作者:孙宇熙 & 张建松
很显然,我们正处于一个大数据的时代。互联网和移动互联网络的快速发展带来了数据产生速率的极大增长。每天、每时每刻都有数以十亿量级的设备(有人预计在 2030 年前,会有超过千亿量级的联网传感设备)在产生巨大体量的数据。
数据库是被人们创造出来解决这种不断增长的数据挑战的利器。还有其它类似的概念、工具和解决方案,例如数据仓库、数据集市、数据湖泊等等,来解决我们日常所面对的数据存储、数据转换、数据分析、汇总、报表等等一系列工作。但是,是什么让数据库变的如此重要,以至于我们对其难以割舍呢?笔者以为,有两件事情是数据库的核心“竞争力”:
- 性能(Performance)
- 查询语言(Query Language)
在现代商业社会中,性能应该是“一等公民”。一个数据库之所以可能被称作是数据库,意味着它可以在合理的,通常是最小的,至少是符合商业诉求的延迟内来完成规定的工作。这一点上,数据库和商务智能时代的很多数据仓库或 Hadoop 大数据阵营的解决方案显得很不相同,后者或许有着很好的分布式、可扩展的能力,但是他们的性能绝不是“令人骄傲”的优势之一。这或许可以解释为什么我们在近年看到了市场上关于 Hadoop 已经死亡的一些看法,至少越来越多的商业落地场景中,基于内存计算的 Spark 和其它一些新型的基础架构正在不断取代 Hadoop。
注:遗憾的是,以关系型数据库为代表的传统数据库架构中,计算是附着于存储引擎而存在的。只有存储引擎是一等公民,计算只是二等公民。连 SQL 的 Stored Procedure 都被叫做”存储进程“。翻开任何一本教科书,只有存储引擎的章节,而不会有独立的”计算引擎“的章节。随着大数据、快数据时代的来临,SQL 的这一套架构已经越发显得不合时宜了。
从大数据向快数据(Fast Data)转型或迁移的趋势是为了做到让底层的数据库框架可以应对不断增长的数据规模,而不至于牺牲数据处理性能(数据吞吐率)。下图中展示了以数据库为中心的数据处理基础架构和技术的进化路径。需要指出的是,在这个过程中有一些技术和产品是”反智“的,最典型的莫过于 Hadoop 生态和一些无法提供高性能计算的所谓的”水平分布式数据库“系统。这两类反智系统的最大特点都是可以解决 IO 密集型操作,但是无法解决计算密集型挑战。简而言之,就是它们宣称用大量的低配置的服务器来实现了更大体量的数据存储,但是一定没有高性能计算的能力!包括很多云平台也有类似的虚假宣传——100 台低配的机器,或许能比 10 台高配的机器提供更大的存储空间,但是计算能力(特别是复杂类型的查询)反而变差了很多!打个比方,1 台物理机如果被虚拟化成 3 台虚拟机,这 3 台虚拟机的计算和存储能力都受限于底层的那台物理机!而现在很多所谓的水平分布式系统所宣传的就是 3 台虚拟机碾压 1 台物理机!

Diagram-0:从数据到大数据,到快数据再到深数据的进化路线
查询语言是计算机编程语言出现以来被发明出来的最好的事物之一。我们希望计算机程序可以有着人类一样的对数据的智能化的、深度的筛选能力,但是这种强人工智能的诉求目前为止还从来没有被真正实现过。退而求其次,聪明的程序员们、语言学家们通过创建人造的计算机编程语言来帮助把人类的意图、指令实现,而数据库中的查询语言就是这种可以面向数据的“半智能化的”数据处理语言。
在我们准备进入众所周知的 SQL 的世界之前,让我们来先概览一下非关系型数据库(例如 NoSQL 等)所支持的查询语言的一些特性。
首先,我们来看一下键值数据库(KV Store),常见的键值库的实现有 Berkeley DB、Level DB 等等。技术上而言,键值库并不支持或使用确切的查询语言,这是因为它之上所支持的操作实在是太简单了,使用简单的 API 就已经足够了!典型的键值库支持三种操作:
- 插入(Insert)
- 读取(Get)
- 删除(Delete)
你可能会质疑说 Cassandra 支持 CQL(英文全称为 Cassandra Query Language)。没有问题,Cassandra 实际上是一种宽列库(wide-column store),我们可以把它看做是一种二维的键值库。对于 Cassandra 所支持的数据操作复杂度极高且高度分布式的架构而言,提供一层抽象查询语言来减少程序员的工作负担是绝对具有其正面意义的——否则程序员就需要记住那些复杂的 API 调用函数的各种参数集合。另外,CQL 使用了与常规 SQL 类似的概念,例如表、行、列等概念——我们后续会更多的讨论 SQL 相关的议题。
对于 Apache Cassandra 的一个批评,或许可以看做是对 NoSQL 数据库的整体而言的,是 CQL 并不支持 SQL 中常见的 JOIN(表连接)操作。很显然,这种批评的思路是深深的根植于 SQL 的思维方式之中的—— JOIN 是个双刃剑,它解决了一件事情的同时,也带来了一个问题,比如(巨大的)性能损耗。事实上,Cassandra 可以支持 JOIN 操作,通过以下两种解决方案:
- SPARK SQL:Apache Spark’s Spark SQL with Cassandra
- ODBC 驱动:Cassandra with ODBC driver

Diagram-1:在 Spark 结构化数据架构上的 Spark SQL 查询语言
然而,这些解决方案并不是没有代价的,例如 ODBC 在面向大数据集或集群化操作时性能是个问题。而 Spark SQL 则是在 Cassandra 基础上面又叠加一层新的系统复杂度,对于多系统维护、系统稳定性,以及不少程序员痛恨了解新系统、学习新知识而言,都是个挑战。
关于 Apache Spark 和 Spark SQL 不得不多说两句,Spark 设计之初就是要应对 Apache Hadoop 的低效性和低性能。Hadoop 从谷歌的 GFS(谷歌文件系统)以及 Map-Reduce 理念及实现中借鉴了两个关键概念,并由此而创造了 HDFS(Hadoop 分布式文件系统)以及 Hadoop MapReduce;Spark 则相当于利用了分布式共享内存架构实现了 100 倍的相对于 Hadoop 而言的性能提升。打一个比方,仅仅是简单把数据从硬盘移入到内存中来处理,你就会获得 100 倍左右的性能提升,因为内存的吞吐率就是硬盘的 100 倍之高,证明完毕。Spark SQL 是提供了一个 SQL 兼容的查询语言接口来支持访问 Spark 中的结构化数据,相比于 Spark 原生的 RDD API 而言,Spark SQL 已经算作是一种进步了——如前所述,如果 API 变得过于复杂的时候,对查询语言的诉求就变得越来越强烈了,因为它更加灵活、实用、强大!
注:笔者在十几年前 Yahoo! 战略数据部(SDS)就职期间,正是 Yahoo! 在孵化 Hadoop 项目的时期,相比 SDS 的其它高性能、分布式海量数据处理框架实现而言,Hadoop 的性能已经是在内部众所周知的不尽如人意,笔者印象最深刻的就是很多 Linux 中常见的排序、搜索等工具都被改写为可以以极高的性能来应对海量数据的处理,例如 sort 命令的性能被提升 100+ 倍来应对 GB 到 TB 量级的大数据集的排序挑战。或许这也能解释为什么 Hadoop 后来被 Yahoo! 捐献给了 Apache 开源社区,而其它显然更具备性能优势的项目却没有被开源。或许读者要思考:开源的就是最好的吗?
