高密度并行图计算(High-Density Parallel Graph Computing,以下简称HDPC)是高性能、实时图计算的核心技术。它通过充分的释放和利用物理CPU多核、多线性并发来实现更低时耗地完成图查询与分析。
HDPC并不是每一个图计算或图数据库系统都具备的。以图数据库厂商Neo4j为例,它的典型企业级部署(高配)采用的是3实例,每个实例8核CPU的部署,在工作状态下,任一时刻只有一个实例参与图计算,另外两个实例处于热备份状态,而每个实例的最大并发计算能力是4线程,也就是说每个图查询操作只有最大400%的服务器级并发程度。
反之,在嬴图数据库系统中,并发能力是与底层的硬件线性挂钩的,也就是说如果是32vCPU的部署,并发可达3200%,如果是64vCPU,并发为6400%,并以此类推!这种线性可增长的、高密度的并发所带来的直接的收益有2个:
- 系统整体性能、吞吐率的指数级提升,6400% vs 100%这是至少64倍的提升。在高并发分布式系统中,这种差别可以被拉升到数以百倍的区别(例如,192000% vs. 100%)
- 资源利用率的提升,现代CPU都是高并发的微系统,遗憾的是Python爱好者们大多不知道如何高效的利用底层的硬件并发能力,结果就是对资源的白白浪费。
在之前的一篇名为《图数据结构的进化》的文章中,我们介绍过嬴图系统的这种特性,简而言之,没有高密度并发计算的能力,根本就不可能实现指数级的系统性能提升!
CPU的并发计算是需要底层的并发数据结构的支撑的,有了这种强有力的支撑,就可以在上面实现深度的图遍历以及动态剪枝,这两个功能结合起来对应于很多商务场景都价值巨大。例如:时序路径计算、深度关联关系分析、2度-2度-N度影响力评估等等——在BI、风险管理、风控、反欺诈、智慧经营、资产负债管理、精准营销、数据治理、供应链金融等场景下都大量的需要这些基础功能。
图上面的很多操作,例如全图分析,需要依赖图算法来实现,而很多图算法的典型特点是需要对全图进行反复遍历以及递归式的操作,计算量巨大,而那些源自学术界的原生的图算法都是串行的(例如鲁汶社区识别算法),如果不加以改造升级为并发算法,那么时耗的区别是巨大的。
