图数据库传统上被认为是 NoSQL 数据库的子集(相对于以 SQL 为中心的数据库——众所周知,自 1980s 成为主流的关系型数据库,至今还在各种大小公司的 IT 环境中广泛应用)。图的核心概念是图论,世人了解图论,一般是通过知名数学家 Leonhard Euler 在 1735-1736 年发表的哥尼斯堡七桥问题。在大数据计算领域,图论有许多应用场景,例如导航、地图染色、资源调度、搜索和推荐引擎。但在数据库领域,图论却甚少提及,直到最近 10 年——发明互联网 40 年后——随着图数据库和图计算的发展才开始重新受到重视。
近半个世纪,有很多图计算的算法问世,从知名的 Dijkstra 算法(1956 年——图的最短路径问题),到 Google 创始人 Larry Page 在 20 世纪末发明的 PageRank,以及更复杂的各类社区发现算法(用于检测图之间的关联)。简而言之,今天许多伟大的互联网公司都是基于图计算的尖端技术而诞生的,例如:
- 谷歌:PageRank 是一种大规模页面(或链接)排序的算法,可以说,早期谷歌的核心技术就是一种浅层的并发图计算技术。
- 脸书:脸书的技术框架的核心是它的 Social Graph,即朋友关联朋友再关联朋友。如果你曾经听说过“六度分隔理论”——脸书建立了强大的社交关系网络,在任意两个人之间,只要通过 5 或 6 个人就可以建立联系。脸书开源了很多东西,但是这个核心的图计算引擎与架构从未开源过。
- 推特:推特是美国(或世界领域)的微博(你也可以说推特在中国的版本叫微博),它曾经在 2014 年短暂在 Github 上面开源了 Flock DB,但随后就下线了。原因很简单,图计算是推特的商业与技术核心,开源模式没有增加其商业价值——换句话说,任何商业公司的核心技术与机密如果构建在开源之上,其商业价值形同虚设。
- 领英:领英是专业职场社交网络,最核心的社交特点是推荐距离你 2 层至 3 层的专家,提供这种推荐服务必须使用到图计算引擎(或图数据库)。
- 高盛集团:如果你能回忆起 2007-2008 年爆发的世界金融危机中,莱曼兄弟公司破产,当时高盛集团首先全身而退,背后的真实原因是高盛集团应用了强有力的图数据库系统—— SecDB,它成功计算并预测到即将发生的金融危机。
- 贝宝,易趣和许多其他金融或电子商务公司:对于这些技术驱动的新型互联网公司,图计算并不罕见——图的核心竞争力可以帮助他们揭示出数据的内部关联,而传统的关系型数据库或大数据技术实在是太慢了,它们在设计之初就不是用来处理数据间的深度关联关系的。
- 当代图计算的概念是互联网之父蒂姆伯纳斯李发明的(这一点仍存有争议),他创造了语义网络(Semantic Web)的概念,他建议整个互联网应该被视为一张通过所有链接编织的巨大的图,每条链接指向一个嵌入内容的网页,在图中的所有入口相互参照,进而形成全球范围的互联网。语义网络的概念形成于上世纪 90 年代初,但第一个工业级图系统在很多年后才逐渐变成现实。起初学术界的研究人员制定了 RDF 规范(2004 年产生了第一个版本,被 2014 年 1.1 版本的 W3C 所采纳),它是最初的元数据模型(Meta-data),过去通常被用来进行知识管理。RDF 默认的查询语句是 SPARQL。但 RDF 存在的问题是复杂、冗长,很难维护——很快,开发者就不喜欢它了。相形之下,你更喜欢 XML 还是 JSON?可能是 JSON,它更简单,毕竟轻量和快速是这个时代的主旋律。
- 相同的时间与背景催生了 LPG——被冠以图的性能,直到语义网络被发明的 20 年后,其中最知名的一个是 Neo4j,一个由瑞典团队成立的公司在 2011 年发布了第一款 LPG(Labeled Property Graph)图计算产品。在这个领域也出现了不少竞争者和新的玩家,他们的名单如下:TitanDB(2016 年退出市场),阿帕切的 TinkerPop,JanusGraph(Titan 的衍生品),亚马逊的 Neptune,百度的 HugeGraph(已经停止维护),谷歌的 GraphD(和DGraph)...
