“即使我感觉自己已经掌握了很多图查询命令,但当我开始进行图建模时,我还是感觉自己像个矮子。”
这是我们的一个客户在着手从之前习惯使用的关系型数据库切换到图数据库时所发表的感概。这位客户所述并非孤例,因为在图数据库的广袤世界中,很多初学者都曾历经此种滑稽境地。
当我们给图数据库新手做学习建议时,通常会强调查询语言的重要性。但在实际应用中,大多数用户的第一个难关并不在于如何编写查询语句,而是如何将数据顺利迁移到图数据库——特别是从传统的关系型数据库切换到图数据库。
当用户手上握有上百个字段分布在数十张关系表中时,数据迁移的任务无疑是一项相当艰巨的工程:
- 节点和边的不当区分
数据表的命名常常会倾向于将所有表都呈现为真实世界中的不同实体类型,这将会导致用户在试图区分哪些表代表真实实体,哪些表代表这些实体之间的关系时感到困惑。
- 模式[1]中存在过多的冗余属性
“冗余字段”的概念旨在解决SQL表JOIN查询的低效率问题。由于这一概念在很多用户的头脑中根深蒂固,使得删除或替换这些字段变得极具挑战性,尤其是在进行图数据的设计时。
- 重构表结构时缺乏大胆性
表结构的修改迭代往往需要历经多个轮次,最终获得的图模型有时会与原始表格结构大相径庭。而很少有初学者敢于对表结构做出大刀阔斧的改变。
黄金定律
无论用户手中的数据是否以表的形式存在,它们在很大程度上都无法直接转化为图数据。图数据有着基本的要求:如果是点,那么它必须拥有一个ID,这个ID就像是它的身份证,唯一标识着它的存在;如果是边,那么它必须有一个FROM和一个TO,这两者的取值都必须是图中某个点的ID。只有这样,我们才能够说:“啊,边真是个奇妙的桥梁,能把点和点连接起来!”。