来看一个对比:在一张百万量级点边的图上面,用Python NetworkX来完成鲁汶社区识别,需要10个小时(类似的,华为的GES图计算系统需要~3个小时),而通过嬴图数据库则在1秒钟内以纯实时的方式完成,这种性能差异数以万倍计——区别在于是否实现了高并发、高密度并发原生图计算!
即便是一条看似简单的图查询语句,例如查找图数据集中某个顶点的K邻,以串行的方式BFS查询,还是以高并发的模式进行BFS查询,有着指数级的性能差异。
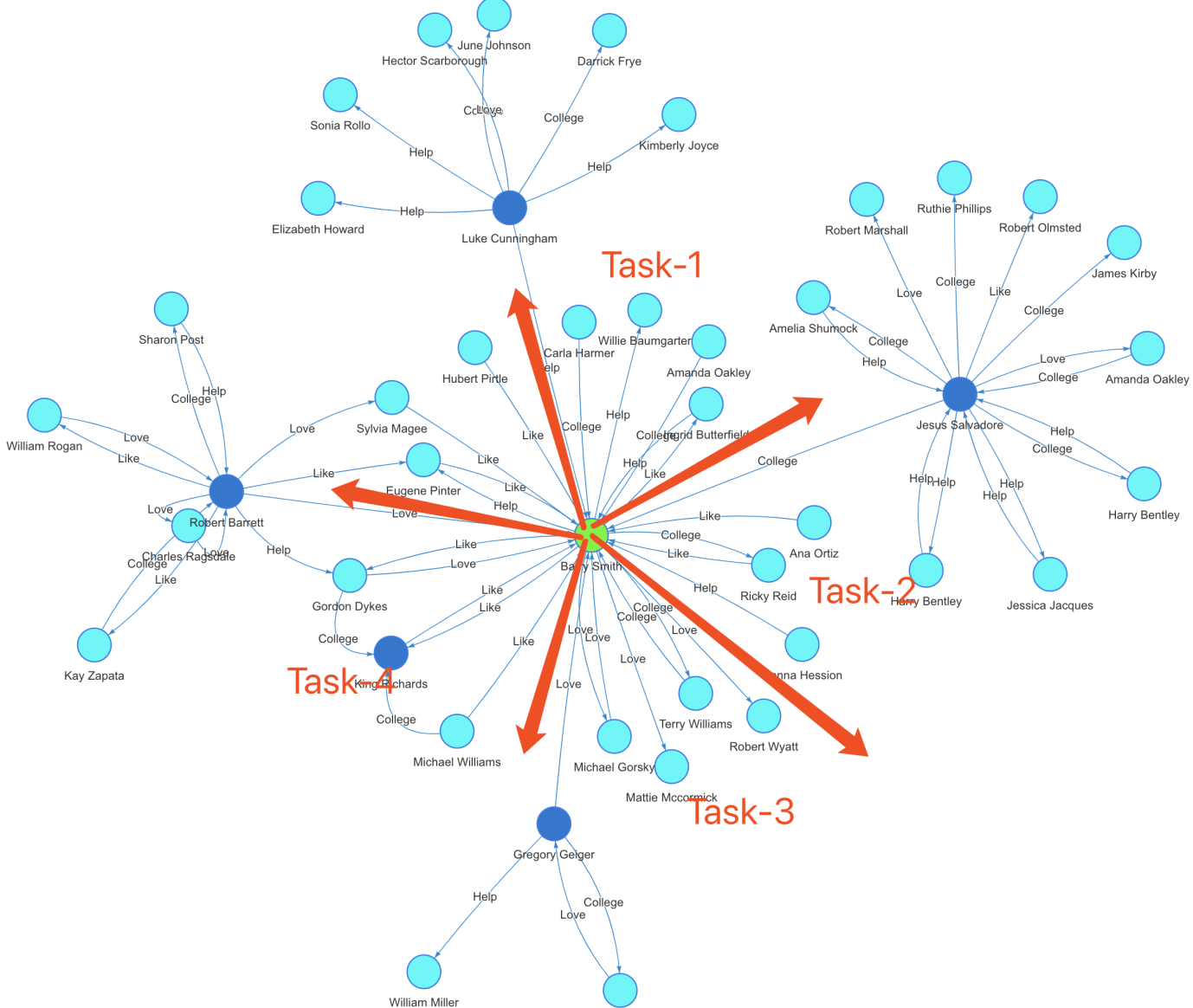
K邻查询的并发算法步骤如下:
- 在图中定位起始顶点(上图中的绿色顶点),计算其直接关联的具有唯一性的邻居数量。如果K=1,直接返回邻居数量;否则,执行下一步。
- K>=2, 确定参与并发计算的资源量,并根据第一步中返回的邻居数量决定每个并发线程(任务)所需处理的任务量大小,进入第三步。
- 每个任务进一步以分而治之的方式,计算当前面对的(被分配)顶点的邻居数量,以递归的方式前进,直到满足深度为K或者无新的邻居顶点可以被返回而退出,结束。