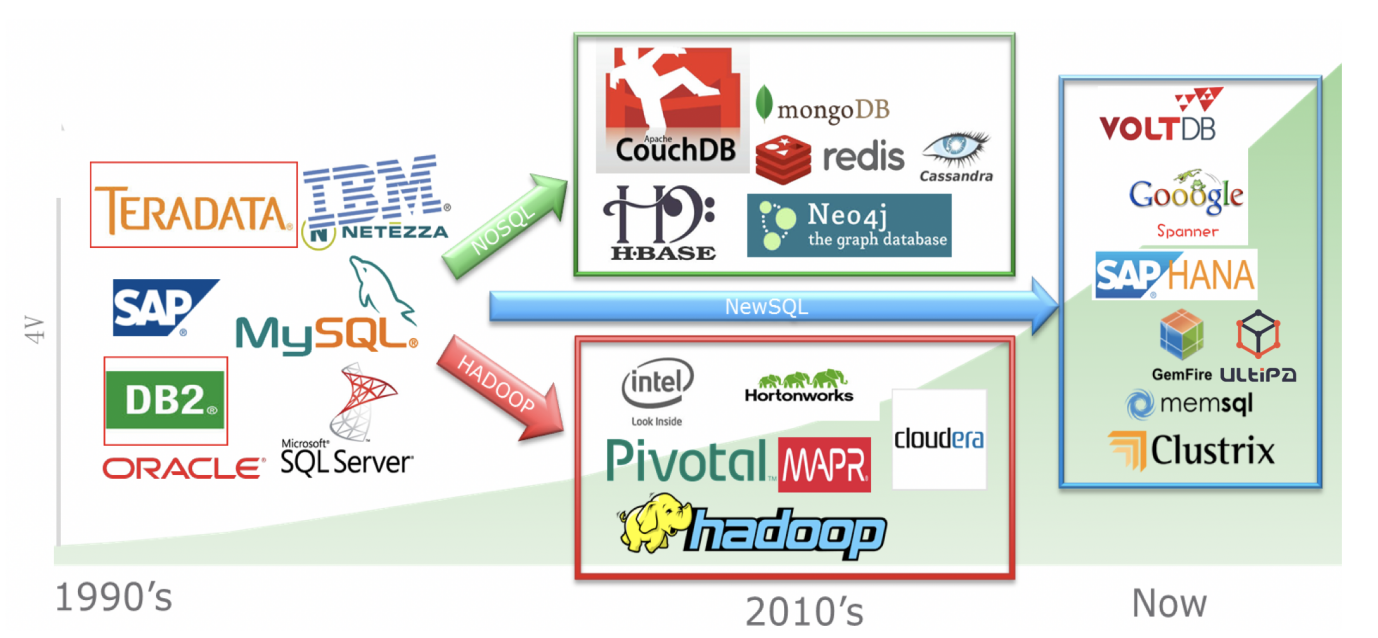
Diagram-2:数据库和数据处理技术的演进历程
比照 Diagram-0 中提及的整个业界的数据处理技术的演化(从数据→大数据→快数据→深数据),对应的底层的数据处理技术就会从关系型数据库主导的时代向非关系型数据库(例如 NoSQL/Spark 等)、NewSQL 和图数据库框架演进!Diagram-2 中列出了这种趋势和演化路径——我们可以大胆的预判未来的核心数据处理基础架构一定是至少包含或由图架构主导的。
在过去半个世纪中的数据库技术的进化或可通过 Diagram-3 来概括,一言以蔽之:从 70 年代之前的导航型数据库,到 70-80 年代开始兴起的关系型数据库,到 90 年代的 SQL 编程语言的兴起,到 21 世纪第一个 10 年后出现的各种 NoSQL(NoSQL = Not Only SQL,不仅仅是SQL!)——或许下面这张图留给我们一个迷思,图查询语言会是终极的查询语言吗?
换个角度问个问题:人类终极的数据库是什么?或许你不会反对这个答案:人脑!人类的大脑到底是什么样的数据库技术?笔者以为是图数据库,至少在概率上它远远高于关系型数据库、列数据库、键值库、文档数据库或时序数据库。或许是我们还没有发明的一种数据库。但是图数据库是最接近终极数据库的,毋庸置疑。对于这一点充满质疑的读者,建议阅读之前的一篇文章《图数据结构的进化》,希望有所帮助。
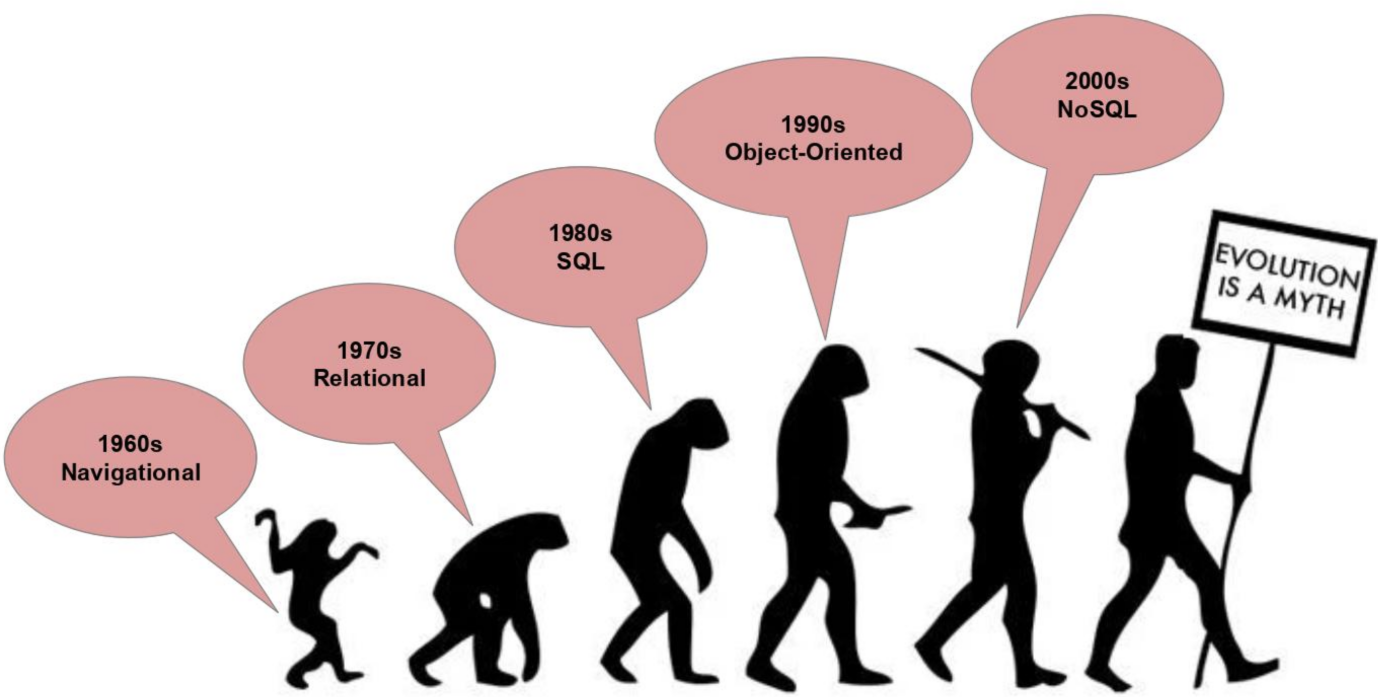
Diagram-3:进化的视角看数据库和查询语言的进化历史
如果读者对于 SQL 语言的演进有所了解,它直接的推动了关系型数据库的崛起(如果诸位还能回忆起在 SQL 语言出现之前的数据库的使用是如何的笨拙与痛苦的话)。互联网的崛起催生了NoSQL的诞生和崛起,其中很大的一个因素是关系型数据库没办法很好的应对数据处理速度、数据建模灵活性的诉求。
NoSQL 数据库一般而言被分为以下 4 或者 5 大类,每一类都有其各自的特性:
- 键值(Key-Value):性能和简易性(Performance and simplicity)
- 宽列(Wide-Column):体量与性能(Volume and performance)
- 文档(Document):数据多样性(Variety of data structures)
- 图(Graph): 深数据+快数据(Deep-data and fast-data)
- (可选的)时序(Time Series):IOT 数据、时序优先性能(Performance for time-stamped/IOT data)
从查询语言(或者 API)的复杂度的角度来看,数据处理能力也存在着一条进化路径。如下图 Diagram-4 所示,形象的表达了 NoSQL 类数据库和以 SQL 为中心的关系型数据库之间的比对:
- 相对原始的键值库 API → 有序键值库(Ordered Key-Value)
- 有序键值库 → 大表(Big-Table 是一种典型的 Wide Column 库)
- 列数据库 → 文档数据库(例如 MongoDB),并带有全文搜索能力(搜索引擎!)
