HDC
概述
k-Truss算法能识别图中称为Truss(桁架)的最大的、紧密连接的子图。该算法在各个领域都有广泛的应用,包括社交网络、生物网络和交通网络,通过发现密切相关的节点组成的社区或集群,k-Truss算法为复杂网络的结构和连通性提供了有价值的见解。
k-Truss最初由J. Cohen在2005年定义:
- J. Cohen, Trusses: Cohesive Subgraphs for Social Network Analysis (2005)
基本概念
k-Truss
Truss的概念是根据对社交凝聚力的观察而提出的:如果两个人关系紧密,他们很可能也与他人有共同联系。由此创建k-Truss:A和B之间的连接只有在至少k-2个其他人的支持下才被认为是合法的,这些人分别与A和B有连接。换句话说,k-Truss中每条边所连接的两个节点至少有k–2个共同邻居。
正式的定义是,k-Truss是图中的最大子图,其中每条边至少由k-2对边支撑,与该边形成三角形。
下面是一个示例图,其中3-Truss和4-Truss以红色突出显示。此图没有k值为5或更大的Truss。
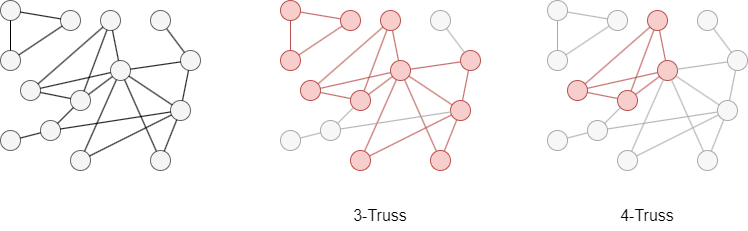
嬴图的k-Truss算法识别图中每个连通分量的最大Truss。
特殊说明
- 每个Truss中至少包含3个节点(当k≥3)。
- 在两点之间可能存在多条边的复杂图中,Truss中的三角形是按边计数的。另请参阅三角形计算算法。
- k-Truss算法忽略边的方向,按照无向边进行计算。
示例图
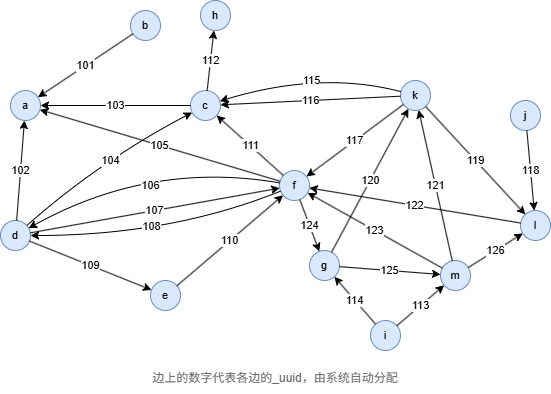
在一个空图中运行以下语句定义图结构并插入数据:
INSERT (a:default {_id: "a"}),
(b:default {_id: "b"}),
(c:default {_id: "c"}),
(d:default {_id: "d"}),
(e:default {_id: "e"}),
(f:default {_id: "f"}),
(g:default {_id: "g"}),
(h:default {_id: "h"}),
(i:default {_id: "i"}),
(j:default {_id: "j"}),
(k:default {_id: "k"}),
(l:default {_id: "l"}),
(m:default {_id: "m"}),
(b)-[:default]->(a),
(d)-[:default]->(a),
(c)-[:default]->(a),
(d)-[:default]->(c),
(f)-[:default]->(a),
(f)-[:default]->(d),
(d)-[:default]->(f),
(f)-[:default]->(d),
(d)-[:default]->(e),
(e)-[:default]->(f),
(f)-[:default]->(c),
(c)-[:default]->(h),
(i)-[:default]->(m),
(i)-[:default]->(g),
(k)-[:default]->(c),
(k)-[:default]->(c),
(k)-[:default]->(f),
(j)-[:default]->(l),
(k)-[:default]->(l),
(g)-[:default]->(k),
(m)-[:default]->(k),
(l)-[:default]->(f),
(m)-[:default]->(f),
(f)-[:default]->(g),
(g)-[:default]->(m),
(m)-[:default]->(l);
insert().into(@default).nodes([{_id:"a"}, {_id:"b"}, {_id:"c"}, {_id:"d"}, {_id:"e"}, {_id:"f"}, {_id:"g"}, {_id:"h"}, {_id:"i"}, {_id:"j"}, {_id:"k"}, {_id:"l"}, {_id:"m"}]);