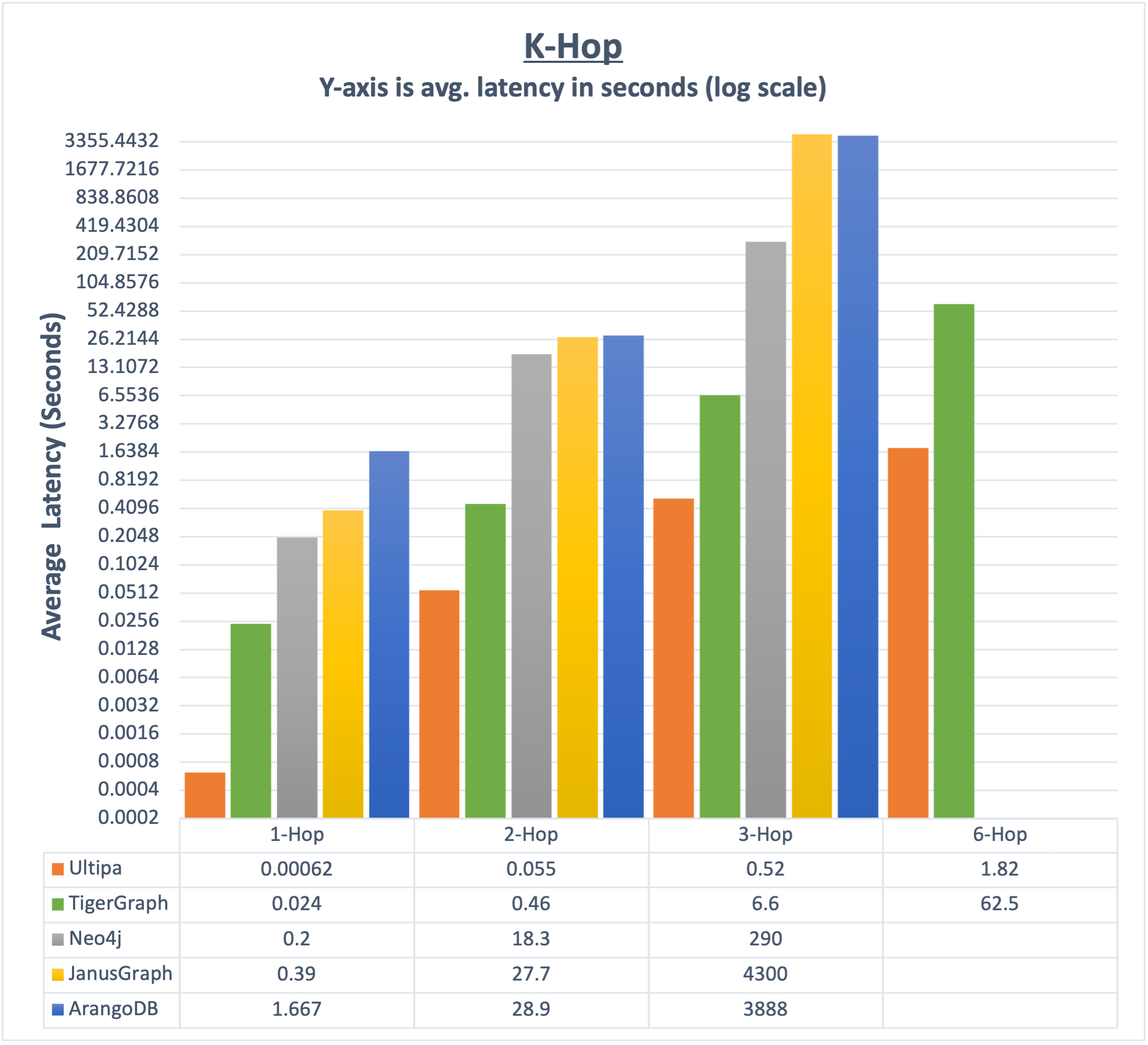
当K邻计算深度为1-2层的时候,即便是串行的模式,图计算引擎也可以较快返回(<1秒),但是,如果遇到超级节点,是否并发将会产生指数级的时耗差异!通过饱满的并发操作,系统的延时可以保持在相对低的水平,并呈现了线性甚至亚线性的增长趋势(而不是指数级增长趋势!)。以大家所熟知的Twitter-2010数据集中,因为4200万的顶点集合中存在大量超级节点(一般认为1度邻居在10000以上的顶点为超级节点或热点,而Twitter数据集中有很多顶点的1度邻居超过1000000个),因此是否能够实现以并发的方式递归查询至关重要——高并发的嬴图系统可以在6-hop查询中≤2秒钟完成计算,而Tigergraph则需要≥60秒,而其它系统,包含Neo4j、Nebula Graph、HugeGraph、ArangoDB等则完全无法返回。
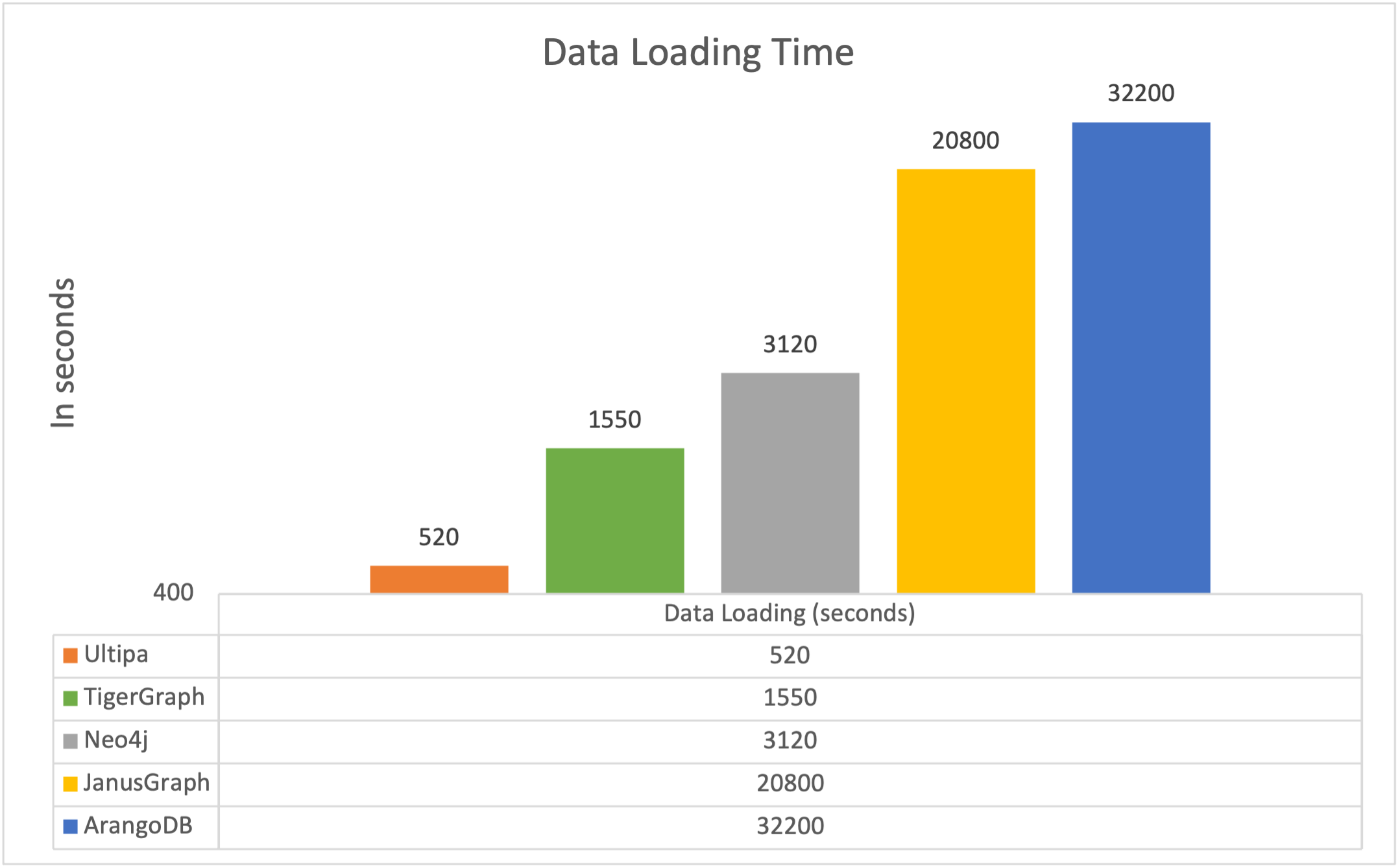
