.png)
大家好,见字如面。我是教授老边。本专栏将基于我个人的观察,为大家带来关于图数据库技术的分享。从基础概念出发,深入剖析算法逻辑,分享实际应用案例,探讨市场现状,展望未来趋势,希望能为大家带来图相关知识,引发思考与启发。让我们一同踏上这场图数据库技术的探索之旅 。
开门见山,标题里已经说了,有正确的评测方式,就有错误的评测方式。
来点儿细节,以小见大,篇幅所限,先讲几个点:
·只存不算的测试内容
·追求全行一张图的测试思路
·不求甚解的测试内容
以上三点,笔者稍微逐一展开。
第 1 点:只存不算
在之前的文章【图数据库只存不算?】中,我们已经touch-base了图数据库绝不能只存不算,否则,Hadoop 也能干你要干的存储的事儿。这是个关键的知识点:存(海量)数据这件事情,Hadoop的 HDFS(以及 inspire 它的GFS)早在20 年前就已经实现了。用分布式的多机、多节点的 IO 来并发写入,写入速度(吞吐率)可以接近硬件的极限,比如 SSD 上面~500MB/s的水平,1个小时可以写入 1.8TB,2 个小时 3TB。很快,对不对?!?
然而,这么快写入的数据,你可以拿它做什么?像很多数仓、数湖一样,一入湖仓即沉底,沉底就沉底?在这个上面你可以跑任何图查询的场景吗?显然不会。那么,测试存入这个海量数据的意义何在?证明一款图数据库是否有湖仓的潜力?这个逻辑说不通。
这就是目前有些 POC 测试中真实发生的荒诞场景,先测你能不能存它几个 TB 的数据、多快能存进去,然后转头没有任何后续的图查询、分析、计算的场景?这是什么操作?
有这类 POC 测试方案的,毫无疑问都是被至少存储层是基于 Hadoop 的 HDFS 逻辑构建的所谓的图厂家忽悠的。
分布式最大的优点在于能快速写入,但是其最大的不堪就是存入之后其无法快速进行关联计算与分析。因为写入的内容根本就和图分析无关,所谓非原生数据。想要计算,还需要再次数据迁移或者映射,这个速度会极慢,因此,这个“只存不算”的场景,是一种典型的误导!
第 2 点:一张大图
全局一张图、全行一张图,这个提法乍一听很猛,颇有点当年某G-SIB 提出的全行一张表的概念,当然一张表,得有多大、多宽、多长.…… 天知道。
无论以上哪种提法,都禁不起推敲。即便是在逻辑上,全行一张图的概念也是不准确的。除非我们忽略一切业务的特性、数据的特性、数据之间关联的特性等,或者是,在技术手段上无法支持多图的表达方式。
举几个例子:
·反欺诈场景中的构图就不止一种模式,比如单边图(简单图)和多边图(复杂图)就是截然不同的两大类构图方式,何来一张图可以包罗万象呢?
· 工商图谱和交易流水的图谱,在图结构上差异很大,尽管可以融合(通过 schema 来进行过滤区分),但是从业务逻辑上,并没有必要强行融合,为追求一张图而一张图。在物理与逻辑层面,区分开来反而更清晰简洁。
·业务部门之间的数据如果要物理隔离,每个部门一套自己的图数据、图系统显然更为合理——即便是在总行的最高视角,也没有必要去追求一张大图。
提出概念不难,但科技成果的落地,一定要视实际情况而定,审慎而为的,否则最终非常有可能烂尾。从 PMF(Product Market Fit)的角度,销售团队鼓吹的这个概念,均要由客户与 IT 来买单和承受后果的。别的不说,大图的查询性能,配合上只存不算的诡异组合,妥妥在抹黑图数据库——提出这类观点的人、团队或厂家,要么是没有做底层技术的基因,要么就是不懂——当然,没有基因也是不懂的意思。
第 3 点:不求甚解、漏洞百出
举几个例子,比如 K邻、K跳的测试方式:
到底是要第K 跳的结果还是从第1 到第 K 跳混在一起的结果?
你说哪种计算的复杂度更高(更准确)呢?
如果把第 1 到第 K 都混在一起,那么测试结果错误的概率很高,并且底层实现的代码逻辑很大概率也是错误的!
能直接返回某一跳结果的,当然可以返回第1—第 K 跳的聚合结果,但是反之并不成立。(用滥竽充数形容,最恰当不过!)
这里有一些技术细节:
1、实现方式是否严格按照广度优先遍历(BFS)实现?
2、是否进行全量计算(而非采样)?
3、是否进行了去重计算:里面还有两个细节,是否进行了逐层(跳)的去重;是否进行了跨层的去重?
这三个点,才是进行 K 邻查询时的关键!
