环境需求
- 启动最新版的嬴图v4.3服务器集群,如192.168.1.85:60061,192.168.1.86:60061,192.168.1.87:60061
- 安装最新版嬴图Python SDK v4.3,参考安装
创建连接
连接到嬴图服务器时,使用UltipaConfig实例化服务器的连接信息,并传入Connection.NewConnection()。
当UltipaConfig的配置项defaultGraph没有填写时,将使用默认图集default:
from ultipa import Connection, UltipaConfig
ultipaConfig = UltipaConfig()
ultipaConfig.hosts = ["192.168.1.85:60061", "192.168.1.86:60061", "192.168.1.87:60061"]
ultipaConfig.username = "***"
ultipaConfig.password = "***"
connection = Connection.NewConnection(defaultConfig=ultipaConfig)
如果hosts是URL地址,开头需保留
https://或http://。
参考API文档UltipaConfig,Connection。
一个连接创建后,对其UltipaConfig实例所做的修改将会自动更新该连接。
以下代码将已创建好的连接所使用的图集切换至amz:
ultipaConfig.defaultGraph = "amz"
使用LoggerConfig实例化logger信息,并更新UltipaConfig实例。以下代码通过设置logger将连接的各项活动输出至控制台:
from ultipa.utils.logger import LoggerConfig
loggerConfig = LoggerConfig(name="myLog", isStream=True)
ultipaConfig.uqlLoggerConfig = loggerConfig
connection.test().Print()
对LoggerConfig实例所做的修改同样会自动更新其UltipaConfig实例,进而自动更新其所对应的连接。以下代码通过修改logger将连接的各项活动写入文件:
loggerConfig.filename = "myLogFile"
loggerConfig.isWriteToFile = True
参考API文档LoggerConfig。
创建图集
通过以下方式在已连接的嬴图服务器中创建图集:
- 接口(一个图集):使用
Graph实例化图集的名称和描述,并传入createGraph() - 嬴图GQL(多个图集): 将创建图集的嬴图GQL语句传入
uql()
以下代码通过接口创建图集graph1:
from ultipa import GraphInfo
connection.createGraph(graph=GraphInfo(
name="graph1",
description="graphset created via interface"
))
以下代码通过发送嬴图GQL创建图集graph2、graph3和graph4:
connection.uql("create().graph('graph2','graphset created via uql').graph('graph3','graphset created via uql').graph('graph4','graphset created via uql')")
参考API文档Graph,createGraph(),uql()。
关于图集的查看、修改、删除操作在后面进行介绍。
定义图模型
图模型是指元数据的schema及其属性的定义。
创建Schema
点schema default和边schema default是图集中的默schema。通过以下方式在已连接的嬴图图集中创建schema:
- 接口(一个 schema):使用
Schema实例化schema的名称、DB类型和描述,并传入createSchema() - 嬴图GQL(多个 schema):将创建schema的嬴图GQL语句传入
uql()
以下代码通过接口在当前连接的图集中创建点schema student:
from ultipa import Schema
from ultipa import DBType
connection.createSchema(schema=Schema(
name="student",
dbType=DBType.DBNODE,
description="in the connected graphset"
))
参考API文档Schema,createSchema(),DBType。
如果要在其他图集中创建schema,可以通过UltipaConfig将当前连接切换至目标图集后再创建,或者在调用createSchema()时使用RequestConfig声明目标图集。
以下代码通过接口在图集graph1中创建点schema student:
from ultipa import RequestConfig
connection.createSchema(
schema=Schema(
name="student",
dbType=DBType.DBNODE,
description="in graph1"
),
requestConfig=RequestConfig(graphName="graph1")
)
参考API文档RequestConfig。
RequestConfig只规定某一次非插入操作所针对的图集,并非改变当前连接所使用的图集。
以下代码通过发送嬴图GQL在图集graph1中创建点schema professor、边schema mentor和assist:
connection.uql(
uql="create().node_schema('professor').edge_schema('mentor').edge_schema('assist')",