大数据历史
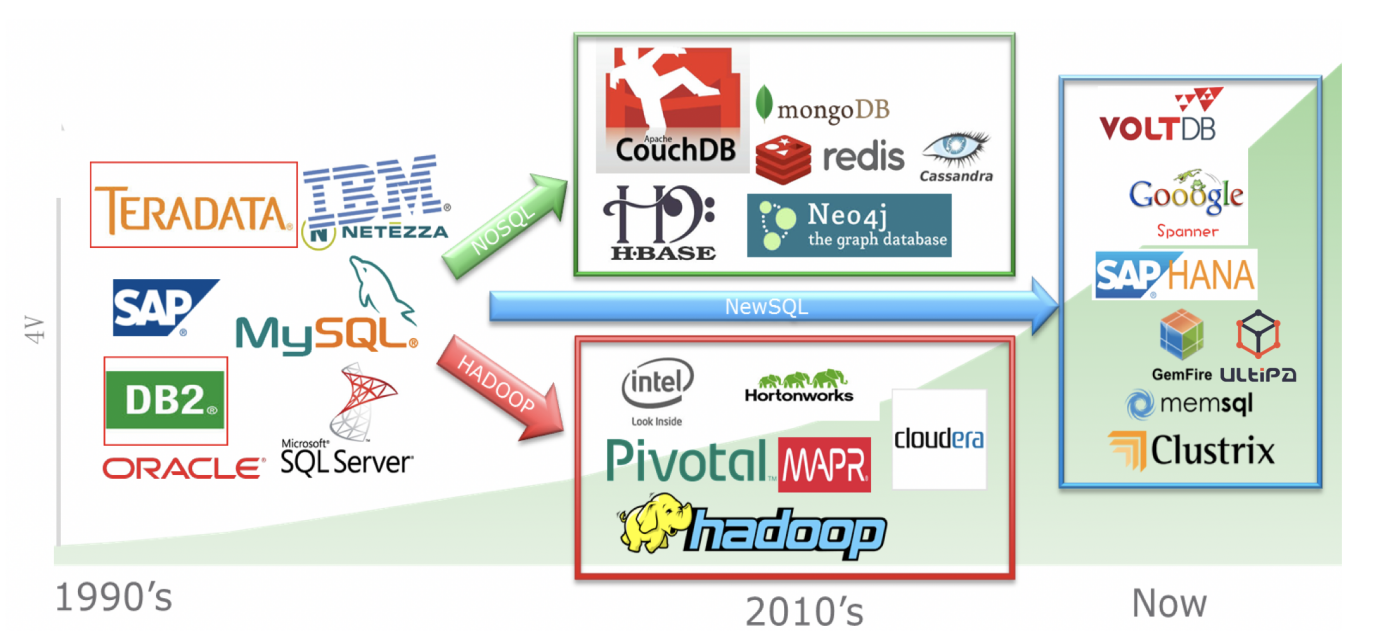
发展趋势:数据 → 大数据 → 快数据 → 深数据
图数据库(或者称为图系统,图平台,图解决方案或图引擎,所有这些其实都是指一件事——以图为核心,围绕图和在图中进行计算)被认为是 NoSQL 的至宝,特别是在这个数据互联的时代,需要在最短时间深度关联挖掘出数据的最大价值。图就是非常理想的解决方案,除此以外,你无法从其他类型的 NoSQL、大数据框架或关系型数据库找到实时深数据关联的解决办法。键值存储、 列数据库,Hadoop 分布式计算或 Sparks 集群计算、文档数据库在处理数据关联问题上都是不完善的。正是以上提到的这些瓶颈和挑战,才使得图数据库市场得以诞生并蓬勃发展。
为什么是图?