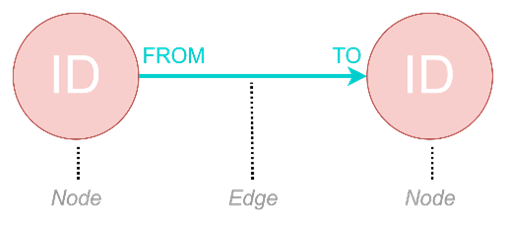
关于点ID和边FROM、TO的示例
如果真有所谓的黄金定律能帮助我们顺利地把表变成图,那就是:“充分关注原始表中的主键和外键”,因为它们将成为节点的ID以及边的FROM和TO,是成功得到图数据的关键。
让我们以一个实际案例为例,介绍如何从一个使用SQL Server搭建的医院信息管理系统出发,逐步将其表结构改造为图模型,并将获得的图数据导入到嬴图系统中。
SQL Server建表
这个简单的医院信息管理系统可以记录医生、患者、科室、病床的基本信息,追踪医生的接诊情况以及患者的住院记录。所有数据通过以下六张表来存储:
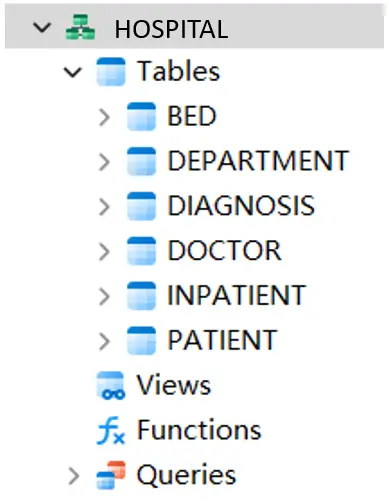
医院管理系统的表结构(SQL Server)
这些表的字段设计如下:
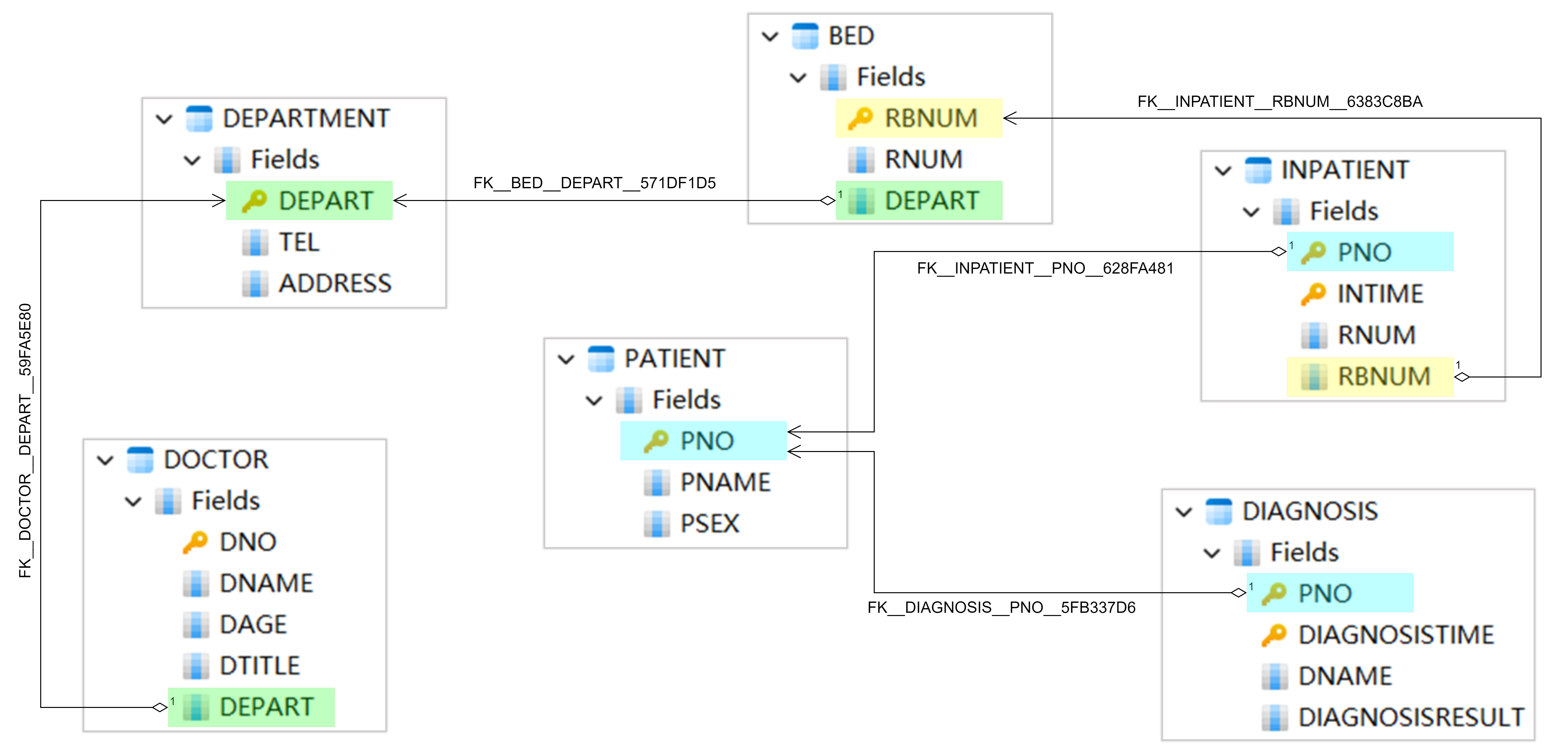
表之间的引用关系(从外键到主键)
如上图所示,由外键指向主键的箭头线既表达了表之间如何相连,也体现了SQL是如何进行表间关联查询的。比如,当我们想要查询某医生在特定时段内接诊的病人的姓名、性别以及诊断结果时,就可以依靠表DIAGNOSIS和表PATIENT之间的字段PNO进行关联,通过这个关联,我们能够找到我们需要的信息。对于具备SQL经验的读者来说,这种表连接查询应该是家常便饭了。
