HDC 分布式
概述
中介中心性(Betweenness Centrality)测算一个点位于图中其它两点间最短路径上的概率。这个指标能有效地找到在图的各部分间起桥梁作用的点。
中介中心性的取值范围是0到1,值越大,点对于网络流通性或连通性的影响力越大。
参考资料:
- L.C. Freeman, A Set of Measures of Centrality Based on Betweenness (1977)
- L.C. Freeman, Centrality in Social Networks Conceptual Clarification (1978)
基本概念
最短路径
两点间的最短路径是指它们之间边数最少的路径。当考虑边权重时,(加权)最短路径是那些权重和最少的路径。
中介中心性
点x的中介中心性计算公式为:
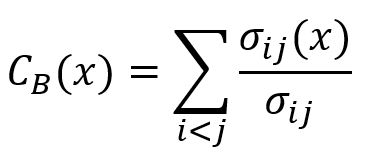
其中,
i和j是图中互异的两个点,不包括x。σij为i、j间最短路径的数量。σij(x)为i、j间经过x的最短路径的数量。σij(x)/σij就是x位于i、j间最短路径的概率。注意,i、j不连通时,σij(x)/σij为0。
最终值由因子(k – 1)(k – 2)/2进行归一化,其中k是图中的点总数。这种归一化可确保结果位于固定范围内,使其在不同大小的图之间具有可比性。
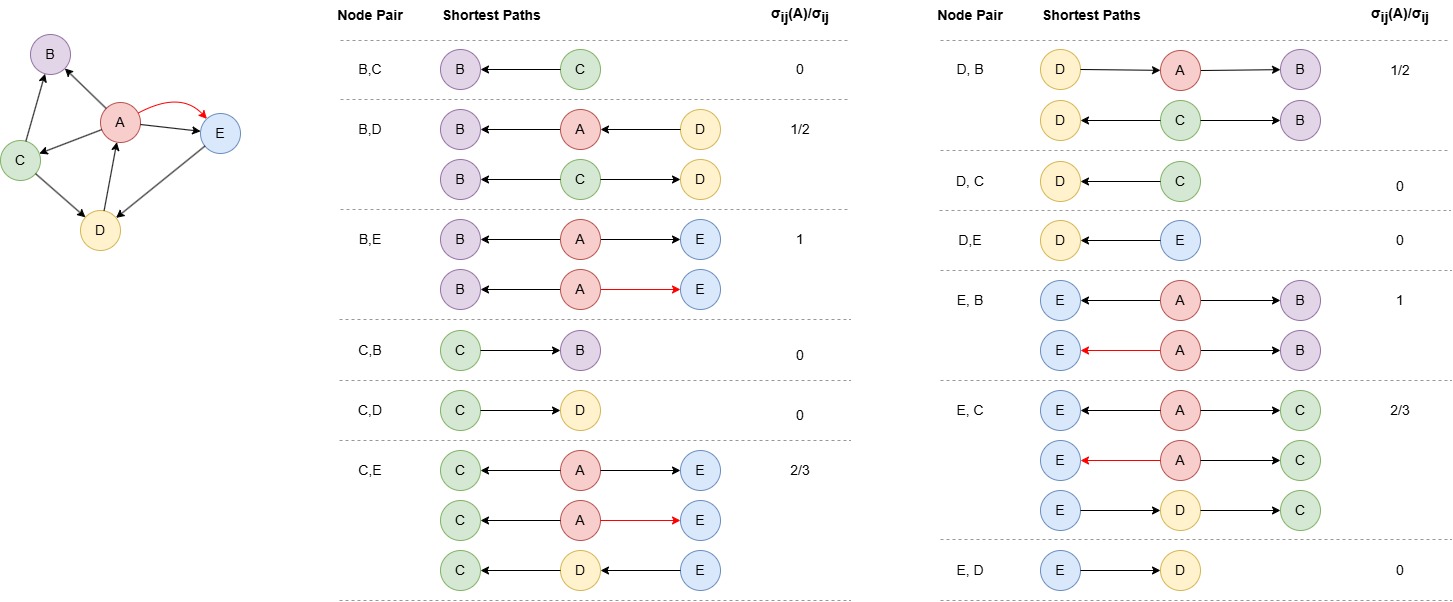
点A的中介中心性为(1/2 + 1 + 2/3 + 1/2 + 1 + 2/3) / (4 * 3 / 2) = 0.722222。
采样计算
在规模较大的图上运行本算法会消耗很多计算资源。当图中点数量超过一万时,建议按点或边采样后进行近似计算。算法只进行一次均匀采样。
示例图
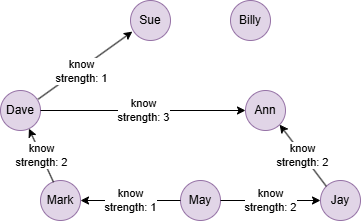
在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
user ()
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
know ()-[{strength int32}]->()
};
INSERT (Sue:user {_id: "Sue"}),
(Dave:user {_id: "Dave"}),
(Ann:user {_id: "Ann"}),
(Mark:user {_id: "Mark"}),
(May:user {_id: "May"}),
(Jay:user {_id: "Jay"}),
(Billy:user {_id: "Billy"}),
(Dave)-[:know {strength: 1}]->(Sue),
(Dave)-[:know {strength: 3}]->(Ann),
(Mark)-[:know {strength: 2}]->(Dave),
(May)-[:know {strength: 1}]->(Mark),
(May)-[:know {strength: 2}]->(Jay),
(Jay)-[:know {strength: 2}]->(Ann);
create().node_schema("user").edge_schema("know");
create().edge_property(@know, "strength", int32);
insert().into(@user).nodes([{_id:"Sue"}, {_id:"Dave"}, {_id:"Ann"}, {_id:"Mark"}, {_id:"May"}, {_id:"Jay"}, {_id:"Billy"}]);
insert().into(@know).edges([{_from:"Dave", _to:"Sue", strength:1}, {_from:"Dave", _to:"Ann", strength:3}, {_from:"Mark", _to:"Dave", strength:2}, {_from:"May", _to:"Mark", strength:1}, {_from:"May", _to:"Jay", strength:2}, {_from:"Jay", _to:"Ann", strength:2}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:betweenness_centrality
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