1. 图是未来! 2. 图是极具挑战的技术! 3. 我们实现这种代表未来的技术。
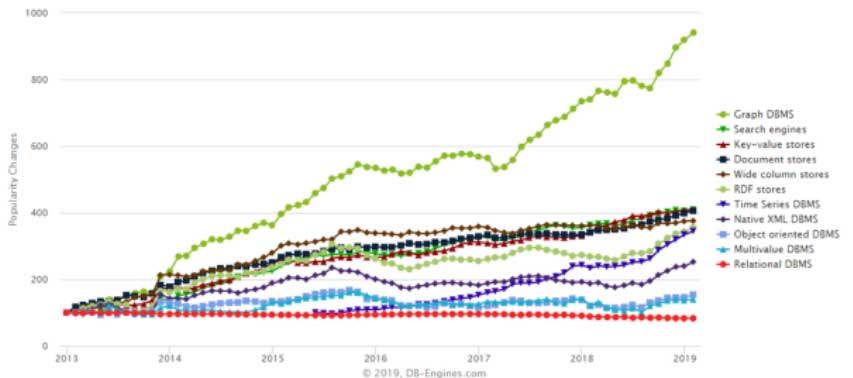
2013 年 1 月后各类数据库发展动态
从上图中可以看到,DB-Engines.com 追踪了从 2013 年后所有类型的数据库,在过去的 6 年间(2013 年一季度至 2019 年一季度),图数据库(绿色点线标示) 比其他类型的数据解决方案增长率快 3-4 倍,包括搜索引擎、键值存储、RDF 存储或关系型数据库管理系统,关系型数据库市场都相对增长平缓。据推测,在未来 10 年,越来越多的关系型数据库系统将被图数据库取代(一些说法预测将有 40-50% 的 SQL 负荷转换为图数据)。此外,行业巨头例如微软与亚马逊都预测,世界范围内,未来 8-10 年使用图计算的增长率将会达到 50-100 倍。它意味着使用图计算系统的公司数量和规模的增长将达到惊人的 5000-500000 倍。
崭新的互联时代
万物关联时代的图计算
通过深度挖掘不同来源的数据,网络化分析出数据的最大价值!
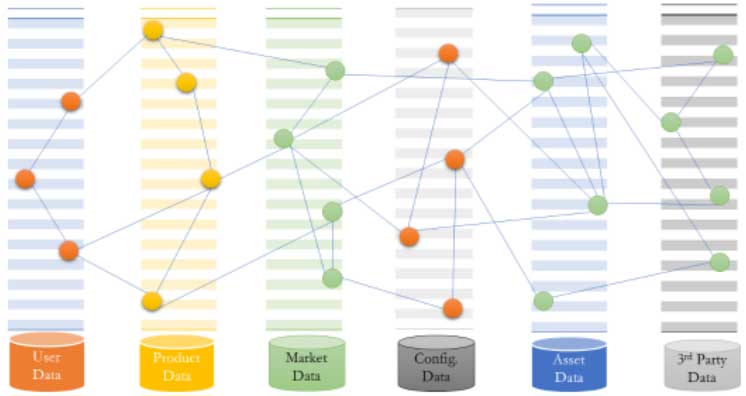
用图进行的基于各种数据存储的网络分析
如果你还怀疑关系型数据库的局限,那么请想象一下,使用关系型数据库管理系统,你能够解决以下问题吗:
- 如何找到一个人朋友的朋友的朋友?
- 如何(实时)找到一个账户与多个黑名单账户之间的联系?
- 如何在规定时间内判断两个账户之间的交易(或交易记录)是否正常?
- 一个供应链网络中,如果一个北美的制造厂/工厂停工,将会给南韩的百货商场旗舰店带来什么样的影响?
- 在货运网络中,如果一个网络节点停运(下线),滑板效应是什么(影响的范围有多大)?
- 在大健康领域,如果一个用户提交他的电子病历和健康档案,是否可以提供实时个性化的重大疾病的保险推荐?
- 在反洗钱的场景里,我如何知晓一个账户持有者把他的资金通过多层中间人的账户转账后,最终再重新汇入他自己(或另外)的账户中?