不过,上述表结构设计也存在一些不完善之处。比如,在表DIAGNOSIS中记录的是医生姓名DNAME,而非医生工号DNO。这个设计瑕疵导致了一个外键的遗漏,使得表DIAGNOSIS无法与表DOCTOR建立关联,无法获取关于医生的详细信息。当然,我们可以在表DIAGNOSIS中添加一些常用的医生信息,比如科室名DEPART,以此来规避关联查询带来的麻烦。然而,这种冗余存储所带来的磁盘占用、数据一致性校验等问题同样不容忽视。
在设计图数据库模型时,我们将不再受制于这种存储纠结。
我们将一些测试数据插入到前面所介绍的表中,为了节省篇幅,把所有表的内容整合到一起就得到如下结果:
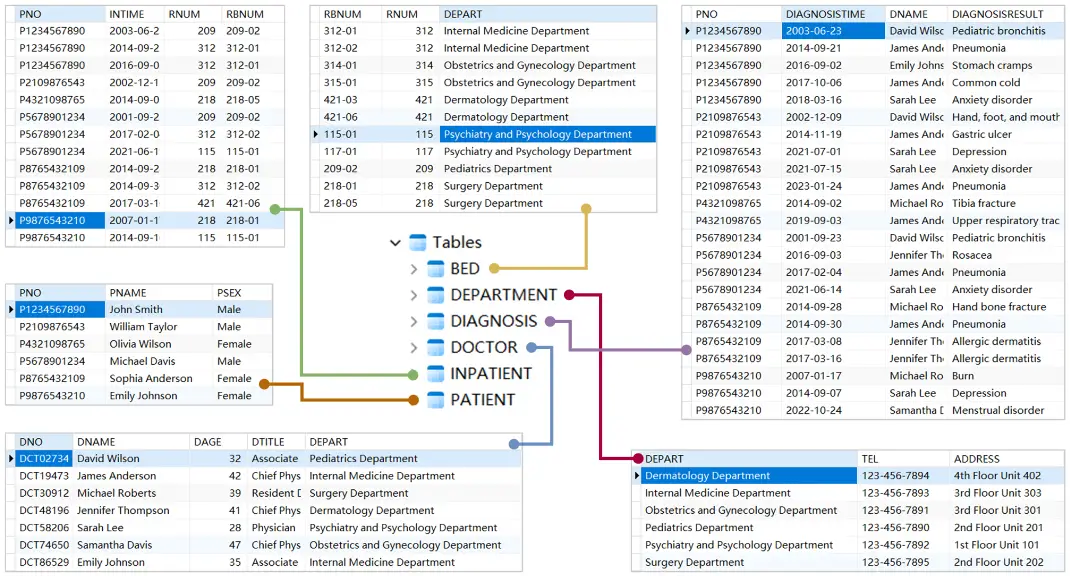
医院管理系统所有表的全部数据
不可否认,表数据的呈现方式虽然机械,但其详尽的列表形式可以让每个字段都一目了然。然而对于数据之间究竟发生了什么,比如“哪个科室的医生诊治了哪个病人”、“哪个病人入住了哪个科室的哪个病房”,这种直观性展示在表数据中就难以体现了。与即将构建的图数据相比,这种差异将格外明显。
在嬴图中构图
图模型的设计绝不是一蹴而就,让我们先来“抄作业”:把每一张表都定义为schema,每个字段都定义为schema的属性。接下来的挑战是如何区分点、边。
从某种意义上讲,所有的表都可以被视为真实世界中的某种实体,但只有最地道的实体才适合作为节点,因此我们只选取了DEPARTMENT、DOCTOR、BED、PATIENT作为节点,并将他们的主键作为节点的ID(用 _id 表示):
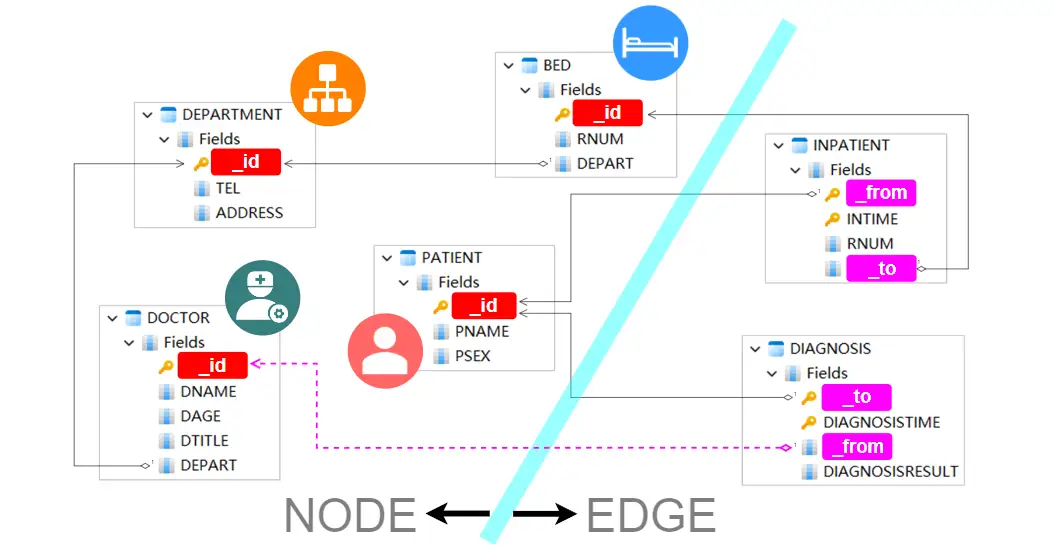
点、边划分