如,到底是计算全量数据,还是采样计算?有的厂家竟然在 K 邻查询的时候,居然还有“阈值限定”这种骚操作。我们来剖析一下为什么要限定结果,因为:其系统无法全局遍历和计算,所以只能采样出结果。
首先,这个结果必错无疑,那么,为什么它要采样呢?还是要举个例子,尽管会让人尴尬..……
采样,是因为算力不够,为啥不够?很多原因,比如数据结构遍历起来太慢,来不及触达全量邻居;再如,分布式,邻居们早就被拆分的哪哪都是,只能随机采样,敷衍了事,否则 BSP (Bulky Synchronous Processing)系统的网络通信就会让这种分布式系统直接跪了(宕机)。还有,超级节点的存在,也让采样图数据库们很难受,某个顶点有 100万邻居的时候,即便是单机去计算其 2 度(跳)邻居也会非常有挑战。对于那些不清楚算法复杂度和高并发计算为何物的工程师而言——就这个地方能 1 秒钟完成K 邻计算,也算是基础扎实了——参考下图 1 秒可以完成 2-hop,意味着已经超越 Neo4j 了。真实的情况是,Neo4j 依然大幅快于、优于那些国产“皇帝数据库”们。
事实的真相在于,在这种深度查询条件下,水平分布式会更慢,不是慢 1—2 倍,是 10倍或更多,查询越深,慢的越多,1 层慢 10 倍,2 层慢 100 倍,3 层慢 1000 倍,以此类推。
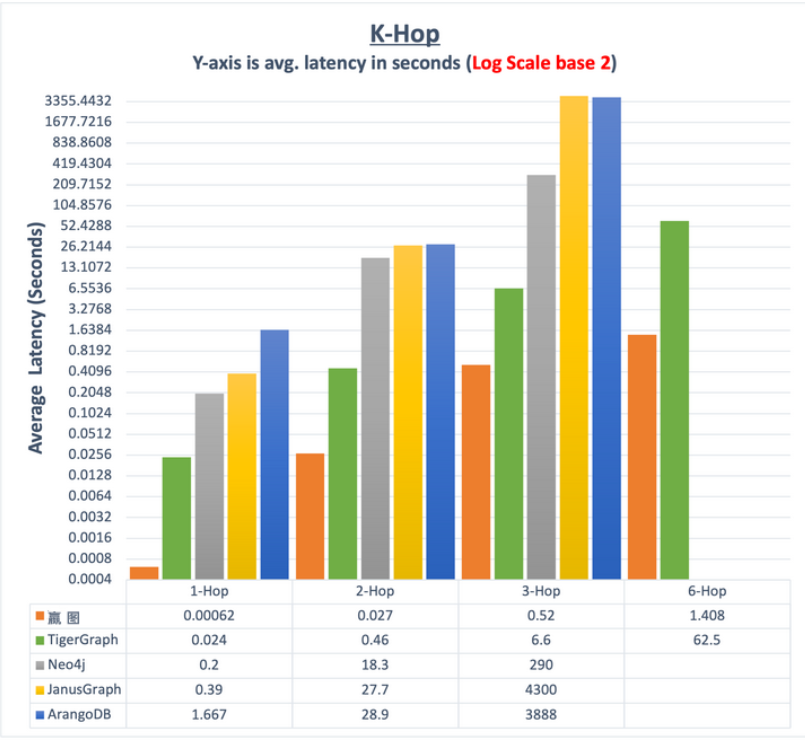
图:15 亿点+边数据集,大量超级节点,平均查询耗时
分布式也有优点,存得快,多几台机器,存得效率可以指数级上去,存入快 10 倍,甚至几十倍。然而,存得再快,还是算不动。抓不住矛盾的主要方面,就会选型上不靠谱的图系统!
关于图数据建模,这也是图数据库、图谱行业乱象丛生的一个高发地。这个知识点或许应该单独成文。
有几个观点简单分享:
1、建模方式应该多种多样,不会只有 1 种!
2、不同的建模方式,效率会有差异!计算难度也不同。
3、要根据具体的业务场景来灵活应对。
而不能支持多种建模方式的图系统,其局限性,可想而知。
比如,某知名图厂商,早年间从学术界出发,只知道两个顶点间只能有 1 条同类型的边。后来到了金融领域才发现,原来两个账户间可以有多条转账的关系…… 之前他们的做法是要把转账行为也作为顶点,无形中增加了很多无用的边——这种构图模式,应付反欺诈场景是可以的,但是其它更多的场景,无论是计算还是存储效率都不是最优的。后来,该厂商hack 了其底层,来支持多边图模式,但是底层积重难返,据说只能支持限定数据量的边。
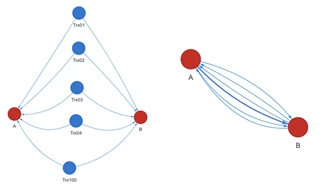
图:单边图 vs. 多边图
另一个更知名的厂商,是的,图数据库爱好者们可能多少都用过它家的社区版。为了支持 K 邻计算的加速,用了双向链表的数据结构,于是当出现超级节点的时候,哦,我的意思不是说 100 万邻居,而是 仅仅30 — 50 个邻居的那种,就可能会出现卡死的情况。
这两个例子说明什么问题呢?想改造底层,难度比上层应用改造大100 倍?说到底,和团队基因有关。如果做应用层的想下去做硬科技,其实是非常困难的,最终10个里面 9.5+个会悬羊卖狗。反之则不然。还有就是让二把刀们来改造底层数据结构,一定要多去雍和宫、潭柘寺、灵隐寺、南海观音、San Jose Pao-hua佛寺之类的地方多拜拜…… 奇迹兴许会出现。



_1.png)