- 今天的搜索引擎只可以进行一维的,基于关键字的搜索,例如你输入:“牛顿与成吉思汗”,不会返回任何有意义的、深层思考的结果。
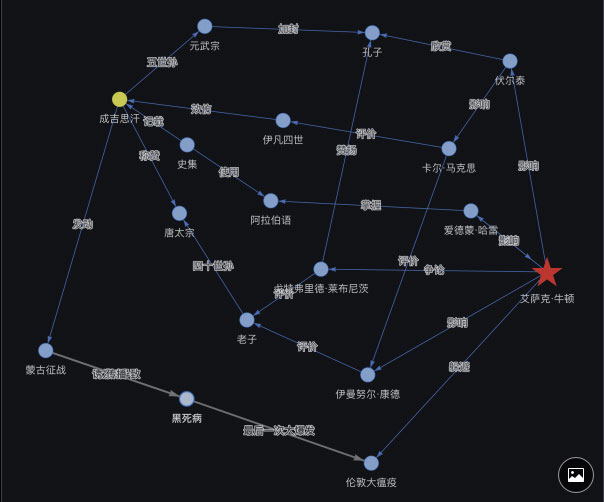
以上 8 个问题仅仅是列举了今天传统数据管理系统(甚至是 NoSQLs)或搜索引擎无法完成的众多挑战中的一小部分。但在实时图数据库和图计算引擎的帮助下,可以实时地在不同数据间找到联系。举例来说,基于百科全书的知识体系而构建的知识图谱数据集中(一张大图,下图中的顶点是一个个的知识点,而边则是知识点之间的关联关系),嬴图引擎可以实时计算出以下路径:
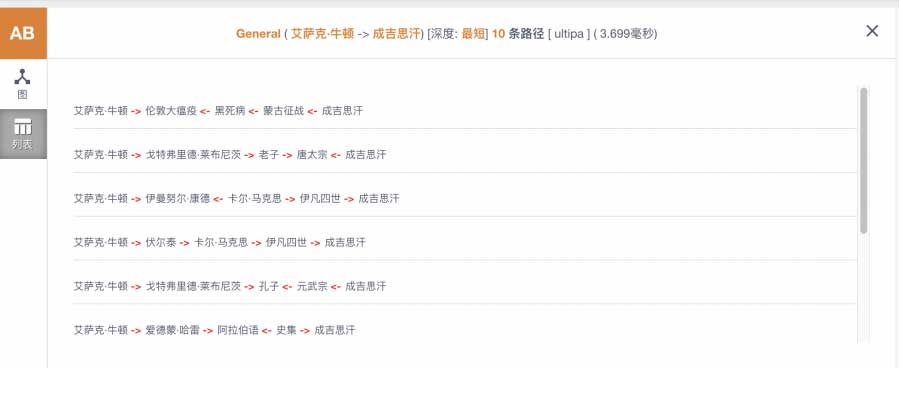
实时查找牛顿和成吉思汗之间的最短路径-列表视图
实时查找牛顿和成吉思汗之间的最短路径 - 2D视图
与传统的搜索引擎不同,当你搜索时,你所期待的返回结果不再是单一的网页、连接排序,而是更为复杂、多边甚至全面的关联关系,搜索引擎不会返回为空、答非所问或无实际意义的答案,在实时图数据引擎的支撑下,它可以返回最优的、人脑都无法企及的智能路径!如果你仔细观察上图中的这些路径,其中一条(图形模式下以高亮显示位于图形下方的灰色路径),可以用以下方式解读:
- 成吉思汗开始对欧洲进行征战(13 世纪初)
- 蒙古侵略欧洲导致黑死病的爆发
- 黑死病的绝唱(17 世纪):伦敦大瘟疫
- 当时就读于剑桥大学的牛顿为躲避伦敦大瘟疫回到了家乡(随后发明了微积分,光学和牛顿定律...)
