概述
连通分量(Connected Component)算法能识别图中的连通分量,这是考察图的连通性和拓扑特征的重要指标。
图中连通分量的数量可作为一种粗粒度的计量方式。如果对图进行某些操作或修改后,连通分量的数量保持不变,则表明图的宏观连通性和拓扑特征没有发生显着变化。
连通分量信息在各种图分析情景中都很有价值。例如,在社交网络中,如果连通分量的数量随着时间的推移保持不变,则意味着网络内的整体连接模式和社区结构没有发生实质性变化。
基本概念
连通分量
一个连通分量是图中节点的一个最大子集,该子集中的所有节点都可以通过路径相互连接。最大子集意味着在不破坏连接要求的情况下,无法向子集添加其他节点。
连通分量的数量反映全图的连通性以及存在多少不同的子图。如果一个图只有一个连通分量,该连通分量由全图节点组成,这样的图称为连通图(Connected Graph)。
强连通分量,弱连通分量
与连通分量相关有两个重要概念——弱连通分量(Weakly Connected Component, WCC)和强连通分量(Strongly Connected Component, SCC):
- 弱连通分量是指有向或无向图中节点的子集,其中任何一对节点之间存在路径,而不考虑边的方向如何。
- 强连通分量是有向图中节点的子集,其中每对节点之间都存在一个有向路径。换句话说,对于强连通分量中的任意两个节点u和v,既存在从u到v的有向路径,也存在从v到u的有向路径。在有向路径中,所有边的方向一致。
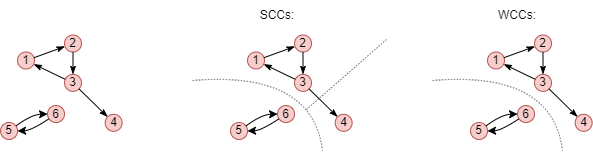
上面的例子对同一张图分别进行了强、弱连通分量的计算,结果可划分为3个强连通分量,或2个弱连通分量。由于强连通分量的判断条件更严格,有向图中的强连通分量的个数总是大于或等于弱连通分量的个数。
特殊说明
- 图中的每个孤点都是一个连通分量,既是强连通分量,也是弱连通分量。
示例图
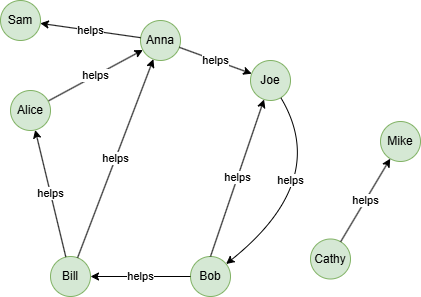
在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
member ()
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
helps ()-[]->()
};
INSERT (Mike:member {_id: "Mike"}),
(Cathy:member {_id: "Cathy"}),
(Anna:member {_id: "Anna"}),
(Joe:member {_id: "Joe"}),
(Sam:member {_id: "Sam"}),
(Bob:member {_id: "Bob"}),
(Bill:member {_id: "Bill"}),
(Alice:member {_id: "Alice"}),
(Cathy)-[:helps]->(Mike),
(Anna)-[:helps]->(Sam),
(Anna)-[:helps]->(Joe),
(Joe)-[:helps]->(Bob),
(Bob)-[:helps]->(Joe),
(Bob)-[:helps]->(Bill),
(Bill)-[:helps]->(Alice),
(Bill)-[:helps]->(Anna),
(Alice)-[:helps]->(Anna);
create().node_schema("member").edge_schema("helps");
insert().into(@member).nodes([{_id:"Mike"}, {_id:"Cathy"}, {_id:"Anna"}, {_id:"Joe"}, {_id:"Sam"}, {_id:"Bob"}, {_id:"Bill"}, {_id:"Alice"}]);
insert().into(@helps).edges([{_from:"Cathy", _to:"Mike"}, {_from:"Anna", _to:"Sam"}, {_from:"Anna", _to:"Joe"}, {_from:"Joe", _to:"Bob"}, {_from:"Bob", _to:"Joe"},{_from:"Bob", _to:"Bill"}, {_from:"Bill", _to:"Alice"}, {_from:"Bill", _to:"Anna"}, {_from:"Alice", _to:"Anna"}]);
在HDC图上运行算法
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:connected_component
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
cc_type |
Integer | 1, 2 |
1 |
是 | 要识别的连通分量类型:1为弱连通分量,2为强连通分量 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
order |
String | asc, desc |
/ | 是 | 根据count值对结果排序;该选项仅在流式返回模式下mode为2时生效 |
算法结果中,每个连通分量由相同的community_id表示,对应其中一个节点的_uuid值。
文件回写
该算法可生成三个文件:
配置项 |
内容 |
|---|---|
filename_community_id |
|
filename_ids |
|
filename_num |
|
CALL algo.connected_component.write("my_hdc_graph", {
return_id_uuid: "id",
cc_type: 1
}, {
file: {
filename_community_id: "f1",
filename_ids: "f2",
filename_num: "f3"
}
})
algo(connected_component).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
cc_type: 1
}).write({
file: {
filename_community_id: "f1",
filename_ids: "f2",
filename_num: "f3"
}
})
结果:
_id,community_id
Alice,0
Cathy,1