edge_schema_property |
[]"<@schema.?><property>" |
/ | / | 是 | 作为权重的数值类型边属性,权重值为所有指定属性值的总和;不包含指定属性的边将被忽略 |
impl_type |
String | dijkstra, spfa |
dijkstra |
是 | 指定由算法Dijkstra或SPFA计算加权最短路径。仅当使用edge_schema_property时生效 |
sample_size |
Integer | -1, -2, [1, |V|] |
-2 |
是 | 设为-1时,采样log10(|V|)个点(|V|为图中点数量),或自定义一个在[1, |V|]区间内的采样数;设为-2时,不进行采样 |
max_path_length |
Integer | >0 | / | 是 | 只考虑长度小于或等于该值的最短路径;注意此参数不影响考虑的点对总数 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
order |
String | asc, desc |
/ | 是 | 根据betweenness_centrality对结果排序 |
文件回写
CALL algo.betweenness_centrality.write("my_hdc_graph", {
return_id_uuid: "id"
}, {
file: {
filename: "betweenness_centrality"
}
})
algo(betweenness_centrality).params({
projection: "my_hdc_graph",
return_id_uuid: "id"
}).write({
file: {
filename: "betweenness_centrality"
}
})
结果:
_id,betweenness_centrality
Dave,0.666667
Billy,0
May,0.133333
Mark,0.266667
Jay,0.133333
Ann,0.266667
Sue,0
数据库回写
将结果中的betweenness_centrality值写入指定点属性。该属性类型为float。
CALL algo.betweenness_centrality.write("my_hdc_graph", {},
{
db: {
property: "bc"
}
})
algo(betweenness_centrality).params({
projection: "my_hdc_graph"
}).write({
db:{
property: 'bc'
}
})
完整返回
CALL algo.betweenness_centrality.run("my_hdc_graph", {
max_path_length: 2,
return_id_uuid: "id",
order: "desc",
limit: 3
}) YIELD bc
RETURN bc
exec{
algo(betweenness_centrality).params({
max_path_length: 2,
return_id_uuid: "id",
order: "desc",
limit: 3
}) as bc
return bc
} on my_hdc_graph
结果:
| _id | betweenness_centrality |
|---|---|
| Dave | 0.4 |
| May | 0.133333 |
| Mark | 0.133333 |
流式返回
CALL algo.betweenness_centrality.stream("my_hdc_graph", {
return_id_uuid: "id",
edge_schema_property: "strength"
}) YIELD r
FILTER r.betweenness_centrality > 0.6
RETURN r
exec{
algo(betweenness_centrality).params({
return_id_uuid: "id",
edge_schema_property: "strength"
}).stream() as r
where r.betweenness_centrality > 0.6
return r
} on my_hdc_graph
结果:
| _id | betweenness_centrality |
|---|---|
| Dave | 0.6 |