HDC
概述
HANP(Hop Attenuation & Node Preference,跳跃衰减和节点倾向性)算法在标签传播算法(LPA)的基础上引入了标签分值衰减机制,并考虑邻居节点的度对邻居标签权重的影响。HANP的目标是提高网络中社区检测的准确性和鲁棒性。该算法由Ian X.Y. Leung等人于2009年提出:
- I.X.Y. Leung, P. Hui, P. Liò, J. Crowcroft, Towards real-time community detection in large networks (2009)
基本概念
跳跃衰减
HANP算法赋予每个标签一个分值,该分值随着标签从其原点向远传播而逐渐降低。所有标签的初始分值均为1。当某节点从其邻域采用一个新标签时,新标签在该节点上的分值会在原分值基础上减去一个跳跃衰减因子δ(0 < δ < 1)的大小。
跳跃衰减机制限制标签只向附近的节点传播,能防止某标签在网络中传播得太广从而形成过大的社区。
节点倾向性
在计算新的最大标签时,HANP包含基于节点度的倾向性。当节点j∈Ni将其标签L传播到节点i时,标签L的权重计算公式为:
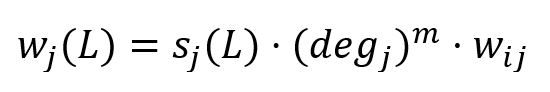
其中,
- sj(L)是标签L在节点j上的分值。
- degj是节点j的度。当m>0 时,倾向于度较大的节点;当m<0时,倾向于度较小的节点;当m=0 时,对节点度没有倾向性。
- wij是节点i和j之间所有边的权重和。
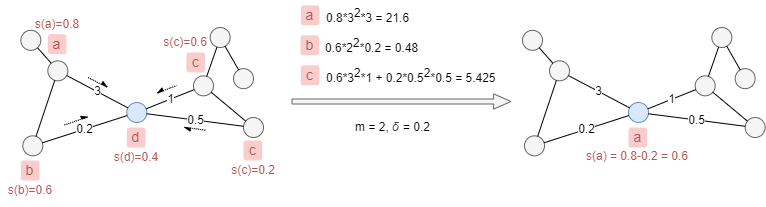
以下的示例中包含边权重,标签分值写在标签旁,设置m=2以及δ=0.2,蓝色节点的标签将从d更新为a,标签a在蓝色节点上的分值衰减至0.6。
特殊说明
- HANP忽略边的方向,按照无向边进行计算。
- 具有自环边的节点能将自身当前的标签传播给自身,并且每条自环边计算两次。
- 如果节点选择的标签与当前自身的标签一致,δ=0。
- HANP在更新节点标签时遵循同步更新原则,即所有节点会根据其邻居的标签同时更新其标签。由于引入了标签分值,HANP通常不会出现标签振荡。
- 受节点顺序、同权重标签的随机选取以及并行计算等因素的影响,HANP算法的社区划分结果可能会不同。
示例图
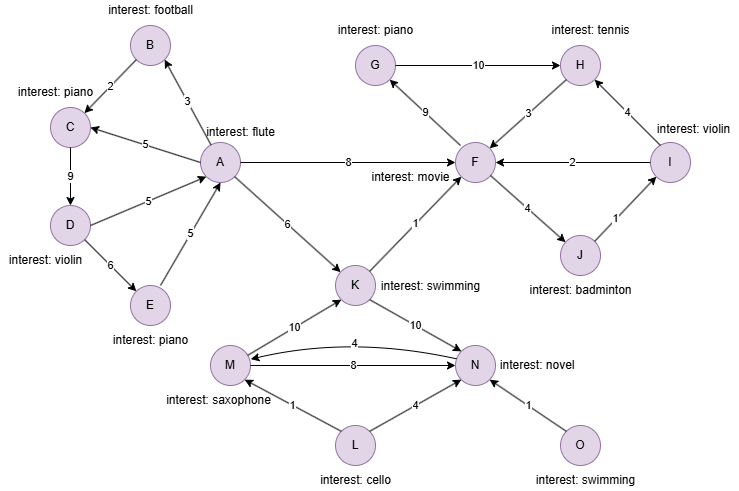
在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
user ({interest string})
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
connect ()-[{strength int32}]->()
};
INSERT (A:user {_id:"A",interest:"flute"}),
(B:user {_id:"B",interest:"football"}),
(C:user {_id:"C",interest:"piano"}),
(D:user {_id:"D",interest:"violin"}),
(E:user {_id:"E",interest:"piano"}),
(F:user {_id:"F",interest:"movie"}),
(G:user {_id:"G",interest:"piano"}),
(H:user {_id:"H",interest:"tennis"}),
(I:user {_id:"I",interest:"violin"}),
(J:user {_id:"J",interest:"badminton"}),
(K:user {_id:"K",interest:"swimming"}),
(L:user {_id:"L",interest:"cello"}),
(M:user {_id:"M",interest:"saxophone"}),
(N:user {_id:"N",interest:"novel"}),
(O:user {_id:"O",interest:"swimming"}),
(A)-[:connect {strength:3}]->(B),
(A)-[:connect {strength:5}]->(C),
(A)-[:connect {strength:8}]->(F),
(A)-[:connect {strength:6}]->(K),
(B)-[:connect {strength:2}]->(C),
(C)-[:connect {strength:9}]->(D),
(D)-[:connect {strength:5}]->(A),
(D)-[:connect {strength:6}]->(E),
(E)-[:connect {strength:5}]->(A),
(F)-[:connect {strength:9}]->(G),
(F)-[:connect {strength:4}]->(J),
(G)-[:connect {strength:10}]->(H),
(H)-[:connect {strength:3}]->(F),
(I)-[:connect {strength:2}]->(F),
(I)-[:connect {strength:4}]->(H),
(J)-[:connect {strength:1}]->(I),
(K)-[:connect {strength:1}]->(F),
(K)-[:connect {strength:10}]->(N),
(L)-[:connect {strength:1}]->(M),
(L)-[:connect {strength:4}]->(N),
(M)-[:connect {strength:10}]->(K),
(M)-[:connect {strength:8}]->(N),
(N)-[:connect {strength:4}]->(M),
(O)-[:connect {strength:1}]->(N);
create().node_schema("user").edge_schema("connect");
create().node_property(@user,"interest",string).edge_property(@connect,"strength",int32);
insert().into(@user).nodes([{_id:"A",interest:"flute"}, {_id:"B",interest:"football"}, {_id:"C",interest:"piano"}, {_id:"D",interest:"violin"}, {_id:"E",interest:"piano"}, {_id:"F",interest:"movie"}, {_id:"G",interest:"piano"}, {_id:"H",interest:"tennis"}, {_id:"I",interest:"violin"}, {_id:"J",interest:"badminton"}, {_id:"K",interest:"swimming"}, {_id:"L",interest:"cello"}, {_id:"M",interest:"saxophone"}, {_id:"N",interest:"novel"}, {_id:"O",interest:"swimming"}]);
