概述
RETURN语句指定查询结果包括的项目。每项由一个表达式定义,包含变量、属性、函数、常量等。
<return statement> ::=
"RETURN" [ "DISTINCT" | "ALL" ] { <"*"> | <return items> } [ <group by clause> ]
<return items> ::=
<return item> [ { "," <return item> }... ]
<return item> ::=
<value expression> [ "AS" <identifier> ]
<group by clause> ::=
"GROUP BY" <grouping key> [ { "," <grouping key> }... ]
详情
- 星号
*返回中间结果表的所有列。详见返回全部。 - 使用关键词
AS可重命名一个返回项。详见返回项别名。 RETURN语句支持使用GROUP BY从句。详见返回分组数据。- 运算符
DISTINCT能够对记录进行去重。如果未指定DISTINCT或ALL,隐式使用ALL。详见返回去重记录。
示例图
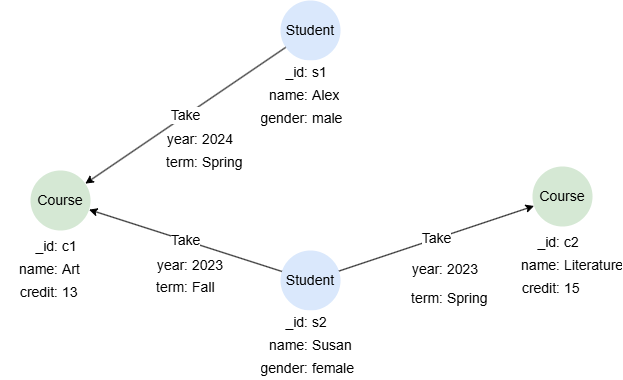
CREATE GRAPH myGraph {
NODE Student ({name string, gender string}),
NODE Course ({name string, credit uint32}),
EDGE Take ()-[{year uint32, term string}]->()
} PARTITION BY HASH(Crc32) SHARDS [1]
INSERT (alex:Student {_id: 's1', name: 'Alex', gender: 'male'}),
(susan:Student {_id: 's2', name: 'Susan', gender: 'female'}),
(art:Course {_id: 'c1', name: 'Art', credit: 13}),
(literature:Course {_id: 'c2', name: 'Literature', credit: 15}),
(alex)-[:Take {year: 2024, term: 'Spring'}]->(art),
(susan)-[:Take {year: 2023, term: 'Fall'}]->(art),
(susan)-[:Take {year: 2023, term: 'Spring'}]->(literature)
返回点
与点绑定的变量返回每个点的全部信息。
MATCH (n:Course)
RETURN n
结果: n
| _id | _uuid | schema | values |
|---|---|---|---|
| c1 | Sys-gen | Course | {name: "Art", credit: 13} |
| c2 | Sys-gen | Course | {name: "Literature", credit: 15} |
返回边
与边绑定的变量返回每条边的全部信息。
MATCH ()-[e]->()
RETURN e
结果: e
_uuid |
_from |
_to |
_from_uuid |
_to_uuid |
schema |
values |
|---|---|---|---|---|---|---|
| Sys-gen | s2 | c1 | UUID of s2 | UUID of c1 | Take | {year: 2023, term: "Fall"} |
| Sys-gen | s2 | c2 | UUID of s2 | UUID of c2 | Take | {year: 2023, term: "Spring"} |
| Sys-gen | s1 | c1 | UUID of s1 | UUID of c1 | Take | {year: 2024, term: "Spring"} |
返回路径
与路径绑定的变量返回每条路径中的点和边的全部信息。
MATCH p = ()-[:Take {term: "Spring"}]->()
RETURN p
结果:p

返回标签
labels()函数返回点或边的标签。
MATCH ({_id: "s2"})-[e]->(n)
RETURN labels(e), labels(n)
结果:
| labels(e) | labels(n) |
|---|---|
| Take | Course |
| Take | Course |
返回属性
英文句号.从绑定点或边的变量中提取指定属性的值。如果找不到指定属性,则返回null值。
MATCH (:Student {name:"Susan"})-[]->(c:Course)
RETURN c.name, c.credit, c.type
结果:
| c.name | c.credit | c.type |
|---|---|---|
| Literature | 15 | null |
| Art | 13 | null |
返回全部
星号*返回中间结果表的所有列。注意,RETURN语句里使用*时,不应该同时使用GROUP BY从句。
MATCH (s:Student {name:"Susan"})-[]->(c:Course)
RETURN *
结果:
s
| _id | _uuid | schema | values |
|---|---|---|---|
| s2 | Sys-gen | Student | {name: "Susan", gender: "female"} |
