概述
CALL子句对别名代表的数据行的每行数据进行独立的操作和运算。
语法
...
CALL {
WITH <expression_in> as <alias_in>, <expression_in> as <alias_in>, ...
...
RETURN <expression_out> as <alias_out>, <expression_out> as <alias_out>, ...
}
...
CALL子句的具体内容都包裹在花括号{}中:
- 首先,通过WITH子句传入要使用的数据
<expression_in>是别名或使用别名的表达式(别名是在CALL子句前的语句中定义过的)<alias_in>是为传入值定义的别名- 如果
<expression_in>是别名或别名的直接调用形式,<alias_in>可省略
- 接着,使用传入的别名进行查询或运算
- 最后,通过RETURN子句将结果传出
<expression_out>是返回值表达式<alias_out>是为返回值定义的别名- 如果
<expression_out>是别名或别名的直接调用形式,<alias_out>可省略
- 从CALL子句传出的数据可在后续语句中继续使用
例如,以下语句查询两个点后,使用CALL子句对它们分别进行操作,即单独使用每个点作为路径查询的起点,然后将查询结果paths的第一行舍弃,最后将paths传出:

find().nodes([1, 5]) as nodes
call {
with nodes
n(nodes).e()[:2].n() as paths
skip 1
return paths
}
return paths
示例
示例图集
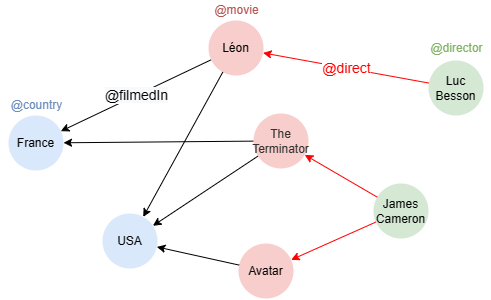
在一个空图集中,依次运行以下各行语句创建示例图集:
create().node_schema("country").node_schema("movie").node_schema("director").edge_schema("filmedIn").edge_schema("direct")
create().node_property(@*, "name")
insert().into(@country).nodes([{_id:"C001", _uuid:1, name:"France"}, {_id:"C002", _uuid:2, name:"USA"}])
insert().into(@movie).nodes([{_id:"M001", _uuid:3, name:"Léon"}, {_id:"M002", _uuid:4, name:"The Terminator"}, {_id:"M003", _uuid:5, name:"Avatar"}])
insert().into(@director).nodes([{_id:"D001", _uuid:6, name:"Luc Besson"}, {_id:"D002", _uuid:7, name:"James Cameron"}])
insert().into(@filmedIn).edges([{_uuid:1, _from_uuid:3, _to_uuid:1}, {_uuid:2, _from_uuid:4, _to_uuid:1}, {_uuid:3, _from_uuid:3, _to_uuid:2}, {_uuid:4, _from_uuid:4, _to_uuid:2}, {_uuid:5, _from_uuid:5, _to_uuid:2}])
insert().into(@direct).edges([{_uuid:6, _from_uuid:6, _to_uuid:3}, {_uuid:7, _from_uuid:7, _to_uuid:4}, {_uuid:8, _from_uuid:7, _to_uuid:5}])
一般用法
本例不使用GROUP BY子句,查询在每个国家分别拍摄了几部电影:
find().nodes({@country}) as nodes
call {
with nodes
n(nodes).e().n({@movie} as n)
return count(n) as number
}
return table(nodes.name, number)
| nodes.name | number |
|------------|--------|
| France | 2 |
| USA | 3 |