图存储,简单说就是专门存图数据的“仓库”,全称叫作“图数据库存储引擎”。它负责将图数据——节点、关系、属性等,以适合图结构的数据格式,存储在磁盘或内存中,并确保数据的一致性、完整性和可访问性,要用的时候能方便取出来。
图存储的基础概念
目前传统数据库存储引擎中最主流的有两大类:基于 B-Tree 的存储引擎和基于 LSM-Tree 的存储引擎。除了这两类,还有许多其他存储方式,比如:
基于文件的,可分为有序和无序两种;
基于堆的(这也是一种文件);
基于哈希桶(hash buckets)的;
基于索引顺序存储(ISAM)文件系统的。
若按照数据存储的排列方式,还能分为行存储、列存储、KV 存储、关联存储等类型,这些不同的存储方式在图存储中也可能根据具体需求被采用。
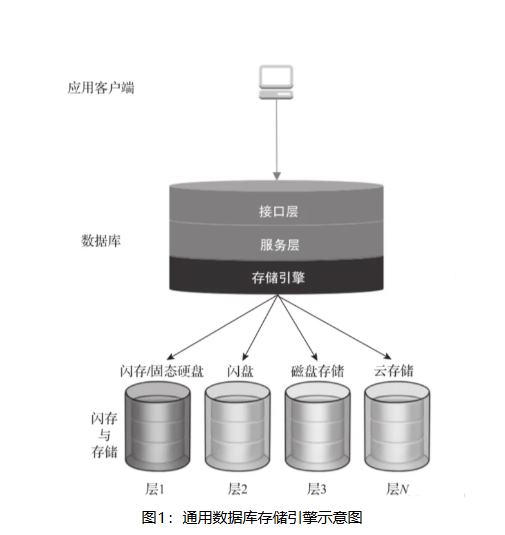
图1:通用数据库存储引擎示意图
图存储引擎是图数据库的 “数据基石”,核心职责是高效存储图的核心元素(顶点和边),并与计算引擎、数据管理等组件协同,确保数据的持久化与事务正确性(ACID)。其原理可从 “存什么”、“怎么存”、“不同场景下的存储逻辑” 三方面拆解:
第一方面:核心存储对象:顶点和边
图的本质是由 “顶点” 和 “边” 构成的关系网络,存储引擎首先要精准捕捉这两类元素的结构特点:
- 顶点:每个顶点可以看作内部元素有着某种规则排列的数组,多个顶点的组合就是一个二维数组。如果考虑到顶点的动态变化(增删改查等涉及读、更新、插入等操作)的需求,向量数组是一种可能的方式。
- 边:比顶点更复杂的 “关系载体”,除了唯一 ID,还需记录起点 ID、终点 ID(明确连接对象)、方向(有向 / 无向)和属性(如权重、时间戳)。用二维数组可存储边的基础信息,但实际中更关注效率:如何少占空间、快速查询(比如 “某顶点的所有邻接边”)、高效维护索引。
第二方面:存储方式:静态与动态场景的分野
存储引擎的设计需适配数据是否变化,两种场景的逻辑大不相同:
- 静态图(数据不变):若顶点和边的数量、属性完全固定(如历史关系图谱),无需复杂设计——可直接复用传统存储方式,比如用磁盘文件按固定格式存储顶点数组和边的三元组(起点、终点、属性),或借助 MySQL 的 InnoDB、MyISAM 等传统引擎,用表结构映射图元素。此时 “存” 的逻辑简单,能满足基本需求即可。