- 文档数据库 → 图数据库
- 从图数据库 → SQL 中心化的关系型数据库。
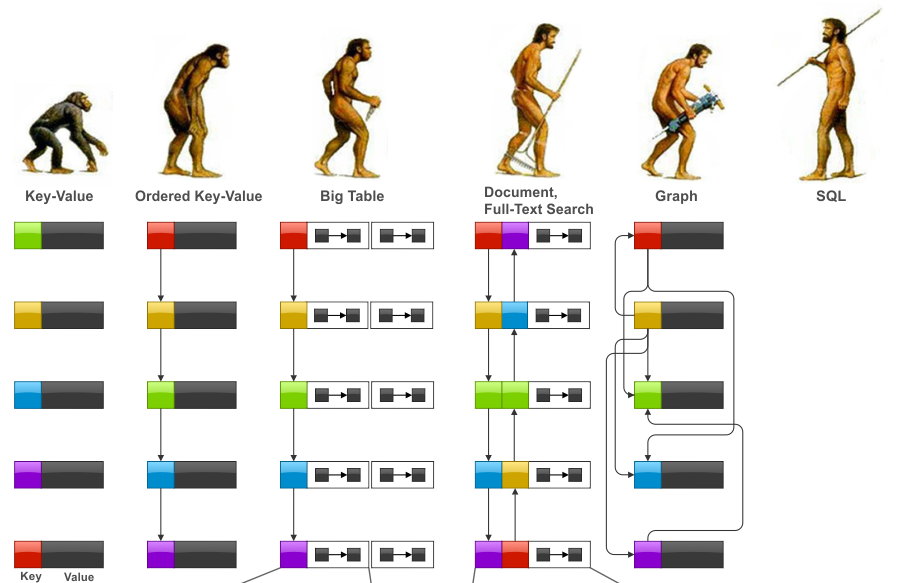
Diagram-4:数据库查询语言的进化(一家之言)
上图中,SQL 被认为是最先进的数据处理与查询语言。但是,这个观点是 20 年前的!随着图数据库技术的推陈出新,我们已经可以清晰的看到 SQL/RDBMS 在逐步走向衰败,而 GQL 和 GraphDB 会逐步成为下一代的主流数据库。
在这里我们需要稍微深入的研究一下 SQL 的演化历史,来帮助我们有个更全局化的观念。
SQL 的出现已经将近 50 年了,并且已经迭代了很多版本(平均每 3-4 年一次大迭代),其中最知名的非 SQL-92、99 莫属,例如在 92 版本中在 FROM 语句中增加了子查询(subquery)功能;在 99 年版本中增加了 CTE(Common Table Expression)功能。这些功能极大的增加了关系型数据库的灵活性(如下图所示)。


Diagram-5: Subquery per SQL-92 and CTE per SQL-99
然后,关系型数据库始终存在一个“弱点”,那就是对于递归型数据结构的支持(Recursive data structures)。所谓递归数据结构,指的是有向关系图的功能实现。令人感到讽刺的是,关系型数据库的名字虽然包含了关系,但是它在设计伊始就很难支持关联关系的查询。为了实现关联查询,关系型数据库不得不依赖表连接操作——每一次表连接都意味着潜在的表扫描操作,以及因为”笛卡尔积“问题导致的性能指数级下降(以及 SQL 代码的复杂度、维护难度的直线上升)!
表连接操作的性能损耗是直接源自于关系型数据库的基础设计思想的:
- 数据正则化(Data Normalization)
- 固定化的、预先设定的表模式(Fixed/Predefined Schema)
如果我们看一下 NoSQL 中的核心理念,在数据建模中突出了数据去正则化。所谓数据去正则化,指的是用空间换取时间(牺牲空间来换取更高的性能!),在 NoSQL(也包括 Hadoop 等,例如典型的 3、5、7 份拷贝的理念)中,数据经常被以多份拷贝的方式存储 ,而这样做的好处在于数据可以以紧邻计算资源的方式被处理。这种理念和 SQL 中的只存一份正则化设计思路是截然相反的——后者或许可以节省一些存储空间,但是对于复杂的 SQL 操作而言,带来的是性能的损耗。
预先定义数据的表模式的理念是 SQL 与 NoSQL 的另一大差异。对于初次接触这一概念的读者而言,理解这个点会有些复杂,从下面这个角度去理解或许更直观:
模式第一,数据第二 vs. 数据先行,模式第二
Schema First, Data Second vs. Data First, Schema Second
在关系型数据库中,系统管理员(DBA),需要先定义表的结构(schema),然后才会加载第一行数据进入数据库,他不可能动态的更改表的结构。这种僵化性对于固定模式、一成不变的数据结构和业务需求而言或许不是什么大问题。但是,让我们想象一下如果数据模式可以自我调整,并能根据流入的数据动态调整,这就给了我们极大的灵活性。对于强 SQL 背景的人而言,这是很难被想象的。但是,如果我们暂时抛弃掉我们的僵化的、限制性的思维,取而代之以一种成长性的思维方式 – 我们所要达成的目标是一种“ Schema-Free 或 Schemaless ”的数据模式,也就是无需预先设定数据模式,数据之间的关联性不需要预先定义和了解,随着数据的流入,它们会自然的形成某种关联关系 – 而数据库所需要做的是对应着这些数据“因地制宜”的来处理如何查询与计算。
在过去几十年中,数据库程序员已经被训练得一定要先了解数据模型,不论它是关系型表结构还是实体 E-R 模式图。了解数据模型当然有它的优点,然而,这也让开发流程变得更加复杂和缓慢。如果读者们还记得上一次你参与的交钥匙解决方案的开发周期有多长了?一个季度、半年、一年还是更久?在一个有 8000 张表的 Oracle 数据库中,没有任何一个 DBA 可以完全掌握所有表之间的关联关系 – 这个时候,我们更愿意把这套脆弱的系统比作一个定时炸弹,而你的所有业务都绑定在其上!
关于无模式(Schema-Free),我们并不想解释文档型数据库或者宽列据库,尽管它们都多少有一些和图数据库相似的设计理念。我们在下文中会用一些具体的图数据库上的例子来帮助读者理解无模式意味着什么。
在图数据库中,逻辑上只有两类基础的数据类型:
- 顶点(Nodes 或 Vertices)
- 边(Edges)
一个顶点具有它自己的 ID 和属性(标签、类别及其它属性)。边也类似,除了它通常是由两个顶点的顺序决定的(所谓有向图的概念指的是每条边由一个初始顶点对应一个终止顶点,再加上其它属性所构成,例如边的方向、标签、权重等等)。除了这点儿基础的数据结构,图数据库并不需要任何预先定义的模式或表结构!这种极度简化的理念恰恰和人类如何思考以及存储信息有着很大的相似性——我们通常并不在脑海中设定表结构,我们随机应变!!!
