图赋能的世界:
图的核心理念是用至为简单的顶点与边来表达任意复杂的关联关系。从上世纪60年代开始,由数学家欧拉开创的图论从纸上谈兵转为大量的实际应用与突破,尤其是近年来金融行业伴随着数字化、智能化的演进,涌入线上的海量数据亟待被充分挖掘、价值提取、洞察分析、实时决策……图计算、图数据库因算力强、算得快、效率高、穿透深、算得准等优势被越来越多地被运用到金融风险管理领域。
此外,区别于传统的关系型数据库的数据存储是以表来聚类数据,尤其是表的内容很多甚至发生多表关联的情况时,操作会造成因时耗过长、系统资源消耗过多而导致延时缓慢甚至无法返回的痛点,图计算、图数据库技术却可以通过高密度并发、深度穿透、动态剪枝等性能来充分地释放底层硬件的算力,实时高效完成深度穿透、挖掘和分析。换句话说,图计算就是更好地赋能各个行业并用来计算、查询的最佳工具。
随着大数据时代的到来,不仅数据量不断增长,而且数据的复杂性和多样性不断增加,越来越多的实时商业决策都依赖于对数据如何关联、相互关系、相关性的理解。传统的RDBMS数据库系统,不是为解决这一挑战而设计的,甚至更新的大数据框架也不是,他们可能有很好的可扩展性,但是往往不具备实时处理的能力。你可能认为我们首先会提到Hadoop缺乏实时性,并且认为基于分布式内存计算的Spark解决了这个问题。但是请继续阅读,笔者会向你展示嬴图如何与Spark在实时信用卡或贷款申请决策场景中进行比较。
1.扫描全部贷款或卡申请数据,找到被5个以上申请所共同使用的全部电话号码。
2.筛选整个申请数据中,所有共享如下任一信息的申请:公司,推荐人、邮箱或设备ID(电话号码、IP地址等)。
3.可以加强前面的筛选(过滤)规则,以使用AND,代替OR操作符,并找出多少申请共享了以上的的全部属性信息。
4.发现圈子。例如,申请#1使用手机#2,该手机被申请#3使用,该申请使用了邮箱#4,但是该邮箱也被应用程序#1使用。
5.应用程序[X]→手机→应用程序[Y]→邮箱→应用程序[X]。
6.这个场景是为了解是否存在一个5个节点(4条边)的循环。如果能进行更复杂的查询,则意味着更深/更长的循环路径,包含10个以上节点。
7.社区识别可以将申请人智能的分类到不同的社区(客群),这将有助于信用卡及贷款公司能更好地理解客户的行为模式。
要处理上述场景,我们必须首先考虑如何构造一个数据模型,来最佳地处理这些场景中的数据相关性需求。
2.申请的所有属性,如电子邮件、公司、设备、电话、ID#也分别作为节点。
上面的模式设计与传统表或列的SQL风格模式设计完全不同,当我们试图在找到任意两个申请的最短的相关性时,只需检查这两个应用程序是否共享一个公共属性节点,例如:电子邮件、电话、ID#、设备ID或公司。
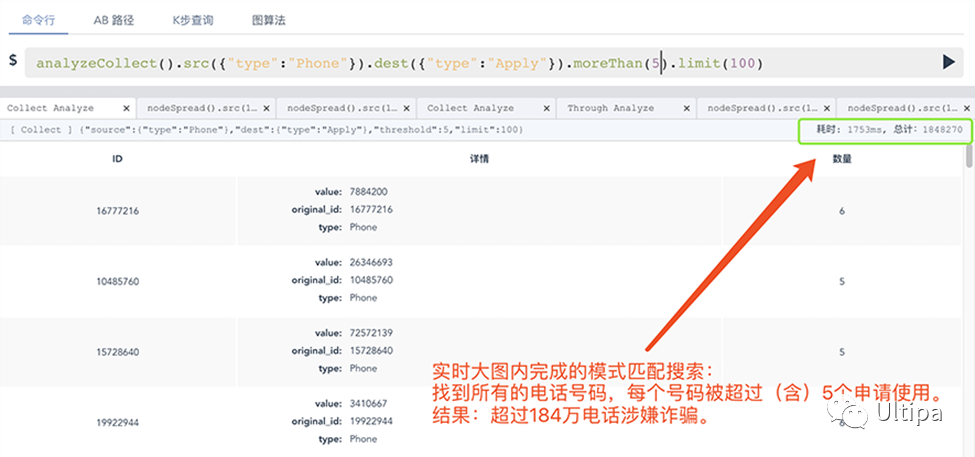
图1显示,在4亿多个申请和关联属性节点的数据集中,嬴图仅需1秒钟就可以识别出有超过180个电话号码被使用5次以上,而Spark系统至少需要13分钟才能返回,这是400-500倍的性能优势。除了性能优势之外,完成这个场景只需要一行图查询语言代码:
analyzeCollect().src({"type":"Phone"}).dest({"type":"Application"}).moreThan(5)