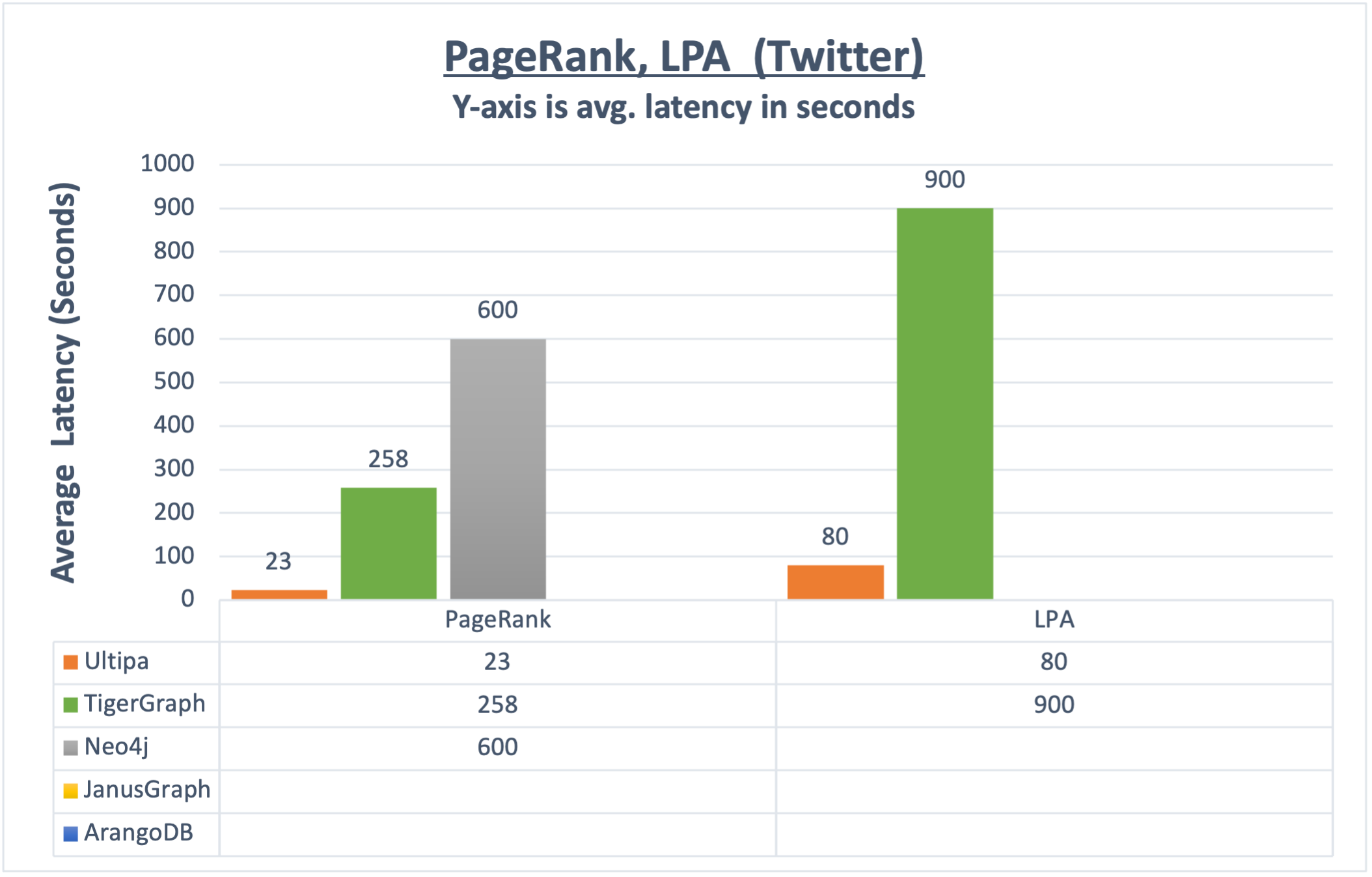
在2022年初的一次基准测试中,我们以Twitter数据集为基础,对标了多家图数据库系统的性能,结果简报如下:
- 数据加载:除了Tigergraph与嬴图性能接近,其它系统要慢2-15倍
- K邻查询:嬴图比所有其它系统快至少10倍以上。事实上,超过6跳的深度查询,只有嬴图可以返回结果。
- 图算法:嬴图比任何其它图数据库系统快10倍以上。很多系统根本无法完成算法执行。
高密度并发图计算带来的最大收益是:
- 高性能、低延时
- 高ROI、低TCO
计算作为高性能图数据库系统的一等公民,是区别于关系型数据库、数仓或大数据平台的最重要的区别之一!后者因为历史原因,一直把存储引擎作为一等公民,而计算则附庸于存储引擎。两者之间设计的区别如下:
- 数仓、关系型数据库:适合解决存储I/O密集型场景
- 高性能图数据库:解决计算密集型挑战!
或许,面向未来的图数仓系统可以兼顾存储密集型与计算密集型挑战于一身。这也是嬴图数据库的产品的发展方向。