- 动态图(数据常变):商业场景中,数据几乎都在动态更新(新增用户、删除关系等),这就要求存储引擎支持高效的增删改查。此时出现两种核心架构:
非原生图:用传统数据库(如 MySQL、HBase、Cassandra)的表结构存储 ——顶点放 “顶点表”,边放 “边表”。但查询关系时需多表关联,效率极低。比如查 “007 号员工所属部门”,需先查员工表定位 007,再查 “员工 - 部门对照表” 找部门 ID,最后查部门表取名称,多步关联耗时高。
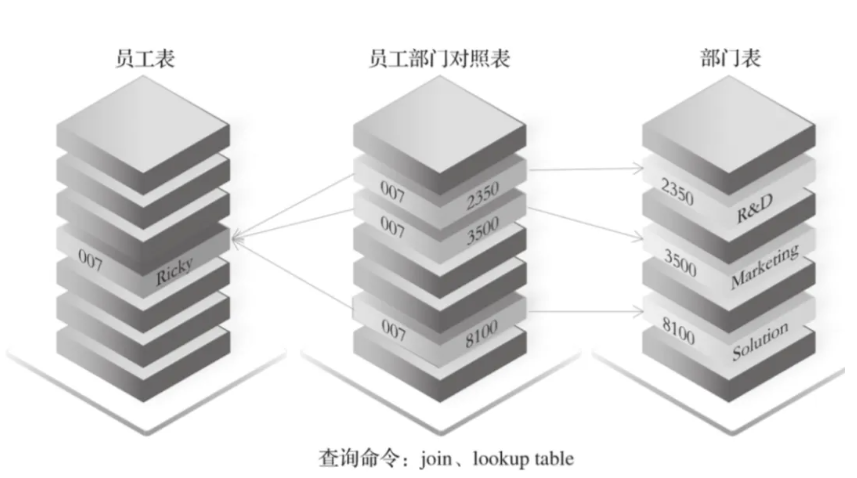
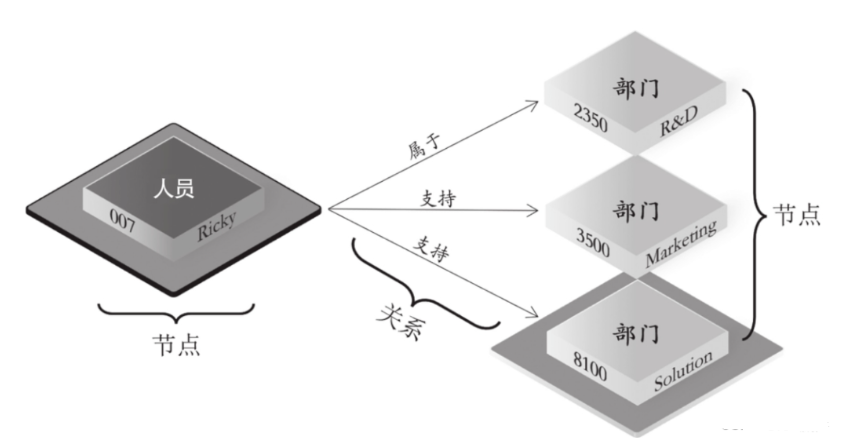
第三方面:与系统组件的协同:不止 “存”,更要 “好用”
图存储引擎不是孤立的,需与计算引擎、数据管理等组件配合,支撑整个图数据库的运转:
· 计算引擎所需的临时数据、索引结构(如加速查询的索引),都基于存储引擎中的顶点和边衍生而来;
· 需保证与计算引擎的数据一致性,比如计算时读取的数据必须是存储引擎中最新的,且操作需满足 ACID(比如 “添加一条关系” 要么完全成功,要么完全失败,避免数据混乱)。
为啥图存储能碾压 SQL?
原生图存储就像盖房子,从地基到屋顶层层递进,每一层都有明确的分工,首先关注元数据,然后是次生数据(辅助数据),最后是衍生数据或组合数据。
第一层:元数据(核心骨架)——是支撑整个结构的基础
· 实体数据(顶点)。如 “人”、“公司”、“银行卡”,每个顶点都有唯一 ID,就像给每个房间编了门牌号;
· 关联关系数据(边)。如 “转账”、“持股”、“关注”,用来连接顶点。
第二层:次生数据(辅助数据)——细节信息——让每个顶点和边更具体
· 实体属性数据。如 “人的年龄”、“公司的注册资本”等;
· 关系属性数据。
第三层:高维、组合数据(衍生数据)——组合信息——这是用前两层数据“搭出来”的新结构
· 路径:单路径、多路径、环路等。如从 A 到 B 再到 C 的关系链(如“用户 A→转账→用户 B→转账→用户 C”);
· 子图:某类实体组成的小网络(如“某公司的所有关联企业”)
· 环路:A→B→C→A 的闭环(如反欺诈中发现的“共享信息的多个贷款申请”)