现在,让我们看一看一些真实世界场景中的图数据库实现,例如下图(Diagram-6)中的一个典型的图数据集中的顶点的属性定义,它包含了最初的几个字段的定义例如 desc、level、name、type,但是也存在一些动态生成、扩增的字段,例如#cc、#pr、#khop_1等等。如果比照着关系型数据库而言,整个表的结构是动态可调整的。
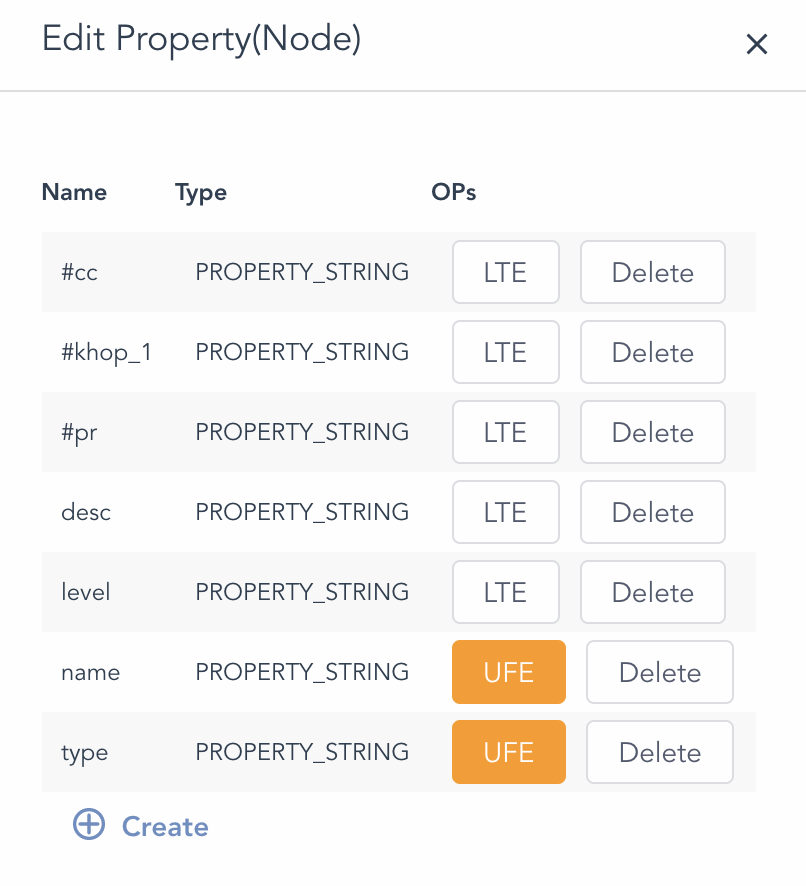
Diagram-6:图数据集中的顶点属性(动态属性)
注意上图中的 name 和 type 字段的属性为 STRING 类型,它可以最大化兼容广谱的数据类型,进而提供最大化的灵活性。顶点之间如何产生关联也无需被预先定义,这样所形成的关联网络也是灵活的。
细心的读者一定会问到,这种灵活性怎么来实现和保证性能优化呢?常识的做法是通过存储与计算分层来实现,例如为了实现极佳的计算性能,数据可以动态的加载进入内存计算(LTE vs. UFE = Load-to-Engine vs. Unload-from-Engine),当然内存计算只是一部分,支持并发计算的数据结构也是必不可少的,有兴趣的读者可以参考之前的一篇文章《图数据结构之进化》。
键值库可以被看做是前-SQL(Pre-SQL 在这里表达的是一种相对于 SQL 而言更原始的特型)的非关系型架构库,图数据库则可被看做是后 SQL(Post-SQL 在这里表达了一种相对而言的先进性)时代的,真正意义上支持递归式数据结构的数据库。今天的不少 NoSQL 数据库都试图通过兼容 SQL 来获得认可,但是在笔者看来,SQL 的设计理念是极度表限定的,所谓“表限定”(table-confined),指的是它的整个理念都是限定在二维世界中的,当要进行表连接操作时,就好比要去进入到三维或更高维的空间进行操作,而这也是时常低效和反直觉的,这是基于关系型数据模式的 SQL 本身的低维属性决定的。
图数据库天然是高维的(除非它的实现是基于关系型数据库或列数据库实现的,那么本质上这种非原生图的设计依然是低维驱动的,它的效率怎么可能会很高呢?),图上面的操作天然的是递归式的,例如广度优先搜索或深度优先搜索。当然,仅仅从语言的兼容性而言,图上面一样也可以支持SQL类操作来保持向关系型用户群的习惯兼容,就像 Spark SQL 或 CQL 一样,无论它的意义到底有多大或多长久。
下面,让我们一起来看一些通过UQL(赢图查询语言)实现的图上的查询功能。同时,请仔细思考用 SQL 或是其它 NoSQL 数据库将如何才能完成同样的任务?
- 从某个顶点出发,找到它的第 1 到第 K 层(跳)的所有邻居并返回。
UQL是与嬴图高并发实时图数据库匹配的查询语言。除了明显的性能优势以外,UQL的另外一个重要特点是高易用性,容易掌握,并有贴近自然语言的易读性。UQL可以通过嬴图Manager、嬴图CLI 或嬴图SDK/API 的接口调用。实现上面的查询,在UQL中只需要 1 句话就可以完成。

Diagram-7:通过 spread() 操作对联通子图进行遍历
一句话UQL:
spread().src(123).depth(6).spread_type(“BFS”).limit(4000);
上面的语句简单易懂,基本上不需要太多解释,调用 spread() 函数,从顶点 123 出发,搜索深度为 6 层,以 BFS 的方式进行搜索,限定返回最多 4000 个顶点(以及关联的边)。在 Diagram-7 图中,红色的小点就是起始顶点,通过以上语句操作的全部返回的顶点和边所形成的子图直接显示在嬴图的 WEB 界面上了。事实上,spread() 这个操作相当于允许从任何顶点出发找到它的联通子图——或者说它的邻居网络的形态可以被直接计算出来,并通过可视化界面直观的展示出来。用这种方式也可以看出生成的联通子图中的顶点和边所构成的热点、聚集区域等图上的空间特征——而并不需要传统数据库中的 E-R 模型图。
- 给定的多个顶点,自动组网(形成一张顶点间相互联通的网络)
本查询相对于熟悉传统数据库的读者来说或许就显得过于复杂了,用 SQL 也许无法实现这个组网功能。但是,对于人的大脑而言,这是个很天然的诉求——当你想在张三、李四、王五和赵六之间组成一张关联关系的网络的时候,你已经开始在脑海里绘制下面这张图了。
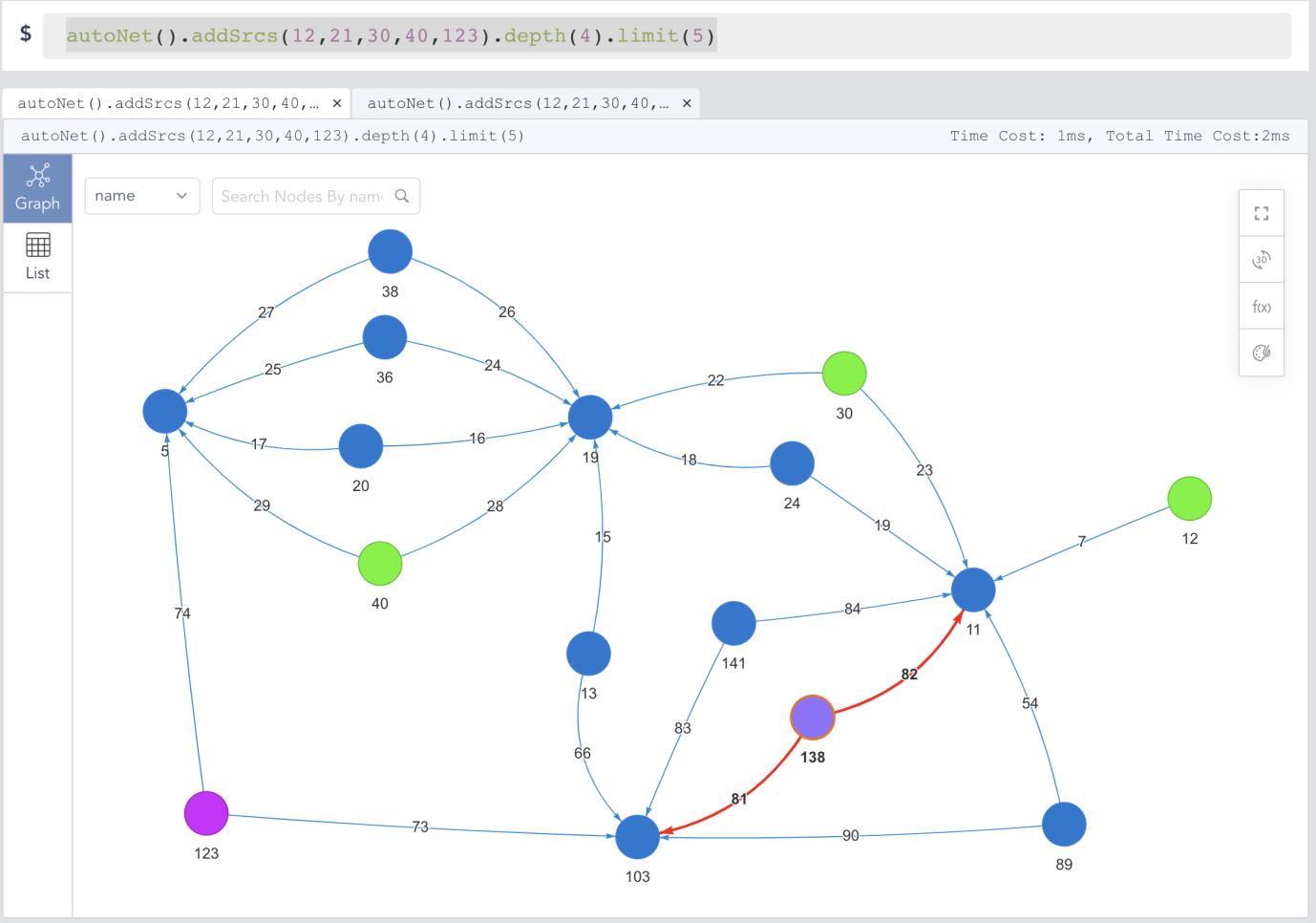
