作者:孙宇熙 & 陈俊文
(本篇摘译自 Designing Highly Scalable Graph Database Systems without Exponential Performance Degradation - Understanding Distributed Native Graph Processing 一文,该文被 ACM Digital Library 美国计算机学会数字图书馆收录。)
当今图数据库系统面临的一个主要挑战,就是怎样才能兼顾存储与计算两方面性能。很多图系统厂商选择了牺牲查询速度来获得存储的可扩展性,得到的系统虽然能使用众多实例存储大量数据,但无法提供足够的图计算能力来实时深入地对动态图数据进行穿透。像K邻搜索、全图最短路径这类计算,表面上直观易懂,实则牵涉大量针对图数据的深度遍历,放在一个典型的 BSP(Bulky Synchronous Processing)系统上运行会引发多个分布实例之间的大规模数据交换,从而导致严重的的延迟。
真实世界中的图数据往往要么非常密集、含有超级节点(例如金融交易数据),要么数据量巨大,需要分区、分片进行水平扩展,同时不能以性能的指数级下降为代价。上面举例的分布式图系统显然不是为了真实世界的需求而设计的,它们“只能存不能算”,我们称其所达到的可扩展性是无效的。
如何才能获得有效可扩展的图系统呢?这需要先了解图数据库可扩展性的发展历程。图1展示了图数据库从单机实例到水平可扩展的分布式集群的进化路径。

图1:分布式(图)系统的发展
我们将真正称得上有效可扩展的图系统架构分为三类,分别介绍它们的特性。
第一类:分布式共识 & HTAP