很明显,这些数据从上到下,存储复杂度和对计算(穿透或聚合)能力的需求越来越高。也就是说,存储更多关注元数据及离散类型的数据,而高维的组合数据则需要图计算引擎来生成。
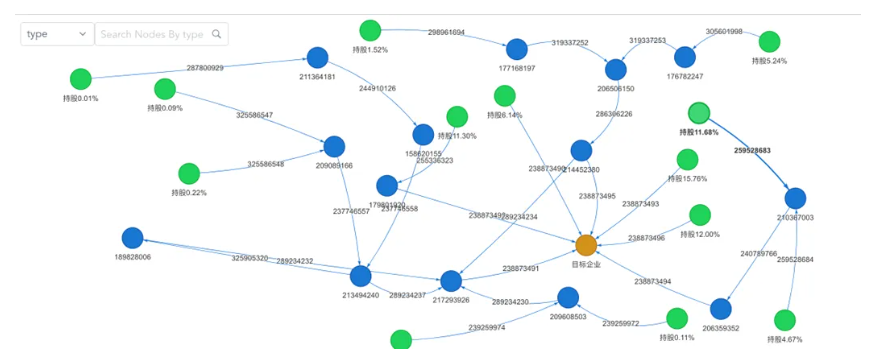
图4:原生图上实现的深度穿透及可视化呈现
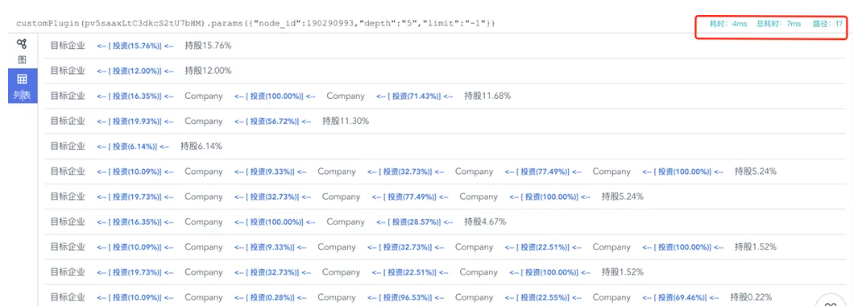
图5:原生图上实现的深度穿透的异构路径列表
传统数据库处理不同类型的实体(比如 “人” 和 “公司”),得建不同的表,查关系时要反复 “跨表关联”,麻烦又低效。而图数据库能把所有异构实体 “揉” 进一个网络里,“一锅烩” 也能井井有条,比如以银行卡交易为例:
-
传统数据库需要 3 张表:账户表(存账号、余额)、卡片表(存卡号、所属账户)、交易表(存交易时间、金额)。 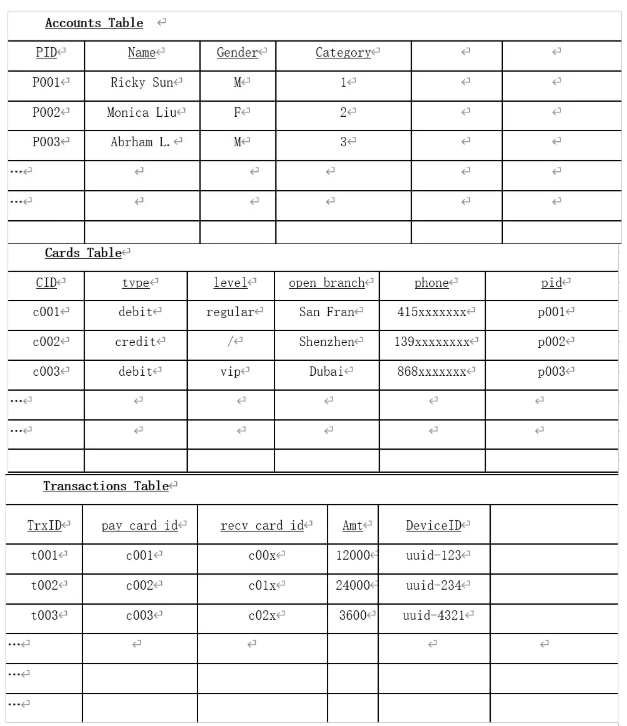
表:银行卡交易场景中的关系型数据表(3张)
-
图数据库里,“账户”、“卡片”、“设备” 都是顶点,“拥有”(账户拥有卡片)、“交易”(卡片通过设备完成交易)是边。想查 “某设备参与的所有交易涉及哪些账户”,只需顺着边 “走一遍”,不用跨表。
如果上面的关系表中的实体与关联关系用图数据库来表达,并可视化的呈现出来后,是这样的效果:
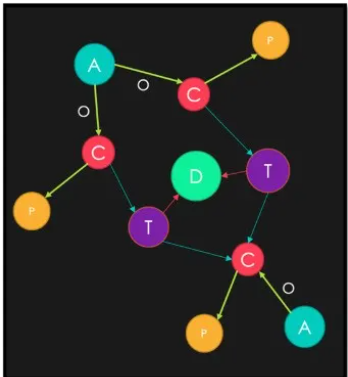
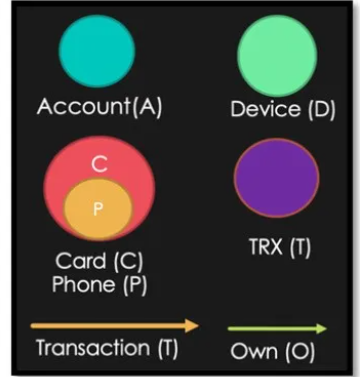
·实体:
o 账户
o 卡:包含一个子类或属性,电话
o 设备
o 交易
·关系
o 交易
o 拥有关系,或账户层级关系
显然,图4中的这种实体分类(建模)方式并不是唯一的一种,我们还可以以更精简的模式来实现建模,例如,只有两类实体和一种关系:
·实体:直接发生交易的卡(卡的属性包含账号、电话)、商户(商户属性信息)
·关系:交易(属性:交易时间、设备、环境信息等)
也就是说,多边图中,任意一对顶点(银行卡)中,可以直接有多条交易关联关系(边)。而单边图中,任意一对顶点间,最多只能表达一条边(一条关系)。另外,在单边图中,边上所承载的属性很少,通常只有一个标签(label),而多边图上,边因为表达的是交易,它可能有很多属性信息。