Diagram-8:在嬴图中自动生成网络(子图)
很显然,UQL倾向于继续使用 1 句话来实现这个“不可能”的操作:
autonet().srcs(12,21,30,40,123).depth(4).limit(5)
autonet() 就是我们调用的主要函数,它的名字已经非常直白了——自组网操作。你只需要提供一组顶点的 ID 信息,组网搜索的深度(4 层 = 4 跳),任意两个顶点间的路径数量限制为 5。下面,我们来从纯数学的角度来分析一下,这个组网操作的计算复杂度:
可能返回路径数量:C(5, 2) * 5 = (5 * 4 / 2) * 5 = 50 条
预估图上计算复杂度: 50 paths * (E/V)4 = 50 * 256 = 12800
注:我们假设图中的 (边数/顶点数) 比例 = 4(平均值),也就是 E/V=4,搜索深度为4的时候每条路径需要平均计算 256(4**4)次。
这个查询在现实世界的应用中意义非同凡响。例如执法机关会根据电话公司的通话记录来跟踪多名嫌疑人的通话所组成的深度网络的特征来判断是否有其它嫌疑人牵连期间,犯罪集团是否存在某种异动,或者任意个数的嫌疑人构成的犯罪组织(crime ring)间的微妙的联动关系等。
传统大数据技术框架之上,这种多节点的组网操作极为复杂,甚至是没有可能完成的任务。原因是因为计算复杂度太高 ,对于计算资源的需求太高,在短时间内没有可能完成,或者是以 T+7(亦或 T+15、T+30)的方式实现,等到结果出来的时候,嫌疑人早已经逃之夭夭或者罪案已经发生良久了。假设有 1000 个嫌疑人需要参与组网,他们之间形成的网络的路径至少有 50 万条(1,000 * 999) / 2)。如果查询路径深度为 6 层,如上所述,这个计算复杂度是 20 亿次(假设 E/V=4,实际上 E/V 可能 >=10,那么计算次数可能达到 50 万亿次)。基于 Spark 架构的计算平台可能需要数天来完成运算。利用嬴图数据库,该操作是以实时到近实时(T+0)的方式完成的,我们在不同的数据集上做过性能评测,嬴图的性能至少是 Spark 框架的几百倍到数千倍——如果原来需要 Spark 系统 1 天完成的计算,嬴图仅需数秒、数分钟!当与罪案斗争的时候,每一秒都很宝贵。

Diagram-9:基于嬴图的实时大规模的组网操作
对于像嬴图这样的实时高并发图数据库,性能肯定是“第一等公民”,但是这并没有让我们把语言的简洁、直观、易懂性当做次等公民。绝大多数人会发现UQL是如此的简单,掌握了最基本的语法规则后,通常阅读操作手册几分钟到 30 分钟内,就可以开始写出你自己的UQL查询语句了。
UQL借鉴并采用了锁链式查询(chain-query)的语言风格,对于熟悉文档型数据库 MongoDB 的读者而言,上手UQL就更加简单了。例如,一个简单的链式路径(点到点)查询语句:
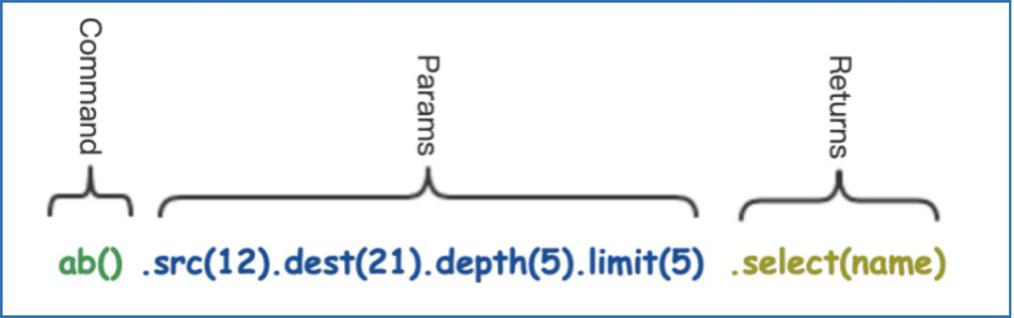
上面的例子中是去查询两个顶点间深度为 5 度的路径,限定返回 5 条路径,并且返回匹配的属性“name”(通常是顶点或边的名称属性)。
我们再来看一个稍微复杂一点的例子,模板查询,当然,它所完成的功能也更加的强大。例如下面的例子中 t() 代表调用模板查询调用,t(a) 表达的是为当前模板设定一个别名为 a,从顶点 12 开始,经过一条边抵达到属性 age 值为 20 的顶点 b(别名),返回这个模板所匹配的结果 a 和抵达顶点 b 的名字。和传统 SQL 类似的地方是可以对任何过滤条件设置别名,和 SQL 不同的地方是,当异构的结果 a 和 b.name 一同被返回的时候,a 表达的是整个模板搜索所对应的路径结果的集合,而 b.name 则是一组顶点的属性的数组集合(如下图所示)。这种异构灵活性是 SQL 不具备的。
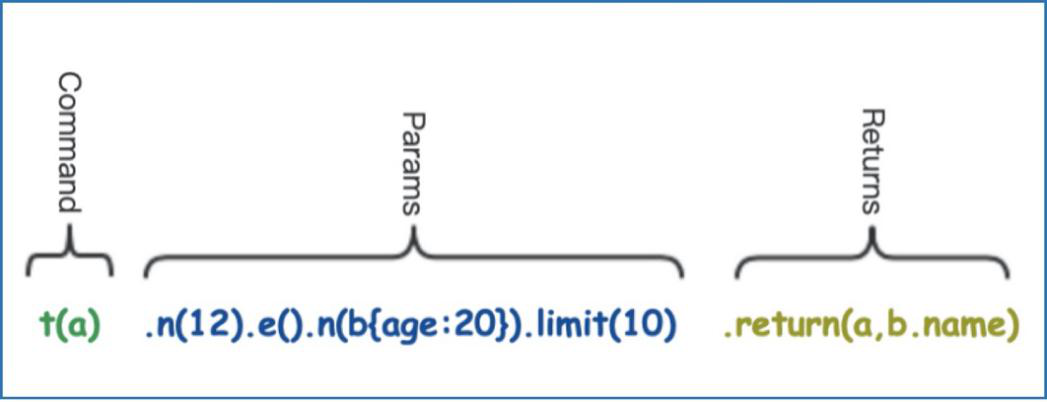
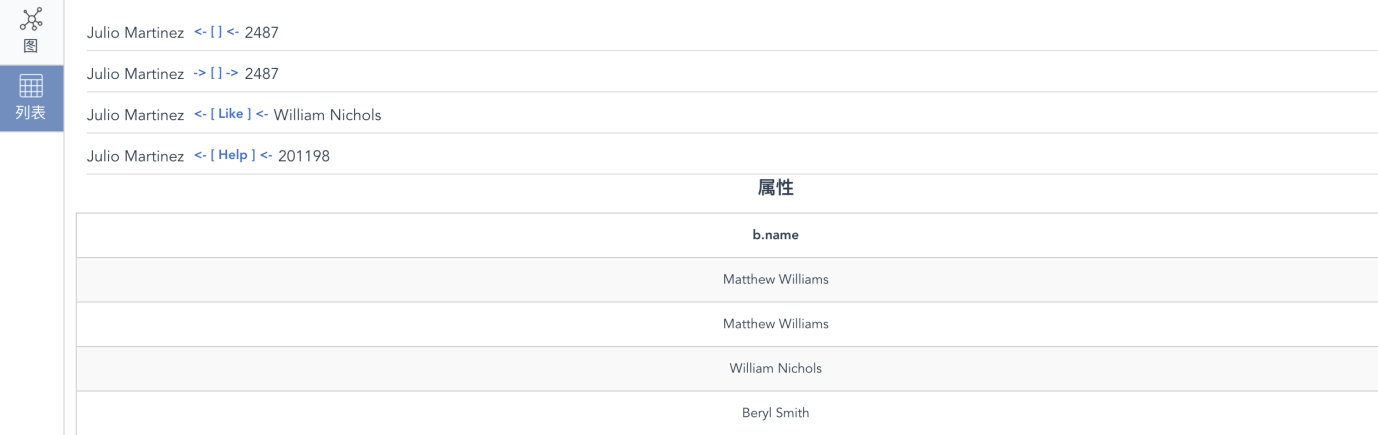
Diagram-9-A:图数据库查询中返回的异构结果集
下面我们再用一个例子来说明在图查询中使用简单的查询语言实现深度的、递归式的查询:
t(a1).n(n1{age:20}).e(e1{rank:{$bt:[20,30]}})[3:7].n(n2).limit(50).