第一类分布式图系统可以从分布式共识集群谈起。分布式共识集群支持RAFT协议,并且为了便于选出集群leader,通常含有3个或更多奇数个实例。例如,Neo4j的Enterprise Edition v4.x支持原始的RAFT协议,只用一个主实例处理工作负载,而其他两个实例仅同步来自主实例的数据。
一种较实用的处理工作负载的方法是使用增强的RAFT协议,让所有实例以负载均衡的方式工作。例如,让主导实例处理读写操作,其他实例除了同步数据之外还可以处理读操作,仍然保证了整个集群的数据一致性。
一种更复杂的方法是HTAP(混合事务和分析处理),集群leader处理TP操作和AP操作,而follower处理各种AP操作(图算法、路径查询等)。图2所示的就是嬴图的HTAP图系统架构。
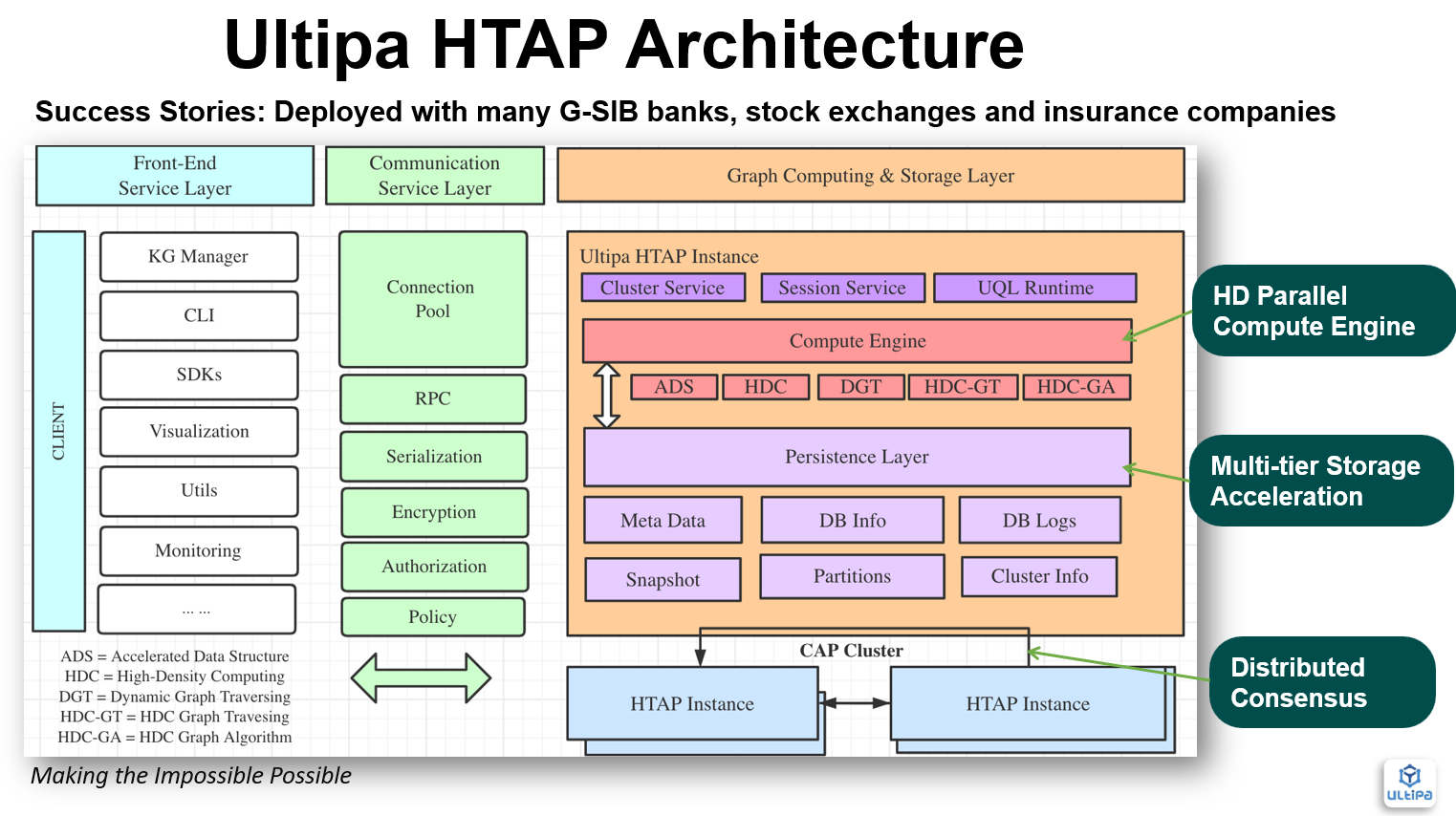
图2:嬴图的HTAP架构
分布式共识系统的利弊总结如下:
- 硬件使用量低
- 数据一致性好
- 复杂、深层查询高性能
- 仅限于垂直可扩展性
第二类:Grid
第二类分布式图系统包含多个集群,由name server担任客户端和服务器端之间的代理角色,在实例间对查询进行分配、对数据进行转发与聚合,实现针对多实例的联邦查询(Query-Federation)。这类分布式图系统的图分割工作通常是基于时间序列(水平分割)或业务逻辑(垂直分割)人为地进行的。
例如,将一年之内发生的信用卡交易数据(边)按月划分为12个图集,再将这些图集存储到不同的集群(3个实例)中。这种按时间划分边数据的逻辑是由数据库管理员事先定义好的,通过切点(node-cut)的方式进行图分割,是一种基于时间序列、同时又支持绝大多数业务逻辑(按月计算)的分割方式。在不涉及跨集群计算时(即不会发生数据迁移),该类图系统与HTAP系统具有同样良好的查询性能。
