HDC
概述
K最近邻(kNN, k-NearestNeighbor)算法,也称最近邻算法,是一种根据目标节点的k个最近(最相似)节点的分类对目标节点进行分类的技术。kNN由T.M. Cover和P.E. Hart于1967年提出,此后成为最广泛使用的分类算法之一:
- T.M. Cover, P.E. Hart, Nearest Neighbor Pattern Classification (1967)
尽管名称中包含单词“邻居”,但 kNN 在计算相似性时并不明确考虑节点之间的边,它只关注节点的属性。
基本概念
相似度指标
嬴图的kNN算法计算目标节点与图中所有其他节点之间的余弦相似度,然后选择与目标节点相似度最高的k个节点。
选举分类
用节点的某个属性作为分类标签。找到与目标节点最近的k个节点后,将k个节点中出现次数最多的标签分配给目标节点。
如果出现次数最多的标签有多个,则选取其中相似度相最高的节点的标签。
示例图
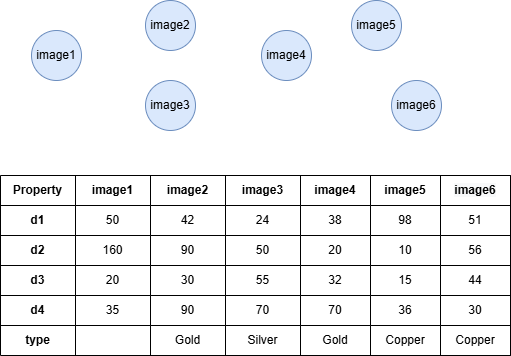
在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
image ({d1 int32, d2 int32, d3 int32, d4 int32, type string})
};
INSERT (:image {_id: "image1", d1: 50, d2: 160, d3: 20, d4: 35}),
(:image {_id: "image2", d1: 42, d2: 90, d3: 30, d4: 90, type: "Gold"}),
(:image {_id: "image3", d1: 24, d2: 50, d3: 55, d4: 70, type: "Silver"}),
(:image {_id: "image4", d1: 38, d2: 20, d3: 32, d4: 70, type: "Gold"}),
(:image {_id: "image5", d1: 98, d2: 10, d3: 15, d4: 36, type: "Copper"}),
(:image {_id: "image6", d1: 51, d2: 56, d3: 44, d4: 30, type: "Copper"});
create().node_schema("image");
create().node_property(@image,"d1",int32).node_property(@image,"d2",int32).node_property(@image,"d3",int32).node_property(@image,"d4",int32).node_property(@image,"type",string);
insert().into(@image).nodes([{_id:"image1", d1:50, d2:160, d3:20, d4:35}, {_id:"image2", d1:42, d2:90, d3:30, d4:90, type:"Gold"}, {_id:"image3", d1:24, d2:50, d3:55, d4:70, type:"Silver"}, {_id:"image4", d1:38, d2:20, d3:32, d4:70, type:"Gold"}, {_id:"image5", d1:98, d2:10, d3:15, d4:36, type:"Copper"}, {_id:"image6", d1:51, d2:56, d3:44, d4:30, type:"Copper"}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:knn
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
node_id |
_uuid |
/ | / | 否 | 通过_uuid指定目标节点 |
node_schema_property |
[]"<@schema.?><property>" |
/ | / | 否 | 用于计算余弦相似度的数值类型点属性;需包含至少两个属性。点的schema必须与目标节点相同 |
top_k |
Integer | >0 | / | 否 | 待选取的最近节点数 |
target_schema_property |
"<@schema.?><property>" |
/ | / | 否 | 作为分类标签的数值类型或字符串类型点属性。点的schema必须与目标节点相同 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
文件回写
CALL algo.knn.write("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}, {
file: {
filename: "knn"
}
})
algo(knn).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).write({
file: {
filename: "knn"
}
})
结果:
Gold:2
top k(_id):
image2,0.85516
image6,0.841922
image3,0.705072
image4,0.538975
文件第一行代表k个最近点中出现最多的标签及其数量。从第三行起,显示与目标节点最相似的k个点及对应的相似度分数。
统计回写
CALL algo.knn.write("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}, {
stats: {}
})
algo(knn).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).write({
stats: {}
})
结果:
| attribute_value | count |
|---|---|
| Gold | 2 |
完整返回
CALL algo.knn.run("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) YIELD r
RETURN r
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) as r
return r
} on my_hdc_graph
结果:
| _ids | similarity |
|---|---|
| image2 | 0.85516 |
| image6 | 0.841922 |
| image3 | 0.705072 |
| image4 | 0.538975 |
流式返回
CALL algo.knn.stream("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "type"
}) YIELD r
RETURN r
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "type"
}).stream() as r
return r
} on my_hdc_graph
结果:
| _ids | similarity |
|---|---|
| image2 | 0.85516 |
| image6 | 0.841922 |
| image3 | 0.705072 |
| image4 | 0.538975 |
统计返回
CALL algo.knn.stats("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) YIELD s
RETURN s
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).stats() as s
return s
} on my_hdc_graph
结果:
| attribute_value | count |
|---|---|
| Gold | 2 |