return(a1, n1, e1, n2._id, n2.name)
这个语句中,从年龄 =20 岁的顶点(可能有多个)出发,进行深度为 3-7 层的路径搜索查询抵达某些顶点,并且路径中每条边的权重介于 20-30 之间,找到 50 条路径,并返一系列异构的数据(模板匹配的路径本身、起始顶点、边、终止定点的两个属性)。这种灵活度在 SQL 当中,如果不通过书写大量的封装代码是很难实现的,而且这种搜索深度也是令关系型数据库望而却步的——通常会发生因内存或系统资源耗尽而导致数据库出现 SEG-FAULT。
- 数学统计类型的查询,例如count(),sum(), min(), collect()等。
这个例子对于 SQL 编程爱好者而言一点都不陌生——统计一家公司的员工的工资总和。
t(p).n(12).le({type:"works_for"}).n(c{type: "human"}).return(sum(c.salary))
在UQL中实现也是一句话的事情:
- 从公司顶点 12 出发
- 找到所有工作于(边关系)本公司的员工,别名为 c
- 返回他们全部工资之和
在一张小表中,这个操作在 SQL 语境下同样毫无压力,但是在一张大表中(千万或亿万行),或许这个 SQL 操作就会因为表扫描而变得缓慢了。而在嬴图数据库中因为采用相邻哈希+近邻存储的存储逻辑及并发逻辑优化,这种面向一步抵达的邻居顶点的数学统计操作几乎不会受到数据集大小的影响,进而可以让任务执行时间基本恒定!
下面的这个例子中,则是统计该公司的员工都来自于哪几个省:
t(p).n(12).e({type:"works_for"}).n(c{type:"employee"}).
return(collect(c.province))
上面的两个例子是来说明通过UQL的方式同样可以实现传统关系型 SQL 查询所能实现的功能。同样,返回结果也可以以关系型数据库查询结果所常用的表单、表格的方式来呈现,例如下面的两图所示(Diagram-10-1 和 Diagram-10-2)。
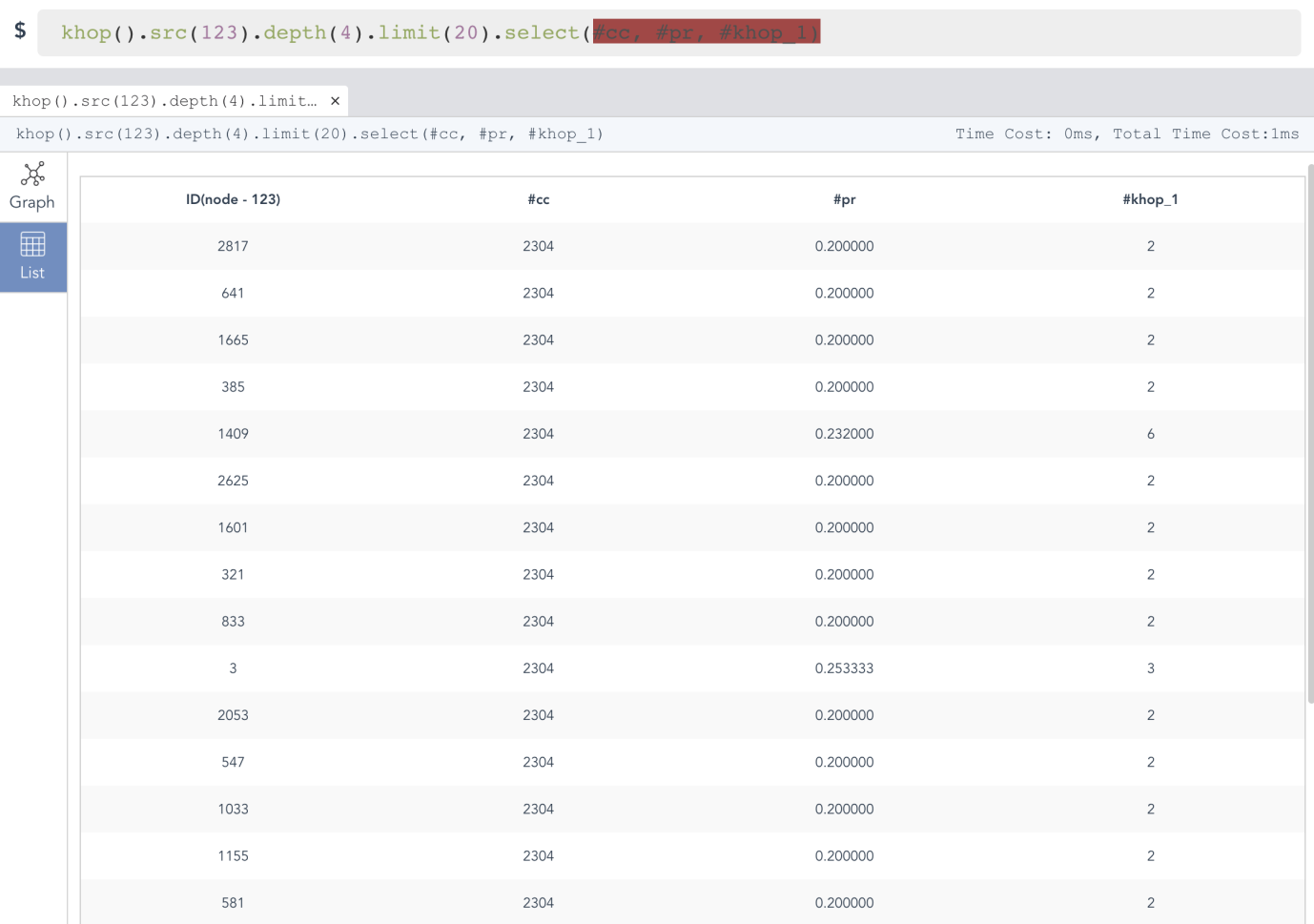
Diagram-10-1:在嬴图Manager中以表格的方式展示结果列表
上图 Diagram-10-1中,khop() 操作返回的是从初始顶点出发经过 depth() 限定的深度搜索后返回的第K层的邻居的集合,select() 的使用允许你选定需要具体返回的属性。
下图中展示的是类似的操作在嬴图CLI中返回的结果示例。注意下图中的时间有两个维度,引擎时间和全部时间,其中引擎时间是内存图计算引擎的运算耗费时间,而全部时间还包括一些持久化存储层的数据转换的时间。
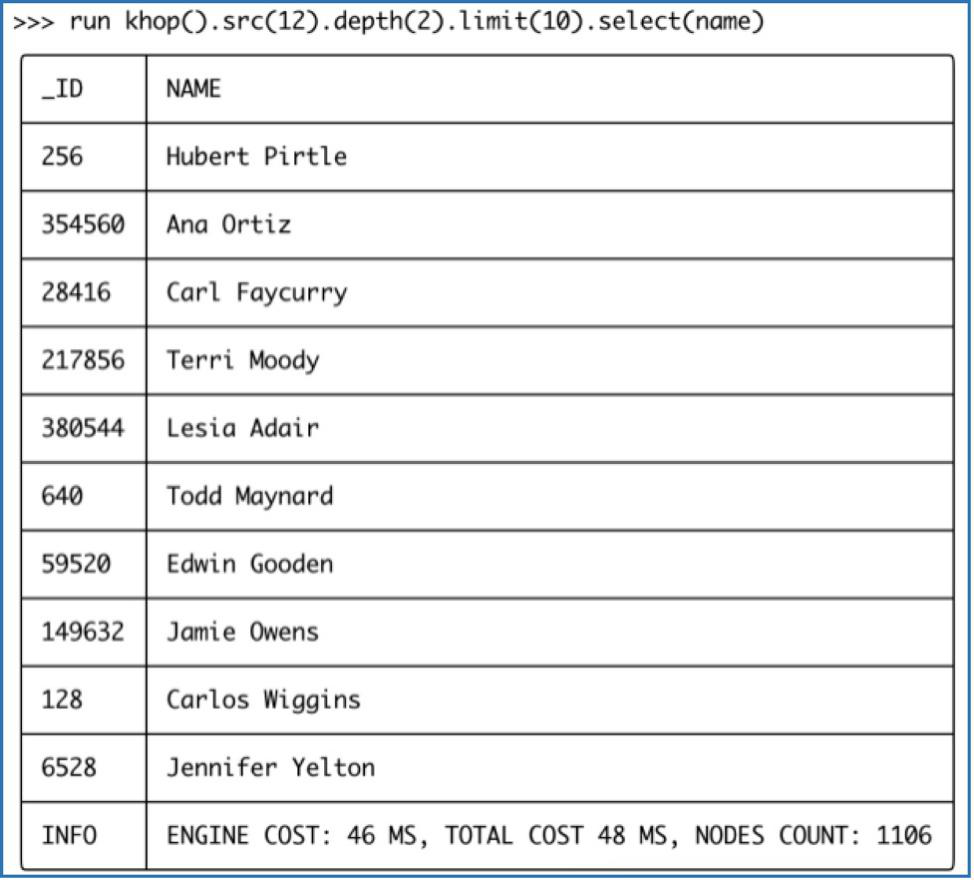
Diagram-10-2:在嬴图CLI中以表单的方式返回结果集
- 强大的基于模板的全文搜索。