图3展示了一种Grid体系架构,相比于图2所示HTAP架构,该架构额外增加了name server和meta server两个组成部分。从设计上,所有查询都由name server进行代理,同时name server与meta server协同工作以确保整个系统的弹性。各集群则在很大程度上与HTAP架构相同。
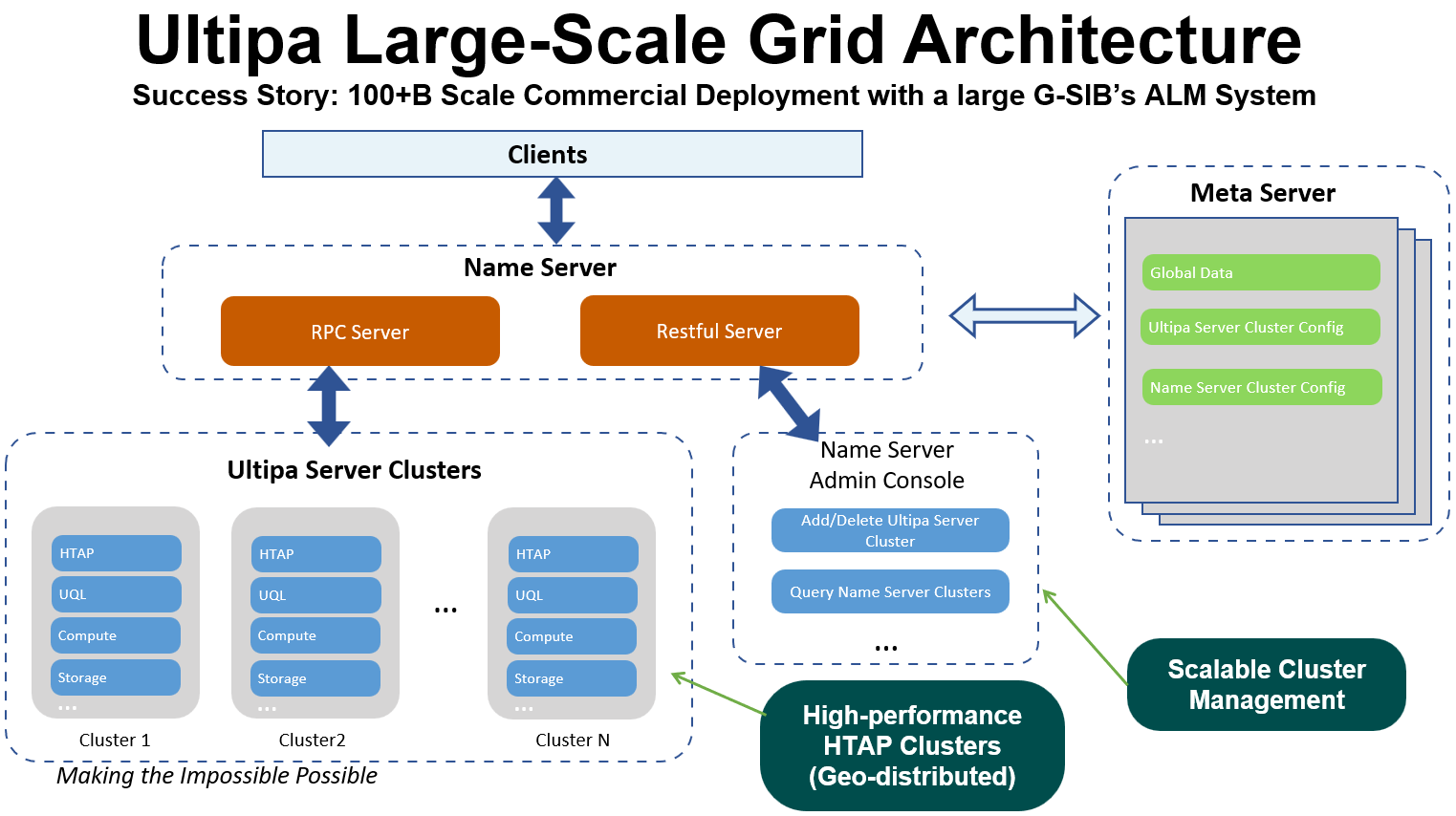
图3:Grid体系架构(Cluster、Name Server、Meta Server)
值得注意的是,由于会受到数据迁移的影响(类似于map reduce的工作原理),Grid系统在进行图算法等跨集群操作时的性能并不尽如人意。
我们将Grid架构设计的利弊概括为:
- 保留了HTAP体系结构的所有优缺点
- 同时兼顾了可扩展性与性能
- 需要管理员(DBA)干预图分割
- 绝大多数业务逻辑需首先在各集群上执行得到临时结果,发送给name server进行聚合后再返回到客户端
- 业务逻辑必须与图分割、图查询的逻辑相适配
第三类:Shard
第三类分布式图系统延用了第二类系统中的name server和meta server,但其数据分割的方式并非人为制定,而是由name server根据自动收集的统计信息(Automatic Statistics Collection)进行判断,并根据系统的使用情况做出实时调整。
此类架构的终极目标是放弃对name server算力的依赖,让每个分片(shard server)将充分担负起计算任务。该架构在数据迁移方面以最小I/O成本为原则进行优化,在跨分片计算时让少量数据向大量数据迁移,只在name server上进行最少的数据整合。