事实上,在工业界的图数据库实现中,不同的厂家确实采用了不同的实现方式。笔者倾向于认为多边图可以向下兼容单边图,并且多边图的实现显然更贴近真实的场景和人类的思维方式。
另外,虽然多边图的存储设计会更为复杂,但是它可能会节省更多的存储空间。以两个账户之间有1万笔交易为例,如果是单边图,它需要10002个实体,以及20000条边来表达;如果用多边图,只需要2个实体和10000条边,两者的存储有3倍的差异,多边图比单边图存储空间占用节省了2/3(67%)。
不过,在某些场景下,单边图的查询模式有其存在的道理,例如反欺诈场景中常见的要查找是否有两个信用卡申请或贷款申请使用了同样的电话号码与地址。单边图的构图如下:
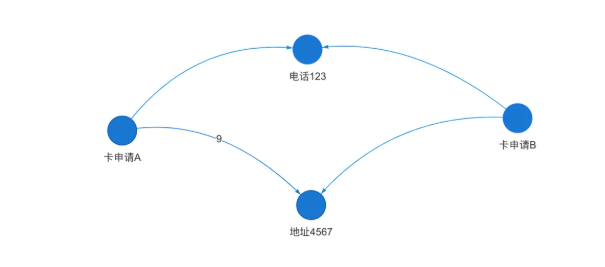
图6:金融反欺诈场景中的单边图构图与查询逻辑
这样构图的优点实际上是在进行“模式”查询的时候才会体现出来,因为我们去判断(任意)一个申请是否存在欺诈的时候,是先在图中查找是否该申请与任意其它可触达的申请之间形成了某种环路的拓扑结构,如图5所示,两个申请间通过电话与地址关联,形成了一个深度为4(4步或4层)的环路,即从申请A出发,沿电话,可达申请B,再通过地址,可返回申请A,进而算作一条环路。如果从该申请出发,可以找到很多类似的环路,通过设定一个阈值,例如>5,那么该申请为欺诈的可能性高,进而可以拒绝该卡(贷款)申请。如果是多边图,电话、地址等信息是附属于卡申请之下的属性,反欺诈的查询逻辑就完全不同于上面的环路查询了。
图数据库之所以能轻松处理异构数据和复杂关系,核心在于存储决定能力,构图反映逻辑,能把现实世界中盘根错节的关联,变成计算机能快速理解和计算的结构。
图存储的核心价值,在于它打破了传统数据存储对 “结构化” 和 “同类型” 的束缚,以 “实体 - 关系” 为骨架的分层设计(元数据、次生数据、衍生数据),让异构数据能在统一框架下高效融合;而顶点与边的灵活存储逻辑(合并 / 分离存储、方向与逆查设计),以及多边图与单边图的场景化构图,更是为复杂关系的查询与计算提供了原生支持。从本质上看,图存储不仅是一种技术方案,更是对现实世界 “关联本质” 的直接映射 —— 它让数据不再是孤立的碎片,而是能相互连接、层层穿透的网络。理解图存储的逻辑,便是理解如何让数据 “活” 起来,在纷繁的关联中挖掘出更深层的价值。

_2.png)

_1.png)