对于表INPATIENT,请不要将其误认为PATIENT的一个子集,因为它本质上记录的是病人和病床之间的关系,这从它具有两个外键、分别指向了表PATIENT和表BED就能看出。所以我们将INPATIENT定义为边,并将这两个外键定义为边的FROM和TO(用 _from、_to 表示),代表边的起点和终点。
(边的FROM和TO可以酌情对调,只要边的含义说得通即可。如,当FROM代表PATIENT的ID、TO代表BED的ID时,边表示“病人入住病床”,反之则边表示“病床接收病人”。)
按照同样思路,我们将DIAGNOSIS也定义为边,因为它记录了医生和病人之间的关系。在定义FROM和TO时,由于原始表只有一个指向PATIENT的外键,缺少指向DOCTOR的外键,所以需要手将这个遗失的外键补齐。这一外键缺失的问题在之前介绍表结构时已经分析过了,现在在边的设计中得到了纠正。
不难看出,点、边划分的关键在于确定点的ID以及边的FROM和TO,点的ID选取原表的主键,边的FROM和TO则选取原表的外键(如缺少则先补充外键)。这便是我们在一开强调“充分关注原始表中的主键和外键”的原因。
有些好奇宝宝会问:“边有没有ID呢?”答案是:当然可以有了。事实上,我们通常也是把划分为边的表的主键作为边的ID,这一逻辑和点ID的选取是相同的。我们不强调边的ID,是因为对于边来说FROM和TO是更为重要的。
当前所得的4个点模式和2个边模式充分利用各自表中的主键和外键定义了点的ID和边的FROM、TO。然而,在原始表中还有两个外键未使用,分别是表DOCTOR和表BED的外键DEPART,它们都指向了DEPARTMENT的主键。那么,我们应该如何处理这些被划分为点的表的外键呢?
