算领域中相当热门的研究方向,不仅仅是因为相当多的AI研究者把深度学习、神经网络的研究方向转为图嵌入、图神经网络,另一方面工业界也越来越多的发现结合图嵌入可以获得更好的反欺诈或智慧营销的效果。
对于图嵌入操作而言,这种底层的向量空间数据结构就是以嵌入的方式、原生图的方式存储图的基础数据(点、边、属性等),任何在此基础之上的数学、统计学计算等需求都可以更容易被实现。而当我们在数据结构、基础架构以及算法的工程实现层面做到了可以充分释放和利用底层硬件的并发能力的时候,在图上的很多非常耗时的图嵌入操作就可以非常高效和及时地完成。
举例来说,在一台双CPU的X86 PC服务器架构中,超线程数可达112甚至更高,也就是说如果全部100%并发,CPU最大并发规模可以达到11200%,而不是100%。遗憾的是,很多互联网后台开发程序员试图证明在不让一台服务器的最大并发能力充分释放(满负荷运转)的情况下,可以通过多机的分布式系统来实现更高的效率。高并发的正确打开方式是我们需要先把一台机器的并发能力释放出来后,才会以水平可扩展的方式去释放第二台、第三台的算力。
下面,让我们通过Word2Vec的例子来解释为什么图嵌入类的操作在嬴图数据库可以跑得更快,也更简洁(如轻量级存储、过程可解释)。Word2Vec方法可以看作是其他面向顶点、边、子图或全图的图嵌入方法的基础。简而言之,它把单词(word)嵌入(转换)到了向量空间——在低维向量空间中,意思相近的单词有相似的嵌入结果。著名的英国语言学家J.R.Firth在1957年曾说过:你可以通过了解一个单词的邻居(上下文)而了解这个单词。也就是说,具有相似含义的单词倾向于具有相似的近邻单词。
在以下三张配图(图3、图4、图5)当中,介绍了实现Word2Vec所用到的算法和训练方法:
·Skip-gram算法;
·Softmax训练方法;
·其他的算法,如Continuous Bag of Words、Negative Sampling(负取样)等。
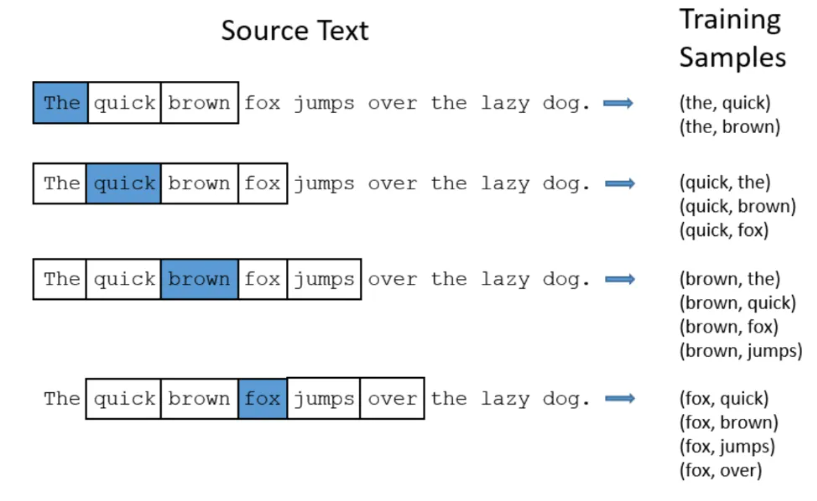
图3:Word2Vec从原文到训练采样数据集
图3中展示的是当采样窗口大小为2时(意味着每个当前关注、高亮的单词的前两个和后两个相连的单词会被采样),采集到的样本集的效果。
为了表达一个单词并把它输入给一个神经元网络,一种叫做one-hot的向量方法被使用到了,如图所示。输入的对应于单词ants的one-hot向量是一个有1万个元素的向量,其中只有一个元素为1(对应为ants),其它元素为全部为0。同样的,输出的向量也包含1万个元素,但是包含着每一个近邻的单词出现的可能性。
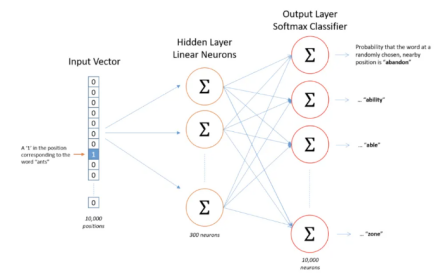
图4:Word2Vec神经元网络架构示意图
假设我们的词汇表中只有1万个单词(words),以及对应的300个功能(features)或者是可以用来调优Word2Vec模型的参数。这种设计可以理解为一个10 000×300的二维矩阵对应在隐藏层(hidden layer)中的300个神经元(neurons),如下图所示。
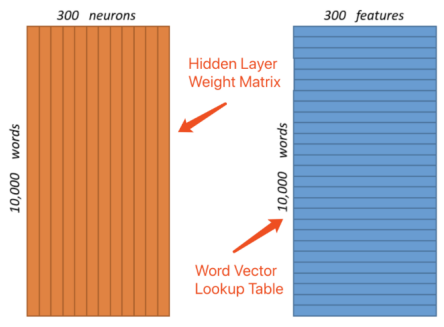
图5:巨大的单词向量(3 000 000种权重组合)
从上图看到,隐藏层和输出层都负载着权重达3 000 000的数据结构。对于真实世界的应用场景,词汇数量可能多达数百万,每个单词有上百个features的话,one-hot的向量会达到数以十亿计,即便是使用了sub-sampling、negative-sampling或word-pair-phrase等(压缩)优化技术,计算复杂度也是不可忽略的。很显然,这种one-hot向量的数据结构设计方式过于稀疏了,类似于相邻矩阵。同样地,利用GPU尽管可以通过并发来实现一定的运算加速,但是对于巨大的运算量需求而言依然是杯水车薪(低效)。
