✓ 文件回写 ✕ 属性回写 ✓ 直接返回 ✓ 流式返回 ✕ 统计值
概述
杰卡德相似度(Jaccard Similarity)也称为杰卡德指数(Jaccard Index),由 Paul Jaccard 于 1901 年提出,用于度量两个集合数据的相似性。在图中,收集节点的邻居节点作为邻居集合,两个节点的邻居集合越相似,这两个节点就越相似。
杰卡德相似度的取值范围 0 到 1;1 意味着两个集合完全一样,0 意味着两个集合没有任何共同元素。
基本概念
杰卡德相似度
已知集合 A 和 B,它们之间的杰卡德相似度可表示为:
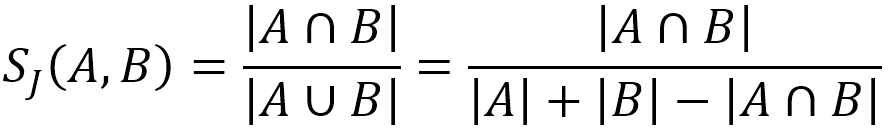
在下面的例子中,集合 A = {b,c,e,f,g},集合 B = {a,d,b,g},它们的交集 A⋂B = {b,g},并集 A⋃B = {a,b,c,d,e,f,g},因此它们之间的杰卡德相似度为 2 / 7 = 0.2857。
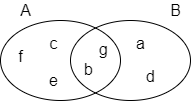
邻居集合
在 Ultipa 的杰卡德相似度算法中,收集两个目标节点的邻居集合用于计算其相似度时需注意以下几点:
- 邻居集合中没有重复的节点;
- 忽略自环边;
- 忽略两个目标节点之间的边;
- 忽略边方向。

上图中,当计算节点 u 和节点 v 间的杰卡德相似度时,它们的邻居集合分别为 Nu = {a,b,c,d,e} 以及 Nv = {d,e,f},它们的杰卡德相似度为 2 / 6 = 0.3333。
在实践中,为了计算基于共同邻居的相似性指标,就像杰卡德相似度,有时可能需要将一些点属性转换为点 Schema。例如,当考虑两个申请之间的相似性时,申请的电话号码、邮箱、设备 IP 等信息可能是存储为 @application 类型的点的属性的。如果要使用这些信息来度量相似性,则应将它们设计为节点加入图中。
语法
- 命令:
algo(similarity) - 参数:
名称 |
类型 |
规范 |
默认 |
可选 |
描述 |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | 否 | 待计算的第一组节点的 ID / UUID |
| ids2 / uuids2 | []_id / []_uuid |
/ | / | 是 | 待计算的第二组节点的 ID / UUID |
| type | string | jaccard |
cosine |
否 | 相似度衡量指标;计算杰卡德相似度时,保持此项为 jaccard |
| limit | int | >=-1 | -1 |
是 | 返回的结果条数,-1 返回所有结果 |
| top_limit | int | >=-1 | -1 |
是 | 限制 top_list 的长度,-1 返回完整的 top_list |
本算法有两种计算模式:
- 配对:同时配置了
ids/uuids和ids2/uuids2时,将第一组与第二组中的节点两两配对(笛卡尔乘积),逐对计算相似度。 - 选拔:仅配置
ids/uuids时,对于每一个节点,计算其与图中其他所有节点的相似度,目的是选拔与其最相似的节点,返回的top_list包含所有与其相似度大于 0 的结果并按相似度降序排列。
示例
示例图如下:
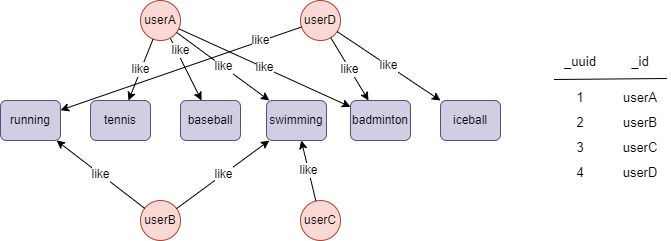
文件回写
| 计算模式 | 配置项 | 回写内容 |
|---|---|---|
| 配对 | filename | node1,node2,similarity |
| 选拔 | filename | node,top_list |
algo(similarity).params({
ids: "userC",
ids2: ["userA", "userB", "userD"],
type: "jaccard"
}).write({
file:{
filename: "sc"
}
})
结果:文件 sc
userC,userA,0.25
userC,userB,0.5
userC,userD,0
algo(similarity).params({
uuids: [1,2,3,4],
type: "jaccard"
}).write({
file:{
filename: "list"
}
})
结果:文件 list
userA,userC:0.250000;userB:0.200000;userD:0.166667;
userB,userC:0.500000;userD:0.250000;userA:0.200000;
userC,userB:0.500000;userA:0.250000;
userD,userB:0.250000;userA:0.166667;
直接返回
计算模式 |
别名序号 |
类型 |
描述 |
列名 |
|---|---|---|---|---|
| 配对 | 0 | []perNodePair | 各点对及相似度 | node1, node2, similarity |
| 选拔 | 0 | []perNode | 各点及其选拔结果 | node, top_list |
algo(similarity).params({
uuids: [1],
uuids2: [2,3,4],
type: "jaccard"
}) as jacc
return jacc
order by jacc.similarity desc
结果:jacc
| node1 | node2 | similarity |
|---|---|---|
| 1 | 3 | 0.25 |
| 1 | 2 | 0.2 |
| 1 | 4 | 0.166666666666667 |
algo(similarity).params({
uuids: [1,2],
type: "jaccard",
top_limit: 1
}) as top
return top
结果:top
| node | top_list |
|---|---|
| 1 | 3:0.250000, |
| 2 | 3:0.500000, |
流式返回
计算模式 |
别名序号 |
类型 |
描述 |
列名 |
|---|---|---|---|---|
| 配对 | 0 | []perNodePair | 各点对及相似度 | node1, node2, similarity |
| 选拔 | 0 | []perNode | 各点及其选拔结果 | node, top_list |
algo(similarity).params({
uuids: [3],
uuids2: [1,2,4],
type: "jaccard"
}).stream() as jacc
where jacc.similarity > 0
return jacc
结果:jacc
| node1 | node2 | similarity |
|---|---|---|
| 3 | 1 | 0.25 |
| 3 | 2 | 0.5 |
algo(similarity).params({
uuids: [1],
type: "jaccard",
top_limit: 2
}).stream() as top
return top
结果:top
| node | top_list |
|---|---|
| 1 | 3:0.250000,2:0.200000, |