所有过程在图数据库(嬴图引擎)支撑下都是实时完成,返回最优(注:不 一定是最短)路径。而真正的商业应用场景对路径上的点、边有过滤需求时,则可以调整过滤参数,例如设置相关顶点(或节点)与边的属性等。
如果你是求知欲较强的用户,你可能会尝试扩展到更大范围(深度)的搜寻:
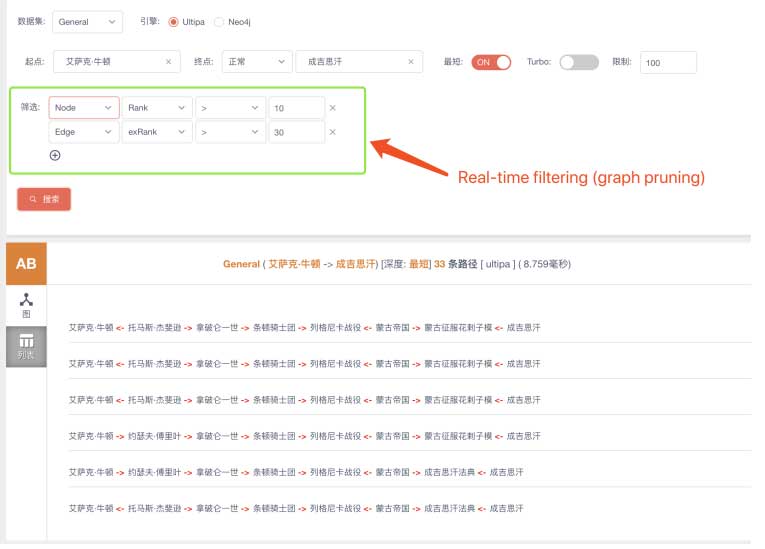
通过图过滤查询进行的实时动态图剪枝
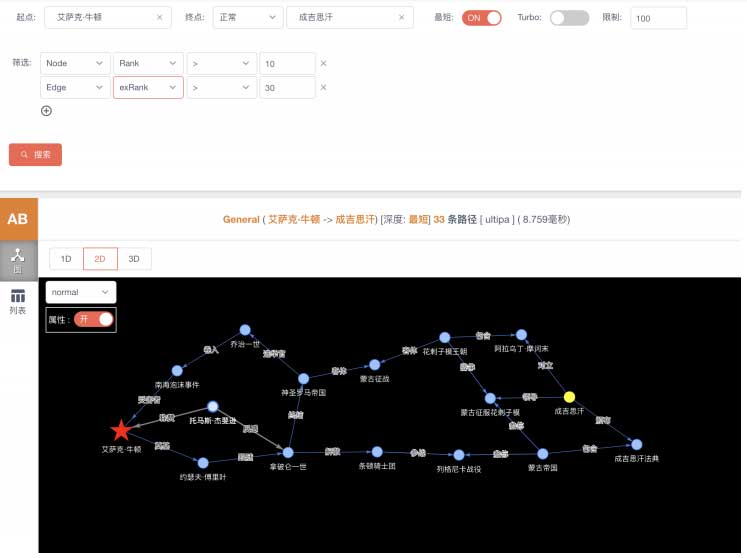
图过滤查询得出的牛顿和成吉思汗之间的路径
另外一个实例是通过数据流追踪进行实时反洗钱监测。下图中最大的红点是资金流出方,经过 10 层的中间人,到达小红点的位置。除非经过 10 层以上的深层挖掘,否则你很难发现数据(资金)的真正流向,和它们背后的真正意图。在图中,你会了解如果少于这个层数,根本无法判断出资金流最终会聚焦。
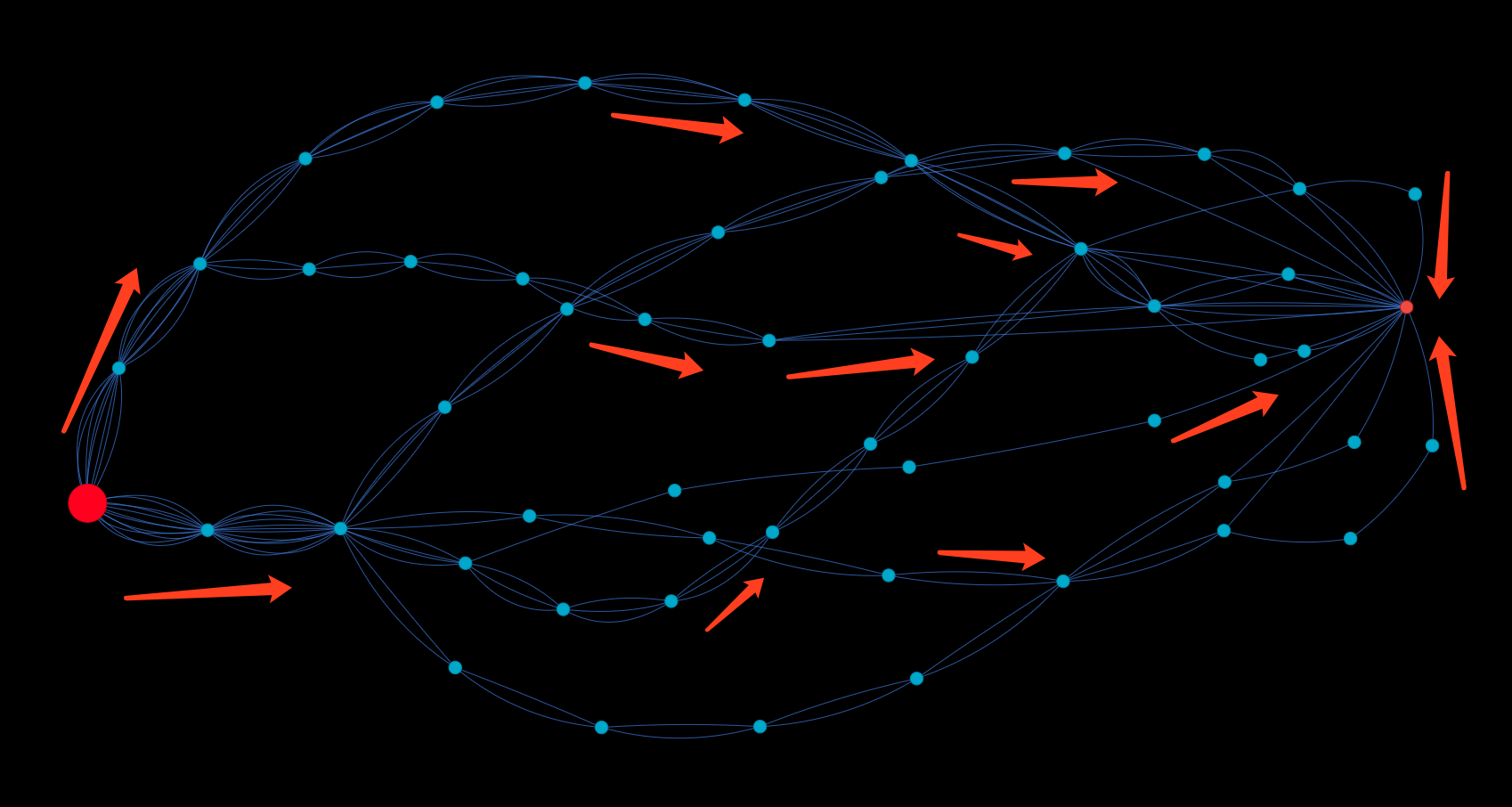
实时资金流追踪
以上例子令人激动,如梦似幻又已经实现,并且意义重大。它揭示了梦想中的聪明特性已经在真实世界的应用中得以实现。处理类似蝴蝶效应的事情非常艰难,它意味着应对大量的数据,更不必说还有实时处理的挑战。当我们谈到从联机分析处理转换为联机在线处理时,大部分逻辑都是面向批处理,但他们不是实时系统,我们可以这样思考:如果实时的图数据库可以把这个过程转变为纯实时呢?进一步讲,如果还无需额外的硬件花销或更高的用户总拥有成本(TCO)呢?这样你可能就会接受这种新的颠覆性技术。