现在,让我们回顾Word2Vec的诉求是什么?在一个搜索与推荐系统中,当输入一个单词(或多个)的时候,我们希望系统给用户推荐其他什么单词?对于计算机系统而言,这是个数学——统计学(概率)问题:有着最高可能性分值的单词,或者说最为近邻的单词,会被优先推荐出来。从数据建模的角度来看,这是个典型的图计算问题。当一个单词被看作是图中的一个顶点时,它的邻居(和它关联的顶点)是那些经常在自然语句中出现在它前后的单词。这个逻辑可以以递归的方式延展开来,进而构成一张自然语言中完整的图。每个顶点、每条边都可以有它们各自的属性、权重、标签等。
我们设计了两种近邻存储的数据结构(相邻哈希,adjacency hash),如下图所示,表面上看它们类似于bigtable,但是在实现层,通过高并发架构赋予了这些数据结构无索引查询(index-free adjacency)可计算性能。
基于此类数据结构,Word2Vec问题可以被分解为如下两个清晰(但并不简单)的步骤:
1)为图中每个关联两个单词(顶点)的有向边赋值一个“可能性”权重,可以通过基于统计分析的预处理方式实现。
2)搜索和推荐可以通过简短的图遍历操作来实现,例如对于任何出发的单词(顶点),查询并返回前X个数量的邻居顶点。该操作可以以递归的方式在图中前进,每次用户选定一个新的顶点后,就会实时地进行新的推荐。当然也可以进行深度的图路径计算以实现类似于返回一个完整的、长句子的推荐效果。
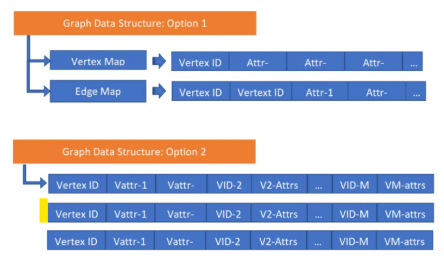
图6:原生支持图嵌入的图数据结构
第二步的描述非常类似于一套实时搜索与推荐系统,并且它的整个计算逻辑就是人脑如何进行自然语言处理的白盒化过程。
上面描述的就是一个完整的白盒化的图嵌入处理过程,每一个步骤都是确定的、可解释的、清晰的。它和之前的那种黑盒化和带有隐藏层(多层)的方法截然不同(参考图3、图4)。这也是为什么说深度的实时图计算技术会驱动XAI(eXplainable AI,可解释的人工智能)的发展。
相邻哈希数据结构采用图嵌入的方式构造——当图中的数据通过相邻哈希的结构被存储后,嵌入过程就自然而然地完成了,这也是相邻哈希类原生图存储在面向图嵌入、图神经网络时的一个重要优势。
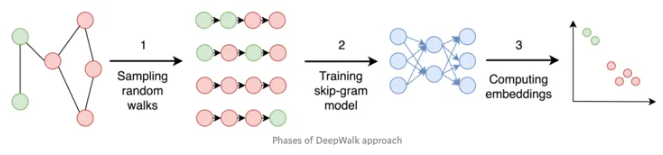
图7:深度游走(DeepWalk)的步骤分解
让我们来看第二个例子:深度游走(deep walk)。它是一个典型的以顶点为中心的嵌入方法,通过随机游走来实现嵌入过程。利用相邻哈希,随机游走的实现极为简单,仅仅需要从任一顶点出发,以随机的方式前往一个随机相邻的顶点,并把这个步骤以递归的方式在图中深度前行,例如前进40层(步)。需要注意的是,在传统的计算及IT系统中,通常来说每一层深入查询或访问都意味着计算资源的消耗指数级增加。如果平均每个顶点有20个邻居,查询深度为40层的计算复杂度为2040。
,没有任何已知的系统可以以一种实时或近实时的方式完成这种暴力运算任务。但是,得益于相邻哈希数据结构,我们知道每一层的顶点可以以并发的方式去访问它的相邻顶点,时间复杂度为O(1),然后每个相邻顶点的下一层邻居又以并发的方式被分而治之,如果有无穷的并发资源可以被利用,那么理论上的深度探索40层的时间复杂度为O(20*40)。当然,并发计算资源实际上是有限的,因此时间复杂度会高于O(800),但是可以想见,会指数级低于0(20 40)!