一个简单的方法是将这些外键定义为新的边。如下图所示,我们引入了两种新的边模式:WORKAT和BELONGTO。这种设计看起来就像是在原来的表结构中新增了两张表,它们分别有两个外键,这些外键最终指向DOCTOR、BED和DEPARTMENT:
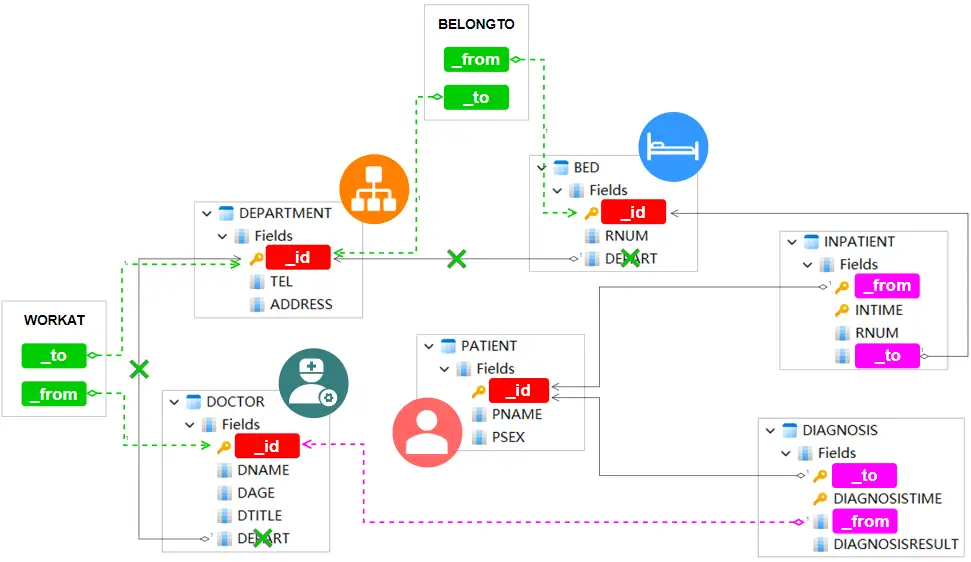
引入新的边模式WORKAT和BELONGTO
在引入WORKAT和BELONGTO之后,我们就可以将表DOCTOR和表BED的外键DEPART移除了。这两种新的边模式中除了FROM和TO之外就没有其他属性了,当然如果需要的话,也是可以添加更多属性的,比如医生在某科室工作的起止日期、某床位隶属于某科室的起止日期1等,这样就可以满足实际情况中的医生调换科室、病床转移科室等需求。当然与这些实际情况相对应的原始表的结构也会和本文使用的例子有所不同。
至此我们已经处理了表中所有的主键和外键,似乎已经完成了从表结构到图结构的转化。然而,仔细回顾病床的表字段会发现,其中还有个记录病房号的字段RNUM。虽然它只是一个房间号,但它代表的是病房这种实体。在医院管理中,有时需要统计病房的占用情况,或者管理病房的设施分配等,这些都要求病房被视为一种独立的实体。为了满足这个需求,我们将病房独立拆分为一个新的点模式,称之为ROOM:
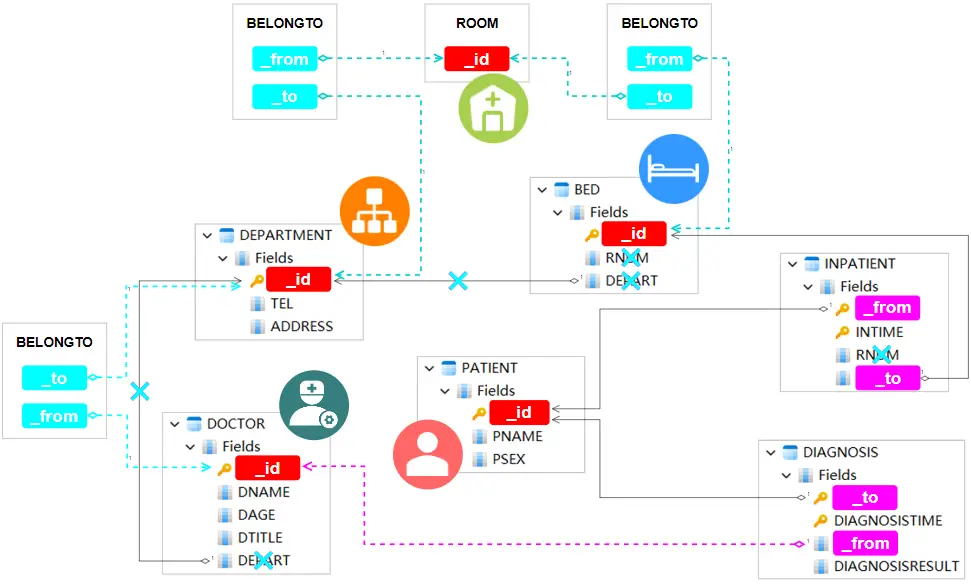
提取点模式ROOM、共享边模式BELONGTO