requestConfig=RequestConfig(graphName="graph1")
)
关于schema的查看、修改、删除操作在后面进行介绍。
创建属性
通过以下方式在已连接的嬴图图集的某schema中创建自定义属性:
- 接口(一个属性):将属性的DB类型、schema名称和属性的具体信息(使用
Property进行实例化)传入createProperty() - 嬴图GQL(多个属性):将创建属性的嬴图GQL语句传入
uql()
以下代码通过接口创建为图集graph1的点schema student创建属性name:
from ultipa import Property
from ultipa import PropertyTypeStr
connection.createProperty(
dbType=DBType.DBNODE,
schema="student",
prop=Property(
name="name",
type=PropertyTypeStr.PROPERTY_STRING,
description="student name"
),
requestConfig=RequestConfig("graph1")
)
参考API文档Property,createProperty(),PropertyTypeStr。
参照以下scheam及属性结构:
| DB Type | Schema | Property | Data Type |
|---|---|---|---|
| node | student | age | int32 |
| node | professor | name | string |
| node | professor | age | int32 |
| edge | mentor | year | int32 |
| edge | assist | year | int32 |
以下代码通过发送嬴图GQL为图集graph1创建以上这些属性:
connection.uql(
uql="create().node_property(@student,'age',int32).node_property(@professor,'name',string).node_property(@professor,'age',int32).edge_property(@mentor,'year',int32).edge_property(@assist,'year',int32)",
requestConfig=RequestConfig("graph1")
)
关于属性的查看、修改、删除操作在后面进行介绍。
插入元数据
元数据是指图集中的点、边。插入前需先构造好以EntityRow为元素的元数据列表。
参考API文档EntityRow。
Auto
以下两个接口可以一次插入不同schema的元数据:
insertNodesBatchAuto()insertEdgesBatchAuto()
使用以上两个接口时,要求所构造的元数据列表中每一个元数据均携带其所属的schema信息。
参考API文档EntityRow。
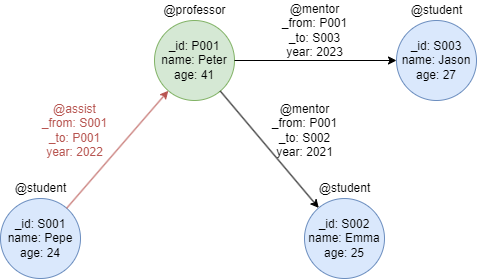
以下代码通过接口向图集graph1中插入学生点S003和教授点P001:
from ultipa import EntityRow
from ultipa import InsertConfig
from ultipa import InsertType
mixedNodeList = [
EntityRow(id="S003", schema="student", values={"name": "Jason", "age": 27}),
EntityRow(id="P001", schema="professor", values={"name": "Peter", "age": 41})
]
auto_insert_node_result = connection.insertNodesBatchAuto(
nodes=mixedNodeList,
config=InsertConfig(
insertType=InsertType.NORMAL,
graphName="graph1"
)
)
auto_insert_node_result.Print()
参考API文档insertNodesBatchAuto(),InsertConfig,InsertType。
InsertConfig规定某一次插入操作的插入类型(insert/upsert/overwrite)和连接信息(如目标图集等)。与RequestConfig类似,它也不改变当前连接的各项配置。
以下代码通过接口创建向图集graph1的schema mentor和assist中插入一列边:
mixedEdgeList = [
EntityRow(schema="assist", from_id="S001", to_id="P001", values={"year": 2022}),
EntityRow(schema="mentor", from_id="P001", to_id="S002", values={"year": 2021}),
EntityRow(schema="mentor", from_id="P001", to_id="S003", values={"year": 2023})
]
auto_insert_edge_result1 = connection.insertEdgesBatchAuto(
edges=mixedEdgeList,
config=InsertConfig(
insertType=InsertType.NORMAL,
graphName="graph1")
)
auto_insert_edge_result1.Print()
auto_insert_edge_result2 = connection.insertEdgesBatchAuto(
