.png)
大家好,见字如面。我是教授老边。本专栏将基于我个人的观察,为大家带来关于图数据库技术的分享。从基础概念出发,深入剖析算法逻辑,分享实际应用案例,探讨市场现状,展望未来趋势,希望能为大家带来图相关知识,引发思考与启发。让我们一同踏上这场图数据库技术的探索之旅 。
我们先来剖析下面这个问题:
图数据库查询(计算)和传统的关系型查询、大数据分析有什么不同?
假设我们有200个顶点,平均每个顶点有50条边与其它顶点产生关联,全图有5,000条边、200个顶点。如果我们去计算从图中任一个顶点出发抵达另外任意一个顶点的最短路径,理论上在这个高度联通的图上计算最短路径或最大K邻的计算复杂度是:
其中E为边的数量,V为顶点数量,K为两个顶点间最短路径的长度(或下钻的深度)。如果最短路径为4步,即K=4,那么该查询的计算复杂度约为25的4次方(约390,625)。
如果这张图等比放大1,000倍(5,000,000边,200,000顶点),同样的查询的计算复杂度并没有等比增加!
因为从扩增1,000倍后的大图中的某一个顶点出发,它的每一层的可遇见的邻居依然是平均只有50个,而|E/V|因为保持了一个相对恒定的比例,以上两点决定了在大图中的最短路径计算(也包含很多其它类型的查询或计算)复杂度并没有增长1,000倍,或许只增加了不到1倍或数倍——这就是图数据库的特点(这个时候跨越多实例的水平分片分布式系统查询的效率会显著低于集中式查询,两种架构面对这类查询的性能差异至少在100倍以上,查的越深,落差越大!)。
面向图数据的关联计算与查询的复杂度并不与全局的数据量成正比,而与具体的数据集的拓扑结构、查询逻辑、查询模式相关。
换言之,在数据量增加千倍的前提下,存储的需求显然会等比增加,但是计算的需求(复杂度)并不需要等比增加,因为图查询的复杂度与逻辑并没有随着数据量增加而产生等比变化——我们依然是在局部进行数据遍历!
因此,用固有的大数据的思维去套图数据库的计算逻辑很可能会产生南辕北辙的效果——也就是说图数据库所面临的挑战是计算优先而不再是存储优先——这句话也可以理解为:用作关系型数据库、数仓、数湖的思维去设计与实现图数据库一定会失败。但是失败的原因不一而足,或许我们需要明确的列出图数据库解决的问题有哪些。
图数据库解决的问题有哪些?
图数据库的设计有哪些坑?
2、分布式不是试图用多台低配的设备来取代高配的设备,并寄希望于可以获得更好的效果。毕竟(高性能的)图数据库系统不是用Hadoop的理念与框架可以实现的——如果你还停留在Hadoop时代,那么你的知识栈与认知需要一次升级了。
分布式系统设计最重要的理念就是审慎的决策哪些图计算的场景需要分片,哪些不需要分片,换言之,分片可以解决的场景是偏浅层的查询与计算,而深度计算的挑战与分片反向而行。
实际上在图数据库上构建分布式系统一直是个谜,很少有人想得清楚、讲得明白、做得出来。我们在这里做个简单的梳理,关于分布式的几种模式:
A. 分布式共识集群的单集群扩展模式:通过容器及License最大并发资源分配或底层硬件升级来实现; B. 分图扩展模式(即Fabric模式):多个小集群通过Nameserver来调度; C. 分片扩展模式(即Sharding/Federation模式):无限水平可扩展(图仓模式)。
3、计算机体系架构发展到今天,每一个单机、单实例的系统在底层都是一整套可以支持高并发、规模化并发的系统。
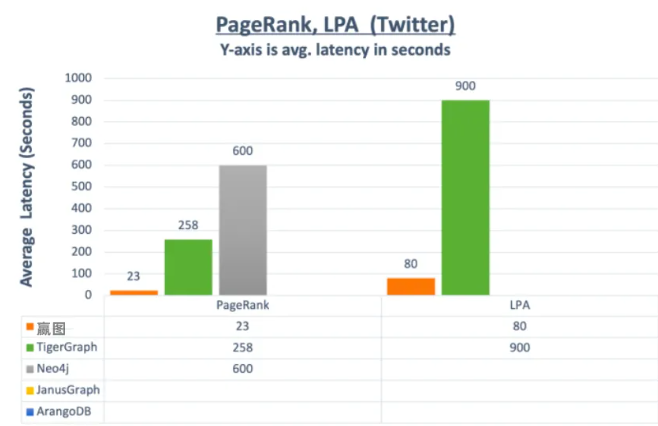
图2:PageRank与LPA算法的Twitter 15亿点边的数据集上的执行效率,可以看到嬴图的性能是其它厂家~10倍以上。图中的空白项表示无法完成运算并返回结果或宕机
4、数据结构的特征、效率决定了数据库系统的最终效率,或者说是系统效率的上限。只有在边界条件下才能看到一个系统真正的能力边界,对于图系统而言,判断它的能力边界有很多条路径,略举几个例子:
A. 数据加载,不要只看本地加载,还要看线上、远程加载大量数据的能力——因为这样显然更能模拟真实的企业生产系统环境;
B. 数据更新,需要检验一套图系统的逐条数据更新、批量数据更新(例如每天),全量数据更新的能力;
C. 数据查询与计算的能力:在性能评测和POC时,最容易遇到的就是数据或查询结果造假的问题,有些厂家会用预先计算并缓存结果的方式作弊。这个时候,可以要求实时更新数据集,并立刻查询同时比较更新前后的查询结果变化——如果没有变化,就是作弊或者系统没有能力进行实时更新与实时查询;