上图中示意的是典型的深度游走的步骤。利用相邻哈希,随机游走、训练和嵌入过程被降解为原生的图操作,例如K-邻和路径查询操作。这些操作都是直观、可解释的,也就是说是XAI友好的!
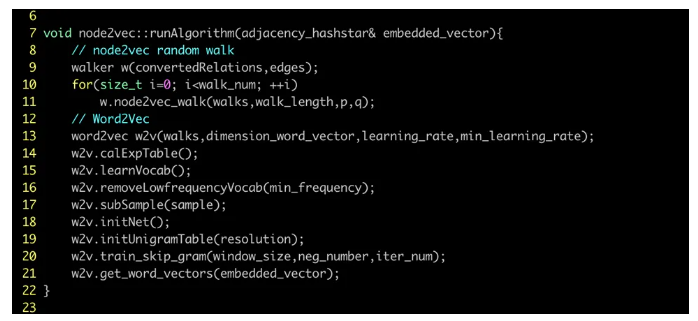
图8:node2vec算法步骤中对于word2vec的依赖
深度游走(DeepWalk)在学术界和业界经常被批评缺少通用性(普适性),它没有办法应对那种高度动态的图。例如,每个新的顶点(及边)出现后都要被再次训练,并且本地的邻居属性信息也不可以被保留。
Node2Vec被发明出来就是要解决上面提到的DeepWalk非通用性中的第二个问题。图7中展示了整个学习过程的完整的步骤——10步(含子进程),其中每个步骤又可以被分解为一套冗长的计算过程。传统意义上,像Node2Vec类的图嵌入方法需要很长时间(以及很多的资源,例如内存)来完成(用过Python的读者可能会更有体会!),但是,如果可以把这些步骤都进行高并发改造,通过高效利用和释放底层的硬件并发能力来缩短步骤执行时间,node2vec完全可以在大数据集上以近实时的方式完成。
以图9为例,如下的进程(步骤)都被改造为并发模式:
Node2Vec随机游走(random walks)
1、准备预计算Exp. Table
2、词汇学习 (from Training File)
3、剔除低频词汇Low-Frequency Vocabularies
4、常见单词(vectors)的Sub-sampling
5、初始化网络 (Hidden Layer, Input and Output Layers)
6、初始化Unigram Table (Negative Sampling)
7、Skip-Gram训练
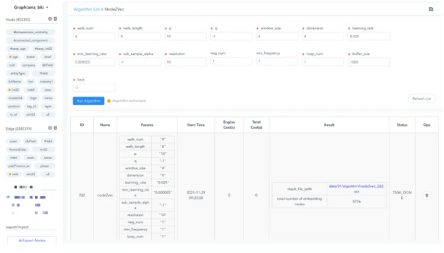
图9:中型图数据集上运行高并发node2vec算法
通过高度的并发实现,node2vec算法完全可以实现高性能与低延迟。在上图中,我们对增强的AMZ0601数据集运行node2vec,可以在完全实时的条件下完成以上列表中的全部操作。
值得指出的是:每一秒钟没有实现高并发的运算,对于底层的计算(或存储、网络)资源而言都是一种浪费——是对环境污染的一种漠视。还有其它的图嵌入技巧具有相似的理念和步骤,例如:
取样和标签(Sampling and labeling)
模型训练(i.e., Skip-Gram, n-Gram, and etc.)
嵌入计算(Computing embeddings)
有些计算需要在顶点或子图级别完成,有些则需要对全图进行运算,因此也会因计算复杂度的指数级增加而耗费更多的计算资源。无论是哪一种模式,可以实现以下的效果将会是非常美妙的:
在数据结构、架构和算法实现层面实现高性能、高并发;
每一步的操作都是确定、可解释的以及白盒化的;
理想状态下,每个操作都以一站式的方式完成(连贯的、统一的,无需数据迁移或反复转换的)。
现在,让我们回顾本文开头的地方,图2所触及的可解释性vs.性能的问题。决策树有着较好的可解释性,因为我们明白它每一步在做什么,树在本质上就是简单的图,但是它并不包含环路、交叉环路这种数学(计算)意义上复杂的拓扑结构——因为后者更难解释,当这种高难度的不可解释性层层叠加后,整个系统就变成了一个巨大的黑盒,这也是我们今天的很多AI系统所面临的真实的窘境——试问人类可以忍受一套又一套的AI系统在为我们服务的时候,始终以黑盒、不可解释的方式存在吗?例如通过AI来实现的人脸识别或者小微贷款额度计算,即便在10亿人身上经过认证它是准确的,你如何能确保在下一个新用户出现的时候它是准确的且公正的呢?只要人类不能精准、全面的回溯整个所谓的AI计算过程,这种风险就一直存在。不可解释的AI,注定是不会长久的,即便在一定时期内它可能还很火爆。不得不说,在XAI的方向上,有着巨大的IT系统升级换代的空间与机遇。
图是用来表达信息与数据的高维关联关系的,图数据库、图中台、图计算引擎是忠实的还原高维空间表达的终极方案。如果人脑是终极数据库,那么图数据库是迈进终极数据库的必然途径!



-副本-(Instagram帖子)-(7)_1.png)