edges=mixedEdgeList,
config=InsertConfig(
insertType=InsertType.NORMAL,
graphName="graph1",
CreateNodeIfNotExist=True
)
)
auto_insert_edge_result2.Print()
参考API文档insertEdgesBatchAuto()。
上面示例中的auto_insert_edge_result1会引发报错,原因是其所尝试插入的边的起点和终点(学生点S001和S002)在图集中不存在。
而auto_insert_edge_result2正常,因为其InsertConfig将CreateNodeIfNotExist设置为True,表示允许不存在的学生点S001和S002被自动插入。
接口
insertNodesBatchAuto()和insertEdgesBatchAuto()均要求待插入的元数据的所有自定义属性被构建于列表中,否则将报错,例如学生点未携带属性name和/或age的情况。
By Schema
以下两个接口允许被插入的元数据仅携带其schema中包含的一部分自定义属性:
insertNodesBatchBySchema()insertEdgesBatchBySchema()
使用以上两个接口时,需要使用Schema实例化元数据所携带的属性信息,并传入接口。显然,此种设计要求被插入的元数据均属于同一个schema,并且所构造的元数据列表必须包含所有被Schema实例声明的属性。
以下代码在插入学生点S002和S003时仅携带了属性name:
schema = Schema(
name="student",
dbType=DBType.DBNODE,
properties=[Property("name", ULTIPA.PropertyType.PROPERTY_STRING)]
)
studentList = [
EntityRow(id = "S001", values = {"name": "Pepe"}),
EntityRow(id = "S002", values = {"name": "Emma"})
]
by_schema_insert_node_result = connection.insertNodesBatchBySchema(
schema=schema,
rows=studentList,
config=InsertConfig(
insertType=InsertType.UPSERT,
graphName="graph1"
)
)
by_schema_insert_node_result.Print()
参考API文档insertNodesBatchBySchema(),insertEdgesBatchBySchema()。
以上示例中的
InsertConfig和插入类型指定为UPSERT,这是由于学生点S001和S002已经在前一个插入边的示例中被系统自动插入了。
查询
嬴图Python SDK通过将查询的嬴图GQL语句传入uql()进行查询。uql()的返回值为UltipaResponse类,该类提供方法get()和alias()来获取查询结果。
参考API文档UltipaResponse。
从返回的UltipaResponse类中获取某个数据项时,可以将该数据项的下标传入get(),或将该数据项的别名传入alias():
ultipaResponse = connection.uql("with 2023 as number with 'abc' as string with [1,2,3] as list return number, string, list")
print("The first data item is: ", ultipaResponse.get(0).toJSON())
print("Data item 'list' is: ", ultipaResponse.alias("list").toJSON())
The first data item is: {"alias": "number", "data": {"name": "number", "type": 4, "type_desc": "ATTR", "values": [2023]}, "type": "ATTR"}
Data item 'list' is: {"alias": "list", "data": {"name": "list", "type": 4, "type_desc": "ATTR", "values": [[1, 2, 3]]}, "type": "ATTR"}
方法get()和alias()的返回值为DataItem类,该类提供的不同方法将获得的数据项转为各种不同的数据结构。
参考API文档DataItem。
这些数据结构对应为嬴图系统所定义的5种数据类型:NODE,EDGE,PATH,TABLE和ATTR。
Node
asNodes()将一个数据项转为List[Node]。
以下代码查询了图集graph1中的所有点,并输出这些点:
nodeResponse = connection.uql(
uql="find().nodes() as nodes return nodes{*}",
requestConfig=RequestConfig("graph1")
)
allNodes = nodeResponse.alias("nodes").asNodes()
firstNode = nodeResponse.alias("nodes").asFirstNodes()
for node in allNodes:
print(node.toDict())
print(firstNode.get("name"))
{'id':'S003', 'schema':'student', 'values':{'name': 'Jason', 'age': 27}, 'uuid': 1}
{'id':'P001', 'schema':'professor', 'values':{'name': 'Peter', 'age': 41}, 'uuid': 2}