拆分之后,表BED和表INPATIENT均不再需要字段RNUM了,我们使用边模式BELONGTO来表达的DEPARTMENT、ROOM和BED之间的隶属关系。不光如此,DOCTOR和DEPARTMENT之间的边WORKAS也可以用BELONGTO替代,反正这些边都只有FROM和TO两个属性。
对于新添加的点模式ROOM,除了ID之外还可以有更多属性,比如最多可容纳的床位数量等。这些属性可以结合实际需求来扩充,这样,我们就不仅仅是简单地将表结构转换为图结构,而是通过更精细地实体划分来更加灵活地管理数据。
在确定了图模型之后,下一步任务就是根据该模型对表数据进行清洗和改造,使其成为图数据。假设每一张表的数据都独立保存为一个CSV文件(如表DOCTOR的数据保存为DOCTOR.csv),文件表头直接使用表字段的名称,那么这个改造过程将涉及到表头的修改、字段内容的替换以及新CSV文件的建立。具体步骤如下:
- 将DEPARTMENT.csv、PATIENT.csv、DOCTOR.csv、BED.csv各自主键所在列的表头改名为_id
- 将IMPATIENT.csv的表头PNO改名为_from,将表头RBNUM改名为_to,将RNUM整列删除
- 将DIAGNOSIS.csv的表头PNO改名为_to,将表头DNAME改名为_from并将其下的数据替换为DOCTOR.csv中_id下的数据
- 创建BELONGTO.csv,创建表头_from和_to