insert().into(@connect).edges([{_from:"A",_to:"B",strength:3}, {_from:"A",_to:"C",strength:5}, {_from:"A",_to:"F",strength:8}, {_from:"A",_to:"K",strength:6}, {_from:"B",_to:"C",strength:2}, {_from:"C",_to:"D",strength:9}, {_from:"D",_to:"A",strength:5}, {_from:"D",_to:"E",strength:6}, {_from:"E",_to:"A",strength:5}, {_from:"F",_to:"G",strength:9}, {_from:"F",_to:"J",strength:4}, {_from:"G",_to:"H",strength:10}, {_from:"H",_to:"F",strength:3}, {_from:"I",_to:"H",strength:4}, {_from:"I",_to:"F",strength:2}, {_from:"J",_to:"I",strength:1}, {_from:"K",_to:"F",strength:1}, {_from:"K",_to:"N",strength:10}, {_from:"L",_to:"M",strength:1}, {_from:"L",_to:"N",strength:4}, {_from:"M",_to:"N",strength:8}, {_from:"M",_to:"K",strength:10}, {_from:"N",_to:"M",strength:4}, {_from:"O",_to:"N",strength:1}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:hanp
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
node_label_property |
"<@schema.?><property>" |
/ | / | 是 | 用于初始化节点标签的数值类型或字符串类型点属性;不包含指定属性的点将被忽略。若未设置,则由系统自动生成标签 |
edge_weight_property |
"<@schema.?><property>" |
/ | / | 是 | 作为边权重的数值类型边属性 |
m |
Float | / | 0 |
是 | 邻居节点度的幂指数:
|
delta |
Float | [0, 1] | 0 |
是 | 跳跃衰减因子δ |
loop_num |
Integer | ≥1 | 5 |
是 | 传播迭代次数 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
CALL algo.hanp.write("my_hdc_graph", {
return_id_uuid: "id",
loop_num: 10,
edge_weight_property: "strength",
m: 2,
delta: 0.2
}, {
file: {
filename: "hanp"
}
})
algo(hanp).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
loop_num: 10,
edge_weight_property: "strength",
m: 2,
delta: 0.2
}).write({
file: {
filename: "hanp"
}
})
数据库回写
将结果中的label_1与对应的score_1值写入指定点属性。对应属性类型分别为string和float。
CALL algo.hanp.write("my_hdc_graph", {
node_label_property: "@user.interest",
m: 0.1,
delta: 0.3
}, {
db: {
property: "lab"
}
})
algo(hanp).params({
projection: "my_hdc_graph",
node_label_property: "@user.interest",
m: 0.1,
delta: 0.3
}).write({
db: {
property: "lab"
}
})
各点的标签和标签分值被写入新属性lab_1和score_1中。
统计回写
CALL algo.hanp.write("my_hdc_graph", {
node_label_property: "@user.interest",
m: 0.1,
delta: 0.3
}, {
stats: {}
})
algo(hanp).params({
projection: "my_hdc_graph",
node_label_property: "@user.interest",
m: 0.1,
delta: 0.3
}).write({
stats: {}
})
完整返回
CALL algo.hanp.run("my_hdc_graph", {
return_id_uuid: "id",
loop_num: 12,
node_label_property: "@user.interest",
m: 1,
delta: 0.2
}) YIELD r
RETURN r
exec{
algo(hanp).params({
return_id_uuid: "id",
loop_num: 12,
node_label_property: "@user.interest",
m: 1,
delta: 0.2
}) as r
return r
} on my_hdc_graph
流式返回
CALL algo.hanp.stream("my_hdc_graph", {
loop_num: 12,
node_label_property: "@user.interest",
m: 1,
delta: 0.2
}) YIELD r
RETURN r.label_1 AS label, count(r) GROUP BY label
exec{
algo(hanp).params({
loop_num: 12,
node_label_property: "@user.interest",
m: 1,
delta: 0.2
}).stream() as r
group by r.label_1 as label
return table(label, count(r))
} on my_hdc_graph
统计返回
CALL algo.hanp.stats("my_hdc_graph", {
loop_num: 5,
node_label_property: "interest",
m: 0.6,
delta: 0.2
}) YIELD s
RETURN s
exec{
algo(hanp).params({
loop_num: 5,
node_label_property: "interest",
m: 0.6,
delta: 0.2
}).stats() as s
return s
} on my_hdc_graph