{'id':'S001', 'schema':'student', 'values':{'name': 'Pepe'}, 'uuid': 3}
{'id':'S002', 'schema':'student', 'values':{'name': 'Emma'}, 'uuid': 4}
Jason
Edge
asEdges()将一个数据项转为List[Edge]。
以下代码查询了图集graph1中的所有边,并输出这些边:
edgeResponse = connection.uql(
uql="find().edges() as edges return edges{*}",
requestConfig=RequestConfig("graph1")
)
allEdges = edgeResponse.alias("edges").asEdges()
firstEdge = edgeResponse.alias("edges").asFirstEdges()
for edge in allEdges:
print(edge.toDict())
print(firstEdge.get("year"))
{'from_id':'S001', 'from_uuid':3, 'to_id':'P001', 'to_uuid':2, 'schema':'assist', 'values':{'year': 2022}, 'uuid': 1}
{'from_id':'P001', 'from_uuid':2, 'to_id':'S002', 'to_uuid':4, 'schema':'mentor', 'values':{'year': 2021}, 'uuid': 2}
{'from_id':'P001', 'from_uuid':2, 'to_id':'S003', 'to_uuid':1, 'schema':'mentor', 'values':{'year': 2023}, 'uuid': 3}
2022
Path
asPaths()将一个数据项转为List[Path]。
以下代码查询了图集graph1中的所有含右向边的一步路径,并输出这些路径:
pathResponse = connection.uql(
uql="n().re().n() as paths return paths{*}",
requestConfig=RequestConfig("graph1")
)
allPaths = pathResponse.alias("paths").asPaths()
for path in allPaths:
print(path.getNodes()[0].toDict())
{'id':'P001', 'schema':'professor', 'values':{'name': 'Peter', 'age': 41}, 'uuid': 2}
{'id':'P001', 'schema':'professor', 'values':{'name': 'Peter', 'age': 41}, 'uuid': 2}
{'id':'S003', 'schema':'student', 'values':{'name': 'Jason', 'age': 27}, 'uuid': 1}
Table
asTable()将一个数据项转为Table类型。
以下代码查询了图集graph1中的所有含右向@mentor边的一步路径,将路径的起点、终点等信息组织为表格,并输出该表格中的每一行:
tableResponse = connection.uql(
uql="n(as n1).re({@mentor}).n(as n2) return table(n1.name, 'mentor', n2.name) as table",
requestConfig=RequestConfig("graph1")
)
allRows = tableResponse.alias("table").asTable().getRows()
for row in allRows:
print(row)
['Peter', 'mentor', 'Emma']
['Peter', 'mentor', 'Jason']
Attr
嬴图的数据类型ATTR包括嬴图所定义的string、number、list和 point等类型的值。
asAttr()将一个数据项转为Attr类型。
以下代码查询了图集graph1中的所有点,将这些点按schema分组后收集组内各点的nam为数组,并输出这些数组:
attrResponse = connection.uql(
uql="find().nodes() as nodes group by nodes.@ return collect(nodes.name) as collection",
requestConfig=RequestConfig("graph1")
)
wholeAttr = attrResponse.alias("collection").asAttr().values
for attr in wholeAttr:
print(attr)
['Json', 'Pepe', 'Emma']
['Peter']
更新元数据
嬴图Python SDK当前不提供更新元数据的接口。此功能可通过向uql()中传入相关嬴图GQL语句来实现。
删除元数据
嬴图Python SDK 前不提供删除元数据的接口。此功能可通过向uql()中传入相关嬴图GQL语句来实现。
导出元数据
导出元数据时,使用Export实例化元数据的DB类型,数量,schema以及带导出的属性列表,并传入export()。
以下代码从graph1图集中导出了100个学生点的属性name:
exportResponse = connection.export(
ULTIPA_REQUEST.Export(
type=DBType.DBNODE,
limit=100,
schema="student",
properties=["name"]