| s2 | Sys-gen | Student | {name: "Susan", gender: "female"} |
c
| _id | _uuid | schema | values |
|---|---|---|---|
| c1 | Sys-gen | Course | {name: "Art", credit: 13} |
| c2 | Sys-gen | Course | {name: "Literature", credit: 15} |
返回项别名
关键词AS可以用来给返回项指定一个别名。
MATCH (s:Student)-[t:Take]->(c:Course)
RETURN s.name AS Student, c.name AS Course, t.year AS TakenIn
结果:
| Student | Course | TakenIn |
|---|---|---|
| Alex | Art | 2024 |
| Susan | Art | 2023 |
| Susan | Literature | 2023 |
返回聚合数据
聚合函数,如sum()和max(),可在RETURN语句中直接使用。
MATCH (:Student {name:"Susan"})-[]->(c:Course)
RETURN sum(c.credit)
结果:
| sum(c.credit) |
|---|
| 28 |
由于使用了聚合函数,本查询返回的c只包含一个记录是符合预期的:
MATCH (:Student {name:"Susan"})-[]->(c:Course)
RETURN c, sum(c.credit)
结果:
c
| _id | _uuid | schema | values |
|---|---|---|---|
| c1 | Sys-gen | Course | {name: "Art", credit: 13} |
sum(c.credit)
| sum(c.credit) |
|---|
| 28 |
使用CASE
MATCH (n:Course)
RETURN n.name, CASE WHEN n.credit > 14 THEN "Y" ELSE "N" END AS Recommended
结果:
| n.name | Recommended |
|---|---|
| Art | N |
| Literature | Y |
返回限制数量的记录
LIMIT语句可限制每个返回项返回的记录数。
MATCH (n:Course)
RETURN n.name LIMIT 1
结果:
| n.name |
|---|
| Art |
返回排序后的记录
ORDER BY语句可对记录进行排序。
MATCH (n:Course)
RETURN n ORDER BY n.credit DESC
结果: n
| _id | _uuid | schema | values |
|---|---|---|---|
| c2 | Sys-gen | Course | {name: "Literature", credit: 15} |
| c1 | Sys-gen | Course | {name: "Art", credit: 13} |
返回分组数据
GROUP BY从句根据指定的键对查询结果进行分组。分组后,每组只保留一个记录。
单个分组依据
MATCH ()-[e:Take]->()
RETURN e.term GROUP BY e.term
结果:
| e.term |
|---|
| Spring |
| Fall |
在GQL标准中,分组键必须是直接的变量引用,上述查询必须写为
RETURN e.term AS <varName> GROUP BY <varName>。嬴图对这一规则进行简化,允许表达式作为分组键,无需引入中间变量。
多个分组依据
MATCH ()<-[e:Take]-()
RETURN e.year, e.term GROUP BY e.year, e.term
结果:
| e.year | e.term |
|---|---|
| 2023 | Spring |
| 2024 | Spring |
| 2023 | Fall |
分组和聚合
如果有分组,RETURN语句里包含的任何聚合操作都是针对每个组进行的。
本查询计算每个Term组中Take边的数量:
MATCH ()-[e:Take]->()
RETURN e.term, count(e) GROUP BY e.term
结果
| e.term | count(e) |
|---|---|
| Spring | 2 |
| Fall | 1 |
返回去重记录
运算符DISTINCT对所有返回项的记录进行去重。当指定DISTINCT时,每个返回项隐式地成为一个分组依据。
MATCH ()-[e]->()
RETURN DISTINCT e.year
本查询相当于:
MATCH ()-[e]->()
RETURN e.year GROUP BY e.year
结果:
| e.year |
|---|
| 2023 |
| 2024 |
MATCH ()-[e]->()
RETURN DISTINCT e.year, e.term
本查询相当于:
MATCH ()-[e]->()
RETURN e.year, e.term GROUP BY e.year, e.term
结果:
| e.year | e.term |
|---|---|
| 2023 | Fall |
| 2023 | Spring |
| 2024 | Spring |