如果一个数据库系统中不能支持全文搜索,那么我们很难能称其为完整的数据库。在图数据库支持全文搜索并不是一个全新的事情,例如老牌的图数据库 Neo4j 中通过集成 Apache Lucene 的全文搜索框架,让用户可以通过 Cypher 语句来对顶点(及其属性)进行全文本搜索。在嬴图数据库中我们并没有采用开源的 Apache Lucene/Solr,其中一个很重要的原因是性能落差,在我们看来 Lucene/Solr 的架构的性能要指数级的低于嬴图的核心计算引擎(另外一个次要的原因是这种开源的框架中依然存在着不可预知的一些问题,在生产环境中一旦暴露,修复起来非常困难,这个或许可被看做是开源的一个重大迷思)。
在UQL中完成面向顶点的全文搜索,只需要下面这句简单的查询语句:
find().nodes(~name:"Sequoia*").limit(100).select(name,intro)
这句UQL返回的是找到 100 个包含“红杉”字样的顶点,并返回它们的 name 和 intro 属性。这个查询非常类似于传统数据库中的面向某张表的列信息查询。同样的,也可以针对边来进行查询,例如下面:
find().edges(~name:"Love*").limit(200).select(*)
找到图中所有的边上的 name 属性中存在“爱情“字样的关系。
当然,如果我们的全文检索只是停留在点、边查询,那么这就略显单薄了。在嬴图数据库中,我们创造性的发明了基于模板匹配的全文本查询——例如,模糊的搜索从“***红杉***”出发到“***招银***”的一张关联关系网络,网络中的路径搜索深度不超过 5 层,返回 20 条路径所构成的子图。注意:这个搜索时从模糊匹配顶点出发,到达模糊匹配的另外一套顶点!
t().n(~name: "Sequoia*").e()[:5].n(~name: CMB*").limit(20).select(name)
如果不用上面这句简单得不能再简单的UQL,你能想象如何用其它 SQL 或 NoSQL 语言来实现吗?假设我们在一个工商数据集之上,在天眼查、企查查做类似的查询,你要先找到名字中包含有红杉或招银字样的公司,然后再分别的对每一家公司的投资关系进行梳理,你需要查清楚每家被投公司的合作、竞争、董监高等关系,然后再慢慢梳理出来是否能在 5 步之内关联上名称中包含红杉字样的一家公司和包含招银字样的另一家公司。这个操作绝对的是让人疯狂的,你可能需要花费数天的时间来完成,或者能够通过写代码调用 API 的方式来“智能”化的实现。无论如何,你很难在下面两件事情上击败UQL:
- 效率和时延(Efficiency and Latency):一言以蔽之实时性!
- 准确率和直观度(Efficacy and Accuracy):直观、易读、易懂
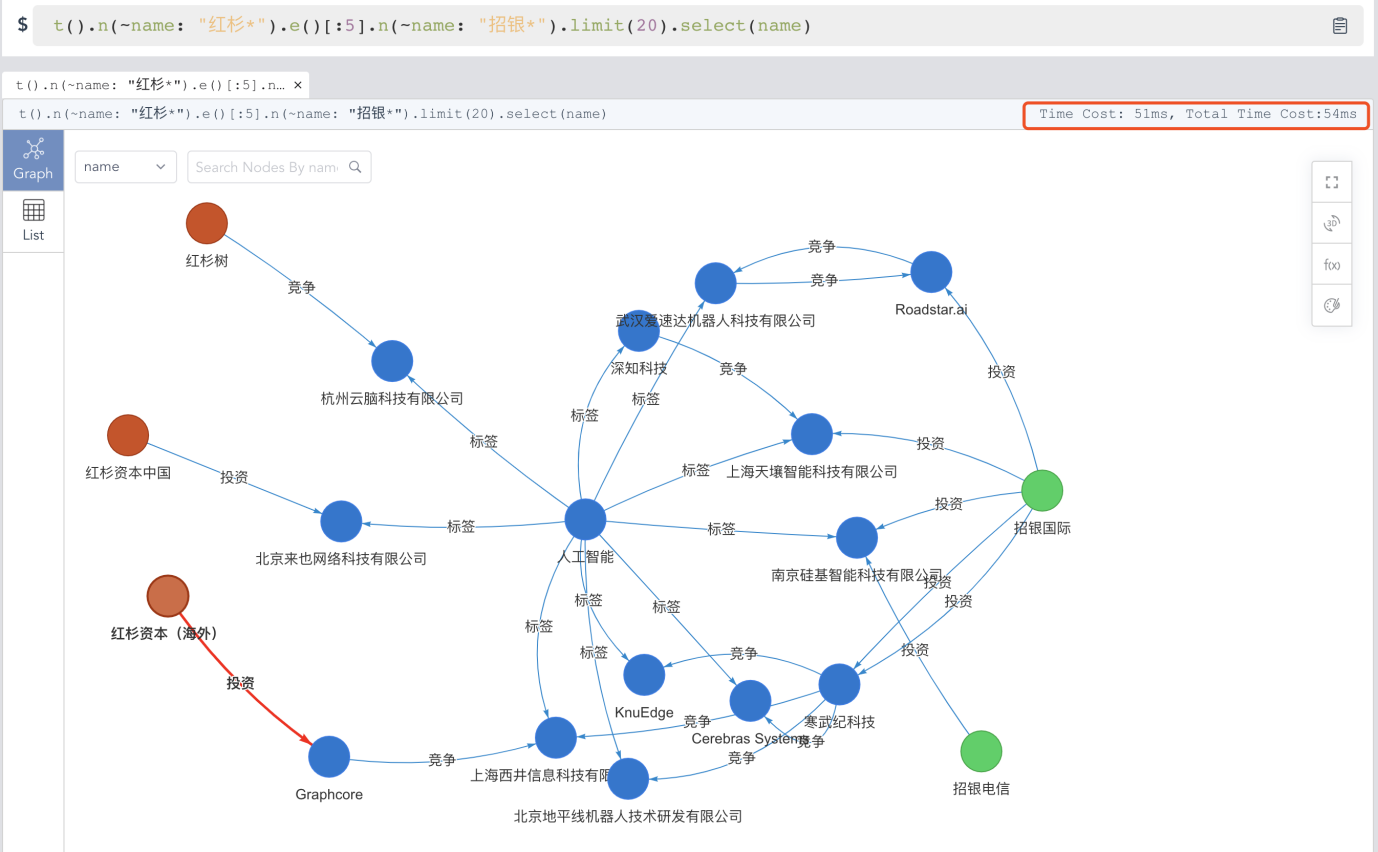
Diagram-11:实时的基于模板查询的全文搜索(嬴图Manager)
在 Diagram-11 中,这个看起来简单而又实际上非常复杂的查询操作仅仅耗时 50ms!这种复杂查询的效率性是前所未有的。如果读者知道有任何其它数据库系统可以在更短的时间内完成同样的操作,欢迎联系我们深度交流。
一门先进的(数据库)查询语言的优美感,不是通过它到底有多复杂,而是通过它有多简洁来体现的。它应该具备这样的一些通性:
- 易学、易懂(Easy to Learn,Easy to Understand)
- 高性能(Lightning Fast):当然,其实这个其实取决于底层的数据库引擎!