insert().into(@default).edges([{_from:"b", _to:"a"}, {_from:"d", _to:"a"}, {_from:"c", _to:"a"}, {_from:"d", _to:"c"}, {_from:"f", _to:"a"}, {_from:"f", _to:"d"}, {_from:"d", _to:"f"}, {_from:"f", _to:"d"}, {_from:"d", _to:"e"}, {_from:"e", _to:"f"}, {_from:"f", _to:"c"}, {_from:"c", _to:"h"}, {_from:"i", _to:"m"}, {_from:"i", _to:"g"}, {_from:"k", _to:"c"}, {_from:"k", _to:"c"}, {_from:"k", _to:"f"}, {_from:"j", _to:"l"}, {_from:"k", _to:"l"}, {_from:"g", _to:"k"}, {_from:"m", _to:"k"}, {_from:"l", _to:"f"}, {_from:"m", _to:"f"}, {_from:"f", _to:"g"}, {_from:"g", _to:"m"}, {_from:"m", _to:"l"}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:k_truss
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
k |
Integer | ≥1 | / | 否 | k-Truss子图中,每条边都包含在至少k-2个三角形中 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点。只能使用_uuid来表示边。该选项仅在文件回写模式下生效 |
文件回写
CALL algo.k_truss.write("my_hdc_graph", {
k: 4,
return_id_uuid: "id"
}, {
file: {
filename: "4truss"
}
})
algo(k_truss).params({
projection: "my_hdc_graph",
k: 4,
return_id_uuid: "id"
}).write({
file: {
filename: "4truss"
}
})
结果:
_id
e--[110]--f
k--[117]--f
k--[119]--l
m--[121]--k
m--[123]--f
m--[126]--l
c--[103]--a
g--[120]--k
g--[125]--m
d--[102]--a
d--[104]--c
d--[107]--f
d--[109]--e
f--[105]--a
f--[106]--d
f--[108]--d
f--[111]--c
f--[124]--g
l--[122]--f
完整返回
CALL algo.k_truss.run("my_hdc_graph", {
k: 5
}) YIELD truss
RETURN truss
exec{
algo(k_truss).params({
k: 5
}) as truss
return truss
} on my_hdc_graph
结果:
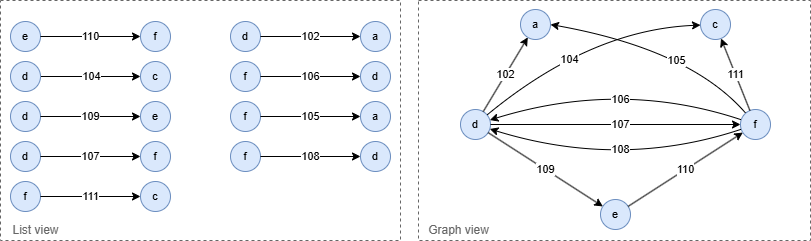
流式返回
CALL algo.k_truss.stream("my_hdc_graph", {
k: 5
}) YIELD truss5
FOR node IN pnodes(truss5)
RETURN collect_list(node._id)
exec{
algo(k_truss).params({
k: 5
}).stream() as truss5
uncollect pnodes(truss5) as node
return collect(node._id)
} on my_hdc_graph
["d","a","d","c","d","f","d","e","f","a","f","d","f","d","f","c","e","f"]