),
RequestConfig("graph1")
)
for student in exportResponse.data:
print(student.toDict())
{'id':'S003', 'schema':'student', 'values':{'name':'Jason'}, 'uuid':1}
{'id':'S001', 'schema':'student', 'values':{'name':'Pepe'}, 'uuid':3}
{'id':'S002', 'schema':'student', 'values':{'name':'Emma'}, 'uuid':4}
图集的其他操作
显示图集
通过以下方式显示图集信息:
- 接口(一个图集):将图集名传入
getGraph() - 接口(所有图集):调用
showGraph() - 嬴图GQL(一个或所有图集):将显示图集的嬴图GQL语句传入
uql()
以下代码通过接口显示图集graph1的信息:
graph = connection.getGraph(graphName="graph1").data
print(graph)
以下代码通过接口显示所有图集的信息:
graphs = connection.showGraph().data
for graph in graphs:
print(graph)
参考API文档getGraph(),showGraph()。
修改图集
通过以下方式修改图集的名称、描述:
- 接口:将图集名、新名称、新描述传入
alterGraph() - 嬴图GQL:将修改图集的嬴图GQL语句传入
uql()
以下代码通过接口修改图集graph2的名称:
connection.alterGraph(
oldGraphName="graph2",
newGraphName="new_graph",
newDescription="graphset altered via interface"
)
参考API文档alterGraph()。
删除图集
通过以下方式删除图集:
- 接口(一个图集):将图集名传入
dropGraph() - 嬴图GQL(多个图集):将删除图集的嬴图GQL语句传入
uql()
以下代码通过接口删除了图集graph4:
connection.dropGraph(graphName="graph4")
参考API文档dropGraph()。
图模型的更多操作
显示Schema
通过以下方式显示schema信息:
- 接口(一个schema):将schema的DB类型和名称传入
showSchema() - 接口(所有点schema、所有边schema):将schema的DB类型传入
showSchema() - 接口(所有schema):调用
showSchema() - 嬴图GQL(一个或所有点schema、一个或所有边schema):将显示schema的嬴图GQL语句传入
uql()
以下代码通过接口显示了图集graph1中的点schema student:
nodeSchema = connection.showSchema(
dbType=DBType.DBNODE,
schemaName="student",
requestConfig=RequestConfig("graph1")
).get(0).asSchemas()[0]
print(nodeSchema)
以下代码通过接口显示了图集graph1中的所有点schema:
nodeSchemas = connection.showSchema(
dbType=DBType.DBNODE,
requestConfig=RequestConfig("graph1")
).get(0).asSchemas()
for schema in nodeSchemas:
print(schema)
以下代码通过接口显示了图集graph1中的所有schema:
allSchemas = connection.showSchema(requestConfig=RequestConfig("graph1"))
nodeSchemas = allSchemas.alias("_nodeSchema").asSchemas()
edgeSchemas = allSchemas.alias("_edgeSchema").asSchemas()
for schema in nodeSchemas:
print(schema)
for schema in edgeSchemas:
print(schema)
参考API文档showSchema()。
修改Schema
通过以下方式修改schema的名称、描述:
- 接口:将schema的DB类型,名称,新名称,新描述传入
alterSchema() - 嬴图GQL: 将修改schema的嬴图GQL语句传入
uql()
以下代码通过接口修改了图集graph1中的边schema mentor:
connection.alterSchema(
dbType=DBType.DBEDGE,
schemaName="mentor",
newSchemaName="instruct",
description="schema altered via interface",
requestConfig=RequestConfig("graph1")
)
参考API文档alterSchema()。
删除Schema
通过以下方式删除schema:
- 接口(一个schema ):将schema的DB类型,名称传入
dropSchema() - UQL(多个schema ):将删除schema的嬴图GQL语句传入
uql()
以下代码通过接口删除了图集graph1中的边schema assist:
connection.dropSchema(
dbType=DBType.DBEDGE,
schemaName="assist",
requestConfig=RequestConfig("graph1")
)
参考API文档dropSchema()。
显示属性