- 将DOCTOR.csv中的_id、DEPART两个表头下的数据分别复制到BELONGTO.csv的_from和_to下,注意保持行内数据的对应关系,之后将DOCTOR.csv中的DEPART整列删除
- 创建ROOM.csv,创建表头_id,将BED.csv中RNUM下的数据去重后复制到ROOM.csv的_id之下
- 将BED.csv中的_id、RNUM下的数据分别复制到BELONGTO.csv的_from和_to下,注意保持行内数据的对应关系
- 将BED.csv中的RNUM、DEPART下的数据联合去重后分别复制到BELONGTO.csv的_from和_to下,注意保持行内数据的对应关系,之后将BED.csv中的RNUM、DEPART整列删除
请注意,表的主键值需要处理为全库唯一[2]之后才能被用作图数据的ID,与它们相关联的外键也要同步修改。这也是我们很多用户遇到的实际情况,尽管本文所使用的表数据并不存在这一问题。
得到图数据之后,我们便可以将数据导入到嬴图系统的某个图集中。导入的方法有很多,可以通过嬴图系统的可视化管理工具嬴图Manager将文件逐个导入,也可以通过命令行工具嬴图Transporter(Importer)将所有文件同时导入。数据导入之后,就可以在嬴图Manager中查看图模型与图数据了:
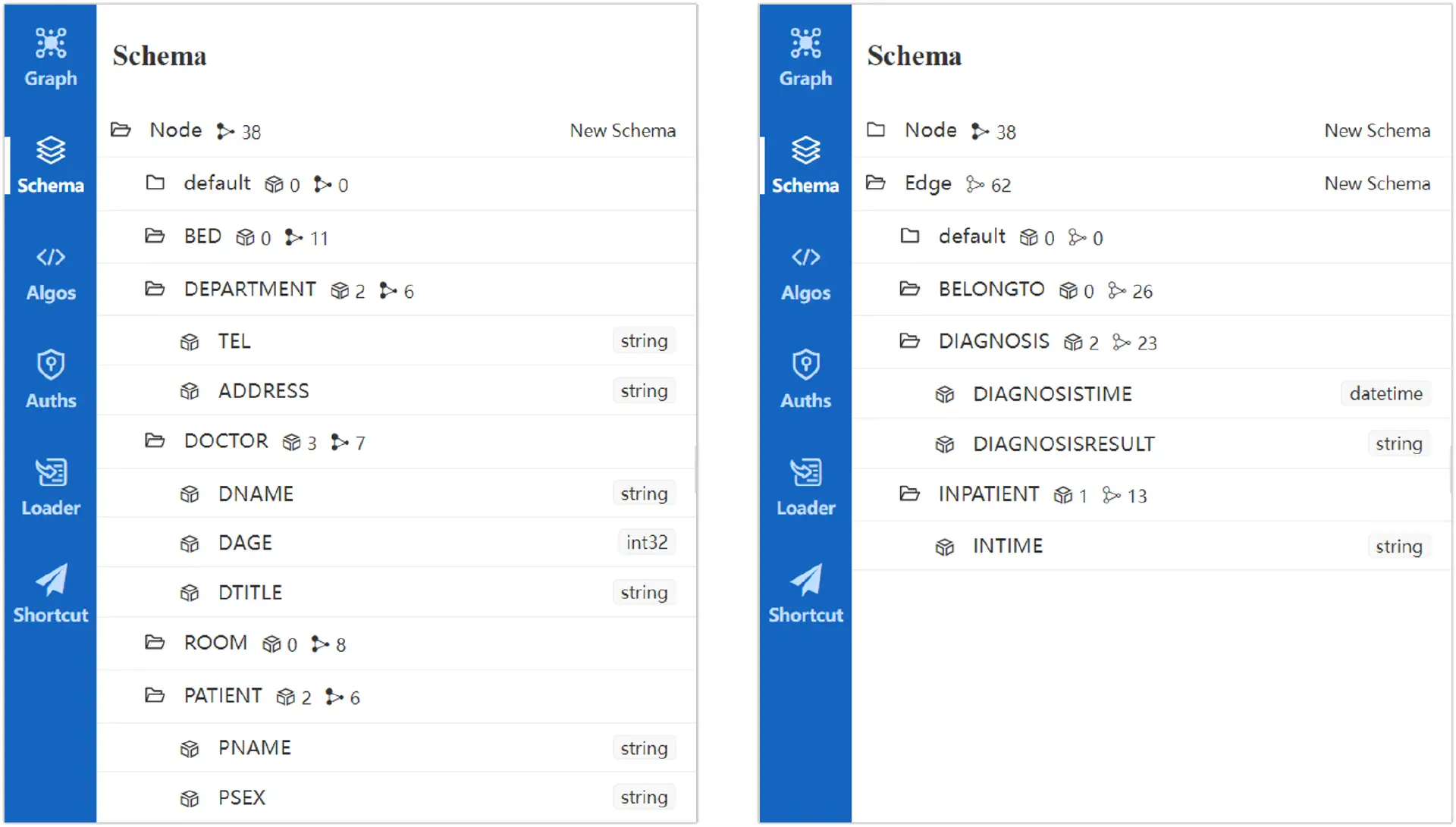
嬴图Manager将图模型展示为schema和属性列表
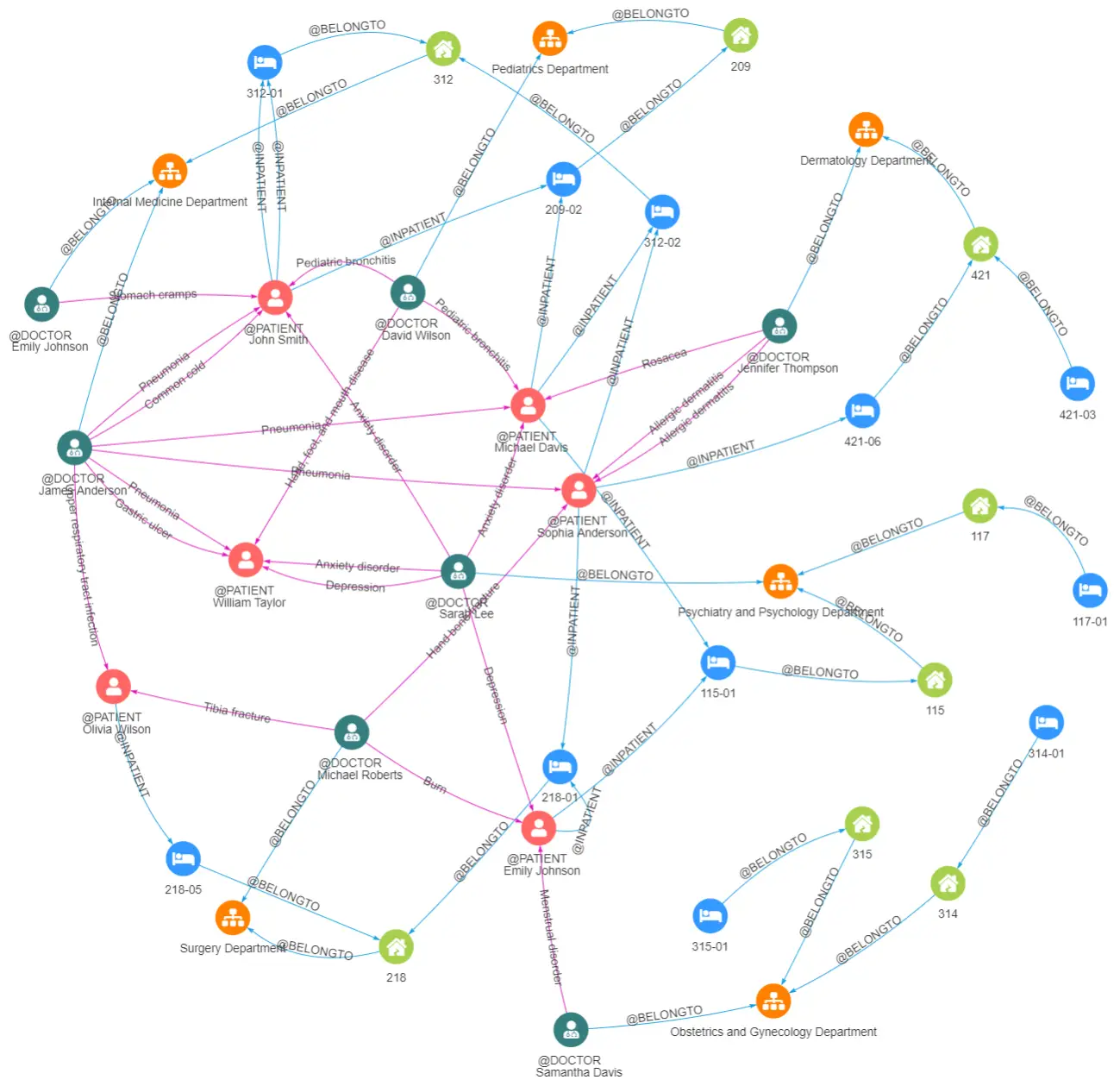
嬴图Manager对图数据的2D展示