- 系统的底层复杂性不应该暴露到语言接口层面(System Complexity Shielded-Off)
特别是上面的最后一点,如果读者对于 SQL 或 Gremlin 或 Cypher 或 GraphSQL 当中复杂的嵌套逻辑心有余悸的话,你会更理解下面的这个比喻:当古希腊神话中的泰坦 Atlas 把整个世界(地球)抗在他的肩膀上的时候,世界公民们(数据库用户)并不需要去感知这个世界有多沉重(数据库有多复杂)。
- 复杂的图算法。
图数据库相比其他数据库而言的一个明显的优势是集成化的算法功能支持。图上有很多种算法,例如出入度、中心度、排序、传播、连接度、社区识别、图嵌入、图神经元网络等等。随着商用场景的增多,相信会有更多的算法被移植到图上或者被发明创造出来。
以鲁汶社区识别算法为例,这个算法出现的时间仅仅 10 几年,它得名于它的诞生地——比利时法语区的鲁汶大学(Louvain University)。它最初被发明的目的是用来通过复杂的多次递归遍历一张由社交关系属性构成的大图中的点、边来找到所有的顶点(例如人、事、物)所构成的关联关系社区,紧密关联的顶点会处于同一社区,不同的顶点可能会处于不同的社区。在互联网、金融科技领域,鲁汶算法受到了相当的重视。下面这行UQL语句完成了鲁汶算法的调用执行:
algo().louvain({phase1_loop:5, min_modularity_increase:0.01})
在图数据库中,调用一个算法与执行一个 API 调用是比较类似的,都需要提供一些必须的参数。上例中,用户仅需提供最少两个参数就可以执行鲁汶。当然,可选的,用户可以设定更为复杂的参数集来优化鲁汶算法,因篇幅所限,本文在此并不做过多的展开描述,对此感兴趣的读者可以参考相关文档。
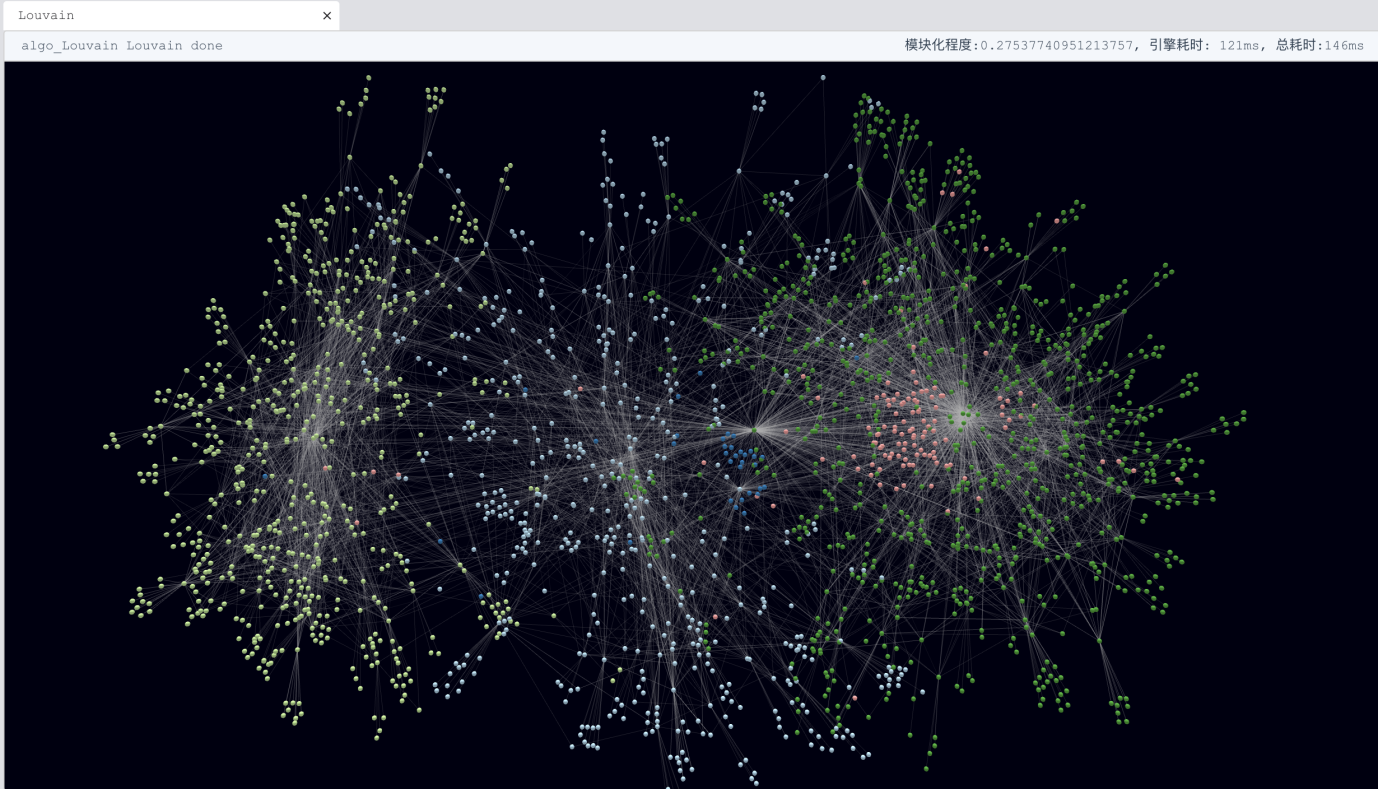
Diagram-12:实时的鲁汶社区识别算法及Web可视化(嬴图Manager)
注:原生的鲁汶社区识别算法的实现是串行的,也就是说它需要从全图中的所有顶点出发,逐个顶点、逐条边的去进行反复的运算,试想在一张大图中(千万顶点以上),这个计算的时间复杂度绝对的是要以 T+1 来衡量的。例如在 Python 的 NetworkX 库中,对一个普通的(几十万-几百万顶点)图数据集进行鲁汶运算要耗时数个、数十个小时,但是在嬴图数据库上面这个计算的耗时通过高度的并发被剧烈的缩短到了毫秒-秒级!在这里,我们探讨的不是 10 倍- 100 倍的性能超越,而是成千上万倍的性能提升!如果读者觉得我们给出的案例只是天方夜谭&痴人说梦,或许你应当重新审视一下你对于数据结构、算法以及它们的最优工程实现的理解了。
UQL中还支持很多功能强大的操作,上面的 5 个例子只是起到了一个抛砖引玉的效果,笔者希望它们能揭示UQL的简介性,并唤起读者去思考一个问题:你到底是愿意去绞尽脑汁的书写成百上千行的 SQL 代码,并借此杀死你我他的大量脑细胞来读懂你的代码呢?还是考虑用更简洁、方便却更加强大的图语言呢?
关于数据库查询语言,我们认为:
- 数据库查询语言不应该只是数据科学家、分析员的专有工具,任何业务人员都可以(并应该)掌握一门查询语言。
- 查询语言应当便于使用,所有数据库底层的架构、工程实现的复杂性应当对于上层的用户而言是透明的!
- 最后,图数据库怀有巨大潜力,在未来的一段时间内会大幅的替代 SQL 的负载,有一些业界顶级的公司,例如微软和亚马逊已经预估未来 8-10 年间,会有 40-50% 的 SQL 负载会迁移到图数据库之上完成。让我们拭目以待。
有些人认为,包括一些知名的投资机构和行业“专家”,关系型数据库和 SQL 永远也不会被取代。这种看法禁不起推敲。如果我们稍微回顾一下不是很久远的历史就会发现,关系型数据库在 70-80 年代取代了导航型数据库,它已经称霸了行业 40 年了,但是越来越多的业务场景,SQL 类型数据库或大数据系统捉襟见肘。它们的最大的弊端有 3 个:
- 性能与效率:低,特别是无法应对复杂查询,太多 T+1 场景了。开发周期长。
- 灵活性:差,基于二维表的数据建模,天然的无法高效、灵活地描述业务场景。业务变动后,调整 SQL 存储进程代码过于复杂、耗时、成本高的问题,无解。
- 可解释性:差,越复杂的场景 SQL 代码越复杂,逐步演变为拖累业务拓展。
而以上这 3 点,恰恰都是图数据库的优势。