图4展示了一种分片体系结构。在这种对等(peer-to-peer)的体系结构中,shard server和name server都具有计算能力,同时shard server还负担了分区存储。
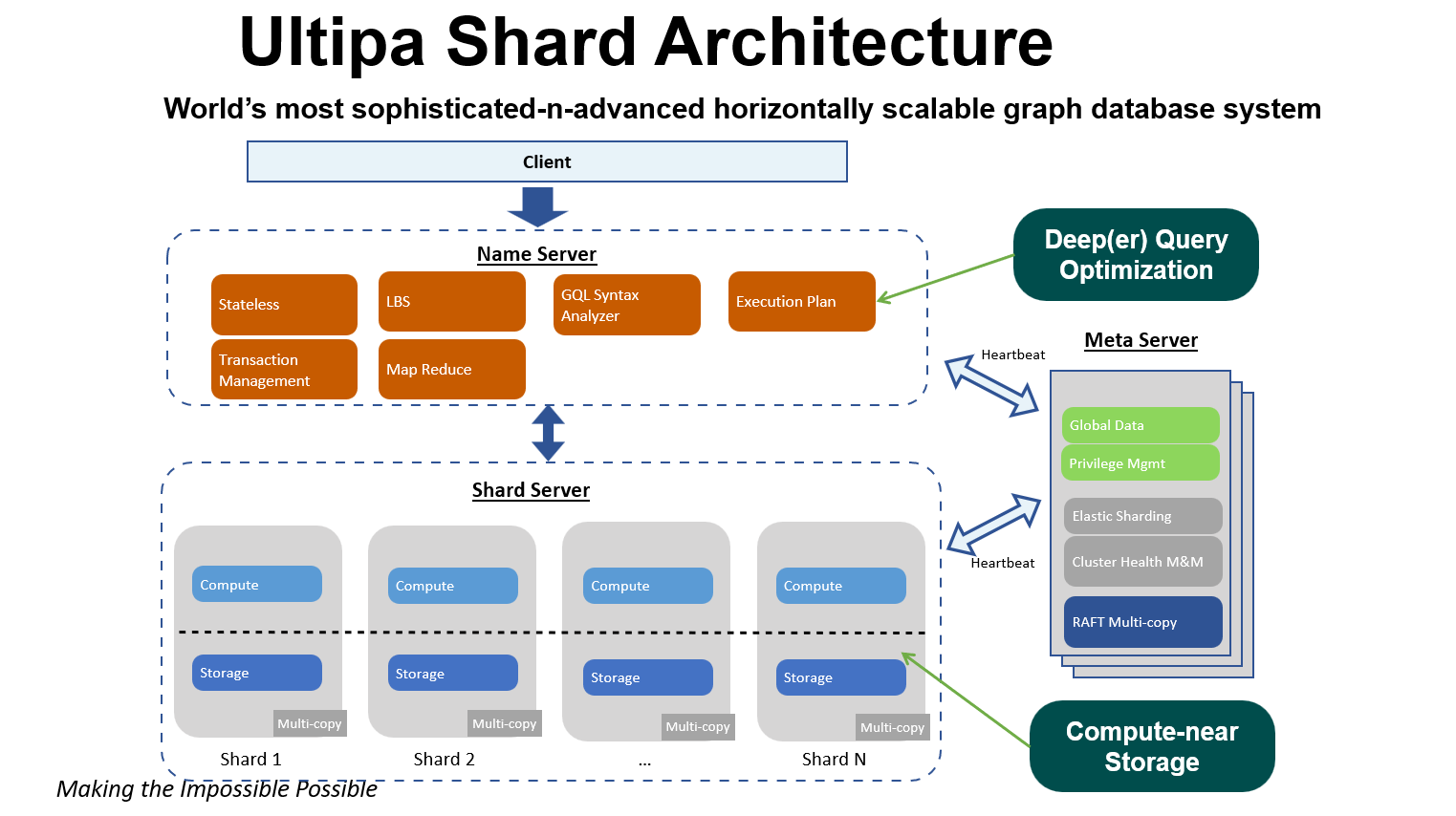
图4:Shard体系架构(Shard Server、Name Server、Meta Server)
针对图数据展开应用的Shard系统具有以下特征:
- 无限可扩展
- I/O性能高
- 跨分片的查询性能低(指数级)
- 图查询的调度(计划和优化)复杂
应用场景
为真实的商业场景设计分布式图系统时,需进行有针对性的优化以获得令人满意的性能。下面表格给出了以上3种分布式图系统的特征及其具体要求。
表:三种分布式图系统及其业务场景
|
类型 |
特征 |
业务场景 |
|
高密度并行计算(HDPC) |
· 实时/在线读写 · 深度查询 |
· 实时交易拦截 · 反欺诈 · 异常检测 · 实时推荐 · AI/ML · 其他实时场景 |
|
HDPC & Shard |
· 读写分离 · 分片/离线数据的弹性处理 |
· 知识图谱 · 大语言模型(LLM) · 指标计算 · 审计 · 云数据中心 |
|
Shard |
· 元数据处理 · 浅层(1~2步)邻居查询 |
· 归档 · 数据仓库 |
一个真正能胜任的分布式图系统还需要考虑很多因素,如成本、主观偏好、设计理念、商业逻辑、复杂性容忍度、服务能力等。我们很难笼统的说一种架构绝对优于另一种架构。但长远来看,图体系架构的发展方向显然是从上面所介绍的第一类到第二类、最终到第三类;只是就目前来看,前两类体系已经能满足绝大多数客户场景的需求,并且人类的智力水平(DBA干预)暂时足以帮助实现性能和可扩展性之间的平衡(第二、三类)。
(更多信息请点击阅读原论文。)