代码只需要一点点解释就可以理解:通过调用analyzeCollect()函数,从所有节点类型为“电话”的顶点出发,搜索结束节点类型为“应用程序”的顶点,并计算申请的数量以及对应的电话号码,并返回申请数超过 5的电话号码。结果是惊人的,有超过180万个电话号码被超过900万的申请重复使用,这些申请都可以被认作是潜在欺诈。
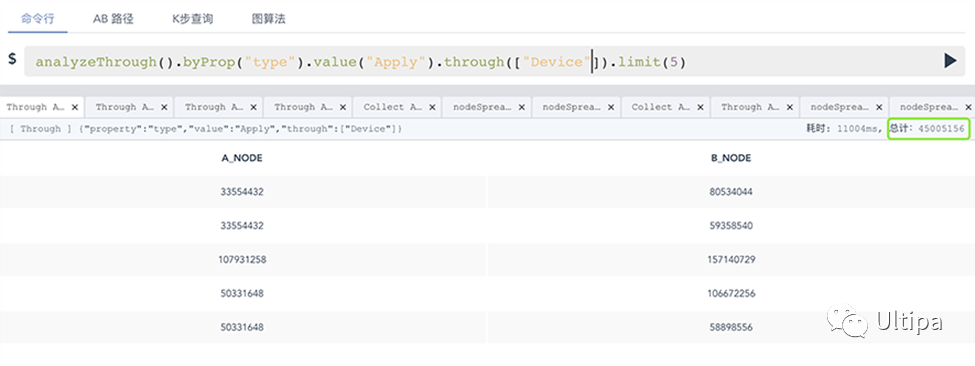
在第二个场景中(上面截图的第一部分),我们跑遍了整个数据集来找到共享同一设备的申请,这是一种常见的高风险或欺诈性识别案例,并发现有超过4500万申请存在此类问题。
场景三(图2中的下半部分),查询则更加严格,只有一对申请共享了所有相同的属性:设备ID、公司、电子邮件、推荐人、推荐人的申请ID。
上面的这个查询显然计算量要更大,通常被认为是大规模的批处理。在公有云环境中运行的Ultipa Graph实例需要大约40秒的时间返回,而Spark则需要一个多小时才能完成。
图3:场景4,通过路径查询来验证之前的批处理查询结果的正确性
为了验证上面的结果是否正确,只需在两个找到的节点之间运行一个路径查询,得到的子图在下图中显示。高亮显示的是两个申请共享了6个共同属性节点,如图3所示。
鲁汶(Louvain)社区识别是最近才加入图算法家族(在2008年发明)的。它通过对全图数据进行多次循环迭代收敛后形成了多个社区,紧密相连的数据会被分配在一个社区内,在社交网络分析、欺诈监测、营销推荐等多个场景中非常有价值。Louvain算法的挑战和缺点是,它的原始算法是串行的,一旦数据量变大(例如在百万量级以上),整个计算就会变得非常缓慢,如果你把它应用于反欺诈设置中,传统的解决方案可能需要数小时或数天来计算(或者根本无法完成)。在嬴图数据库中,Louvain被重构为以高度并发、内存计算的方式运行,其运行速度是传统串行实现的成百上千倍。另,在嬴图Manager中嵌入了一个高度可视化的内置Louvain DV模块(参见下一个图),让用户可以以可视化的直观、易懂的方式理解社区(客群)识别后形成的社区的空间拓扑结构、关联关系。
在许多场景中,我们看到以嬴图为典型的高度并行计算引擎能够比其他系统在性能上高出3-4个数量级(1,000到10,000倍)。
这里的要点是:高性能=高吞吐率=小集群规模=低TCO (Better Performance = Higher Throughput = Smaller Cloud/Cluster =Lowered TCO)。
下表是一个嬴图与Spark、Neo4j和Python之间的性能比较矩阵,测试数据集为上文场景中用到的2亿+个节点/边的大型贷款、信用卡申请图数据集:
|
|
Spark |
嬴图 |
Neo4J |
Python NetworkX |
|
|
780 秒 |
1.6秒 |
未测试 |
N/A |
|
OLAP 场景2/3
|
3600 秒 |
44 秒 |
未测试 |
N/A |
|
环路发现 场景4
|
N/A |
30,000 QPS |
10 QPS |
N/A |
|
鲁汶社区识别 场景5
|
N/A |
10-min(含磁盘回写时间)
|
未测试 |
无法完成(以周为单位如有无限资源)
|

.png)
.png)
.jpeg)