Anna,0
Bob,0
Joe,0
Bill,0
Mike,1
Sam,0
community_id,_ids
0,Alice;Anna;Bob;Joe;Bill;Sam;
1,Cathy;Mike;
community_id,count
0,6
1,2
数据库回写
将结果中的community_id值写入指定点属性。该属性类型为uint32。
CALL algo.connected_component.write("my_hdc_graph", {}, {
db: {
property: "wcc_id"
}
})
algo(connected_component).params({
projection: "my_hdc_graph"
}).write({
db: {
property: "wcc_id"
}
})
统计回写
CALL algo.connected_component.write("my_hdc_graph", {}, {
stats: {}
})
algo(connected_component).params({
projection: "my_hdc_graph"
}).write({
stats: {}
})
结果:
| community_count |
|---|
| 2 |
完整返回
CALL algo.connected_component.run("my_hdc_graph", {
return_id_uuid: "id",
cc_type: 2
}) YIELD r
RETURN r
exec{
algo(connected_component).params({
return_id_uuid: "id",
cc_type: 2
}) as r
return r
} on my_hdc_graph
结果:
| _id | community_id |
|---|---|
| Alice | 0 |
| Cathy | 1 |
| Anna | 0 |
| Bob | 0 |
| Joe | 0 |
| Bill | 0 |
| Mike | 6 |
| Sam | 7 |
流式返回
流式返回支持两种模式:
| 项目 | 配置项 | 列名 |
|---|---|---|
mode |
1(默认) |
|
2 |
|
CALL algo.connected_component.stream("my_hdc_graph", {
return_id_uuid: "id",
cc_type: 2
}) YIELD r
RETURN r
exec{
algo(connected_component).params({
return_id_uuid: "id",
cc_type: 2
}).stream() as r
return r
} on my_hdc_graph
结果:
| _id | community_id |
|---|---|
| Alice | 0 |
| Cathy | 1 |
| Anna | 0 |
| Bob | 0 |
| Joe | 0 |
| Bill | 0 |
| Mike | 6 |
| Sam | 7 |
CALL algo.connected_component.stream("my_hdc_graph", {
return_id_uuid: "id",
cc_type: 2,
order: "asc"
}, {
mode: 2
}) YIELD r
RETURN r
exec{
algo(connected_component).params({
return_id_uuid: "id",
cc_type: 2,
order: "asc"
}).stream({
mode: 2
}) as r
return r
} on my_hdc_graph
结果:
| community_id | count |
|---|---|
| 6 | 1 |
| 1 | 1 |
| 7 | 1 |
| 0 | 5 |
统计返回
CALL algo.connected_component.stats("my_hdc_graph", {}) YIELD wcc_count
RETURN wcc_count
exec{
algo(connected_component).params().stats() as wcc_count
return wcc_count
} on my_hdc_graph
结果:
| community_count |
|---|
| 2 |
在分布式投影上运行算法
创建分布式投影
将图集全部投影到shard服务器上并命名为myProj:
CREATE PROJECTION myProj OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true
}
create().projection("myProj", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true
})
参数
算法名:wcc
该算法不需要任何参数。
该算法的分布式版本仅支持识别图集中的弱连通分量。算法结果中,每个连通分量由相同的community_id表示。
文件回写
CALL algo.wcc.write("myProj", {}, {
file: {
filename: "wcc"
}
})
algo(wcc).params({
projection: "myProj"
}).write({
file: {
filename: "wcc"
}
})
结果:
_id,community_id
Anna,4827860999564427272
Joe,4827860999564427272
Sam,4827860999564427272
Mike,6413128068398841858
Bill,4827860999564427272
Cathy,6413128068398841858
Alice,4827860999564427272
Bob,4827860999564427272
数据库回写
将结果中的community_id值写入指定点属性。该属性类型为uint64。
CALL algo.wcc.write("myProj", {}, {
db: {
property: "wcc_id"
}
})
algo(wcc).params({
projection: "myProj"
}).write({
db: {
property: "wcc_id"
}
})