D. 算法支持能力:图算法是任何一款图数据库中都很重要的能力,不仅要看支持算法的数量多少,还要看具体的每个算法的调用方式、调参方式、返回方式是否灵活多样,是否支持可视化、同步异步返回等调用模式,以及算法结果的准确性!
E. 工具链条:DBA、开发人员,甚至业务人员可以使用工具的丰富程度与具体的使用体验是一个(图)数据库是否趋于成熟的典型标志——通常一款身经百战的数据库的工具链条都会比较完整,也更容易在上面做二次开发。
F. 准确性校验:这一条是很多厂家与客户都会忽略的地方。因为图的高维性,很多查询的结果校验经常被忽略。但是通过良好的可视化-表单化查询工具、交互式帮助文档是可以赋能用户快速的地对任何查询或算法的结果进行校验,这一点至关重要。

图3:越高级的语言的数据处理效率越低,这本来就属于常识的废话
不过,关于编程语言的探讨点到为止,有兴趣和能力的读者可以做一些充分的性能评测来感受一下效率差异之巨大。想了解具体技术原理的朋友可以参考嬴图分享出来的文章《高密度并行图计算(HDPC)》²。
6、(图)数据库系统的开发需要对操作系统、文件系统、存储、计算、网络等诸多组件的深入理解。在笔者看来,学界理论结合日常的工程实践是非常必要的,一方面避免闭门造车,另一方面能快速实现工程上的调优。举两个简单的例子:
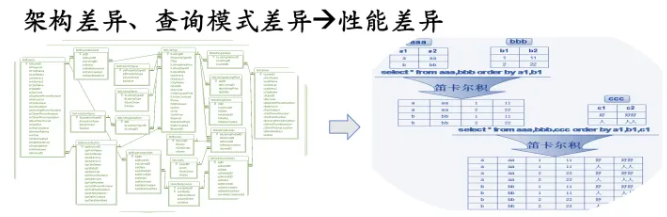
图4:关系型数据建模受限于二维表、多表关联查询模式可能产生的笛卡尔积等是SQL面临的主要问题
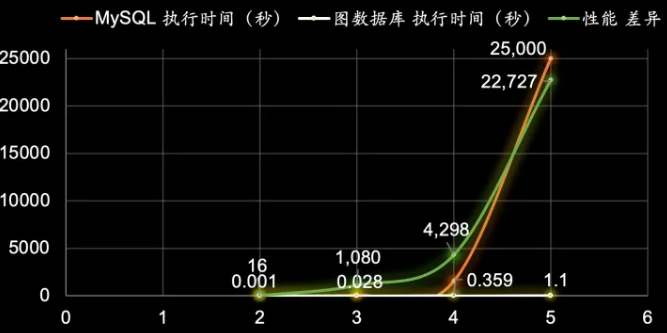
图5:随着查询深度增加,图数据库相比关系型数据库的查询效率落差逐级增大
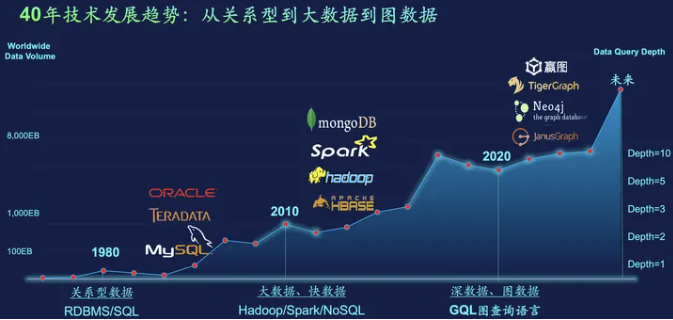
图6:过去40年来,数据处理技术的发展趋势是从关系型到大数据再到图数据
过去四十年间,数据处理技术发展的趋势就是从关系型到大数据再到图数据(深数据)。不但数据量在不可逆的变大,查询深度(关联复杂度)也在随之增加,而已经有近半个世纪的SQL终将逐步消亡。且,GQL作为继SQL(数据库行业的第一个标准)之后的国际标准已发布,我们可以看作它的出炉将是图时代的标志,同时也预示着这将加速SQL系统与负载向GQL的迁移,当然,这其中将有大量的业务场景会迁移到图数据库之上——这种迁移从实操成本上考量,一定是先迁移创新型的增量场景,然后才会逐步下沉并迁移到已有场景。


_1.png)