嬴图Manager的2D渲染功能使用鲜明的颜色和图标令各种实体之间的关系清晰可见,我们只需一瞥就能轻松辨别图中哪些节点之间存在密切联系,比如可以从某个病床轻松追溯到其患者的主治医生。这种直观性和便捷性使图数据库在可视化方面的表现远远超过了关系型数据库,让数据分析和探索变得更加方便有趣。
结语
希望本文能够为图数据库的初学者提供一些有关图建模的启示。在实际应用场景中,图数据库的图模型构建还会涉及更加复杂的情况,图模型本身也并非一成不变,需要在业务需求发生变化时进行灵活调整,以确保高效的查询。最后,图数据库是一个充满创造性和变化的领域,希望随着经验的积累和学习的深入,我们终将更好地驾驭这个强大工具,为项目带来更多可能性。
注释:
[1] 模式:在某些关系型数据库(如MySQL或PostgreSQL)中,一个服务器连接内数据管理的层级关系为“数据库-模式-表-字段”,而在嬴图系统中则为“图-模式-属性”。嬴图系统中的模式相当于关系型数据库中的表,模式的属性相当于表的字段。当然这只是通过打比方来解释嬴图系统中的模式和属性为何物。
[2] 嬴图系统中的点ID和关系型数据库中的表主键有区别。在嬴图系统中,点的ID具有全图唯一性,而不是在某一种模式中唯一。打个比方,如果abc是某个医生的ID,那它就不能再作为某个患者或图中任意一个节点的ID了。在关系型数据库中,表的主键仅需在表内唯一,不同表的数据的主键是可以重复的。这使得在具体应用中,某些表的主键需要经过处理之后才能被用作图数据的ID,与它们相关联的外键也要同步修改。