- 表达式:
<value>IN<list> - 左操作数:数字、时间、字符串、列表、坐标点、NODE、EDGE
- 右操作数:列表
判断常量
示例:判断 2 是否属于 [1,2,3]
return 2 in [1,2,3]
1
判断函数值
示例:判断 2 是否属于 [1,2,3] 和 [3,2,5] 的交集
return 2 in intersection([1,2,3], [3,2,5])
1
判断别名
示例:判断一个别名中的每一行是否属于 [0,1,3]
uncollect [1,2,3,2,2] as a
return a in [0,1,3]
1
0
1
0
0
示例图集:(以下示例将在本图基础上运行)
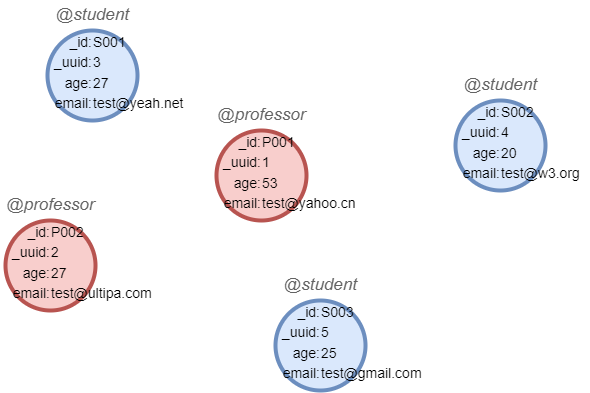
create().node_schema("professor").node_schema("student")
create().node_property(@*, "age", int32).node_property(@*, "email", string)
insert().into(@professor).nodes([{_id:"P001",_uuid:1,age:53,email:"test@yahoo.cn"},{_id:"P002",_uuid:2,age:27,email:"test@ultipa.com"}])
insert().into(@student).nodes([{_id:"S001",_uuid:3,age:27,email:"test@yeah.net"},{_id:"S002",_uuid:4,age:20,email:"test@w3.org"},{_id:"S003",_uuid:5,age:25,email:"test@gmail.com"}])
过滤属性值
示例:获取 age 属于 [20,25,30,35] 的节点
find().nodes({age in [20,25,30,35]}) as n
return n{*}
|---------------- @student ---------------|
| _id | _uuid | age | email |
|-------|-------|-------|-----------------|
| S002 | 4 | 20 | test@w3.org |
| S003 | 5 | 25 | test@gmail.com |
示例:获取 age 属于 [20,25,30,35] 的 @professor 点
find().nodes({@professor.age in [20,25,30,35]}) as n
return n{*}
No return data
过滤 _uuid (简写)
当过滤器只判断点/边的 _uuid 是否属于一个整数列表时,该过滤器可简写为:
| 标准形式 | 简写形式 |
说明 |
|---|---|---|
| ({ _uuid in [1,2,3]}) | ([1,2,3]) | |
({ _uuid in intList}) |
(intList) |
intList为整数列表的别名 |
({ _uuid in [node1._uuid, node2._uuid, ...]}) |
(nodeList) |
nodeList为列表 [node1, node2, ...] 的别名 |
({ _uuid in [edge1._uuid, edge2._uuid, ...]}) |
(edgeList) |
edgeList为列表 [edge1, edge2, ...] 的别名 |
示例:找出 _uuid 属于 [2,3,5] 的节点
find().nodes([2,3,5]) as n
return n{*}
|---------------- @student ---------------|
| _id | _uuid | age | email |
|-------|-------|-------|-----------------|
| S001 | 3 | 27 | test@yeah.net |
| S002 | 4 | 20 | test@w3.org |
| S003 | 5 | 25 | test@gmail.com |