通过以下方式显示属性信息:
- 接口(一个schema的属性):将schema的DB类型,名称传入
getProperty() - 接口(所有点schema或所有边schema的属性):将schema的DB类型传入
getProperty() - 接口(所有schema的属性):调用
showProperty() - 嬴图GQL(一个或所有点schema、一个或所有边schema的属性):将显示属性的嬴图GQL语句传入
uql()
以下代码通过接口显示了图集graph1中的点schema student的属性:
propsOfANodeSchema = connection.getProperty(
dbType=DBType.DBNODE,
schema="student",
requestConfig=RequestConfig("graph1")
).data[0].data
for property in propsOfANodeSchema:
print(property)
以下代码通过接口显示了图集graph1中所有点schema的属性:
propsOfAllNodeSchemas = connection.getProperty(
dbType=DBType.DBNODE,
requestConfig=RequestConfig("graph1")
).data[0].data
for property in propsOfAllNodeSchemas:
print(property)
以下代码通过接口显示了图集graph1中的所有属性:
propsOfAllSchemas = connection.showProperty(requestConfig = RequestConfig("graph1")).data[0].data
for property in propsOfAllSchemas:
print(property)
参考API文档getProperty(),showProperty()。
修改属性
通过以下方式修改属性的名称、描述:
- 接口:将属性的DB类型,schema名称,属性名,新名称,新描述传入
alterProperty() - 嬴图GQL:将修改属性的嬴图GQL语句传入
uql()
以下代码通过接口修改了图集graph1中点schema professor的属性name:
connection.alterProperty(
dbType=DBType.DBNODE,
schema="professor",
property="name",
newProperty="firstname",
description="property altered via interface",
requestConfig=RequestConfig("graph1")
)
参考API文档alterProperty()。
删除属性
通过以下方式删除属性:
- 接口(一个属性):将属性的DB类型,schema名称,属性名传入
dropProperty() - 嬴图GQL(多个属性):将删除属性的嬴图GQL语句传入
uql()
以下代码通过接口删除了图集graph1中点schema professor的属性age:
connection.dropProperty(
dbType=DBType.DBNODE,
schema="student",
property="age",
requestConfig=RequestConfig("graph1")
)
参考API文档dropProperty()。
算法的相关操作
显示算法
调用showAlgo()显示当前嬴图服务器中已安装的所有算法:
for algo in connection.showAlgo().data:
print(algo)
参考API文档showAlgo()。
安装算法
安装算法时,将算法的.so文件和.yml文件的路径传入installAlgo()。
以下代码安装了LPA算法,相关文件位于当前Python项目路径下:
connection.installAlgo(
algoFilePath="./libplugin_lpa.so",
algoInfoFilePath="./lpa.yml"
)
参考API文档installAlgo()。
卸载算法
安装算法时,将算法名传入uninstallAlgo()。
以下代码从当前嬴图服务器中卸载了LPA算法:
connection.uninstallAlgo(algoName="lpa")
参考API文档uninstallAlgo()。
下载算法任务文件
当一个算法在某图集中以writeback to file的方式执行后,算法的执行结果可以从对应的算法任务中下载。此时使用Download实例化算法任务中的文件名、任务ID以及下载路径,并传入download()。
以下代码从图集graph1的任务134中下载文件degree_test至本地路径./test.csv:
form ultipa.types.types_request import Download
connection.download(
request=Download(
fileName="degree_test",
taskId="134",
savePath="./test.csv"
),
requestConfig=RequestConfig("graph1")
)
从任务中下载文件时,如果该任务不是针对当前所连图集执行的,则需使用
RequestConfig指明该图集。
参考API文档Download,download()。
属性对照表
| 嬴图 | Python |
|---|---|
| string | string |
| text | string |
| float | float |
| double | float |
| int32 | int |
| uint32 | int |
| int64 | int |
| uint64 | int |
| datetime | string |
| timestamp | string或int |