在 2017 年,Gartner 集团提出了一个 5 层的数据分析模型(参看下图)。
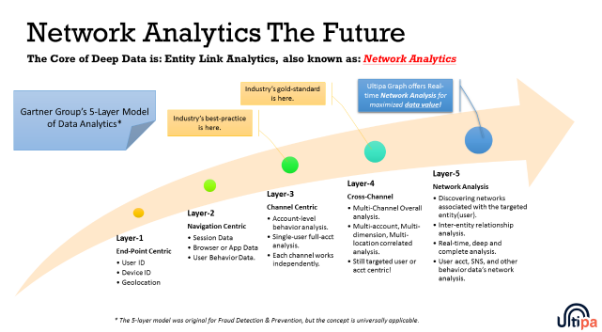
Gartner 集团的 5 层模型 - 网络分析是未来趋势
这个图表中,数据分析的未来在于“网络分析”,或称为实体链接分析,建立这个系统只能依赖图数据库——本文前面部分揭示了其中的原因——图计算系统把数据以网络拓扑结构的方式构建,并搜寻网络内的关联关系,它的效率远超关系型数据库管理系统,后者通过表间的关联(table-join)来进行计算,它可能永远无法完成类似的任务。
数据分析(技术)的发展是商业发展的必然,它提高了数据处理的科技水平。从 第 1 层到 2 层,你可以把它视为数据分析领域内从单机应用到互联应用的提升;第 3 层是渠道中心化数据分析,它经常发生在一个公司的渠道或部门的内部;第 4 层的特点是跨渠道,它要求大型公司内的不同渠道分享数据,从而最大程度挖掘数据的价值,你必须合并各个渠道搜集到的不同类数据,并把他们视为一个整体——由此来进行网络化分析(例如社交网络分析),只有图数据库才能完美实现。
我希望本文这么冗长的背景介绍,能够让您做好准备,从而进入嬴图计算的世界——一个纯实时的图数据库,相对其他友商,它足够强大并且用户友好;从几百倍至几万倍的算力优势;它不会遗漏路径;它具有最优的性价比。简而言之,它用较小的代价实现了足够强大的性能,而且最棒的是,它所赋能的商业蓝图是其他友商所未见的。