概述
LINE(Large-scale Information Network Embedding,大规模信息网络嵌入)作为一种图嵌入模型,能够保留网络的局部或全局结构特征,能应用到各类非常大型的网络上。LINE算法最初是在2015年提出的:
- J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, Q. Zhu, LINE: Large-scale Information Network Embedding (2015)
基本概念
一阶相似度和二阶相似度
网络中两个节点的一阶相似度(First-order Proximity)取决于相连关系,它们之间存在边或存在较大权重的边(此处不考虑负权重),则表示一阶相似度更高。如果两个节点之间不存在边,则它们的一阶相似度为0。
另一方面,一对节点之间的二阶相似度(Second-order Proximity)则表示它们邻域结构之间的相似性,这是通过共同邻居确定的。如果两个节点没有共同邻居,则它们的二阶相似度为 0。
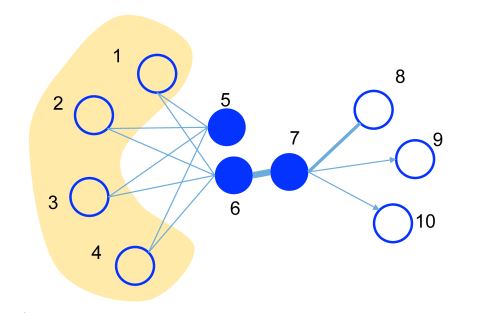
在此图示中,边的粗细代表权重大小。
- 节点6和7在嵌入空间的位置应该很接近,因为它们之间的边权重很高,具有一阶相似度。
- 虽然节点5和6之间没有边相连,但它们有很多共同邻居,也应该被嵌入到相互靠近的位置,因为它们具有二阶相似性。
LINE模型
LINE模型的设计旨在将图G = (V,E)中的节点嵌入到较低维的向量空间,保留节点间的一阶相似度或二阶相似度。
一阶相似度
对于每条边(i,j) ∈ E,LINE模型定义其两个端点vi和vj间的联合概率为:
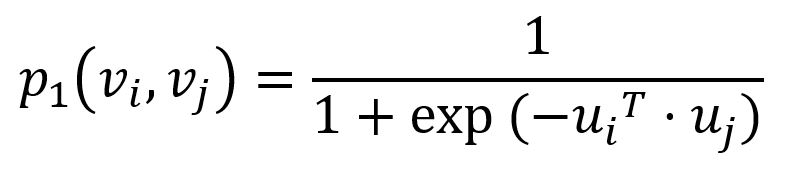
其中ui是节点vi在嵌入空间的表示。联合概率p1的取值范围是0到1,两个向量越接近,它们的点积越大,联合概率就越高。
同时定义节点vi和vj之间联合概率的经验分布为:
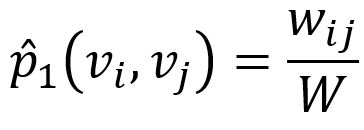
其中wij表示节点vi和vj 间的边权重,W是图中所有边的权重和。
LINE采用KL散度衡量这两个概率分布的差异:
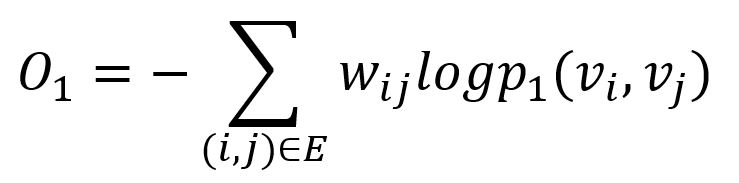
这是模型保留一阶相似度训练时需要最小化的目标函数。
二阶相似度
为了捕获二阶相似度,LINE为每个节点定义两种身份:一是节点自身,二是作为其他节点的上下文(这个概念来自 Skip-gram模型)。相应地,每个节点对应两种不同的向量表示。
对于每条边(i,j) ∈ E,LINE定义在节点vi周围观察到上下文节点vj的概率为:
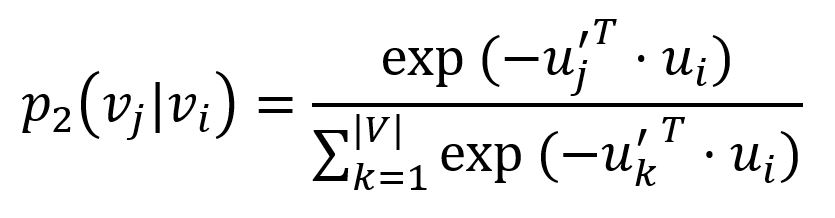
其中u'j是节点vj被视为上下文时的向量表示。重要的是,上式的分母涵盖图中所有的上下文。
对应的经验概率定义为:
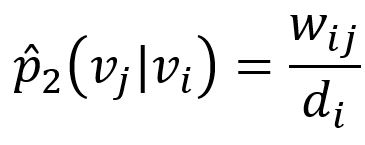
其中wij表示边(i,j)权重,di表示节点vi的加权度。
类似地,LINE采用KL散度来衡量两个概率分布的差异:
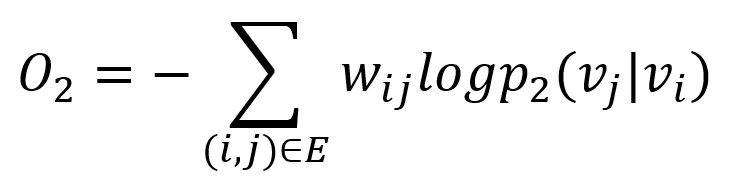
这是模型保留二阶相似度训练时需要最小化的目标函数。
模型优化
负采样
为了提高计算效率,LINE采用负采样技术根据噪声分布为每条边(i,j)选择若干负样本(边)。具体来说,两个目标函数调整为:
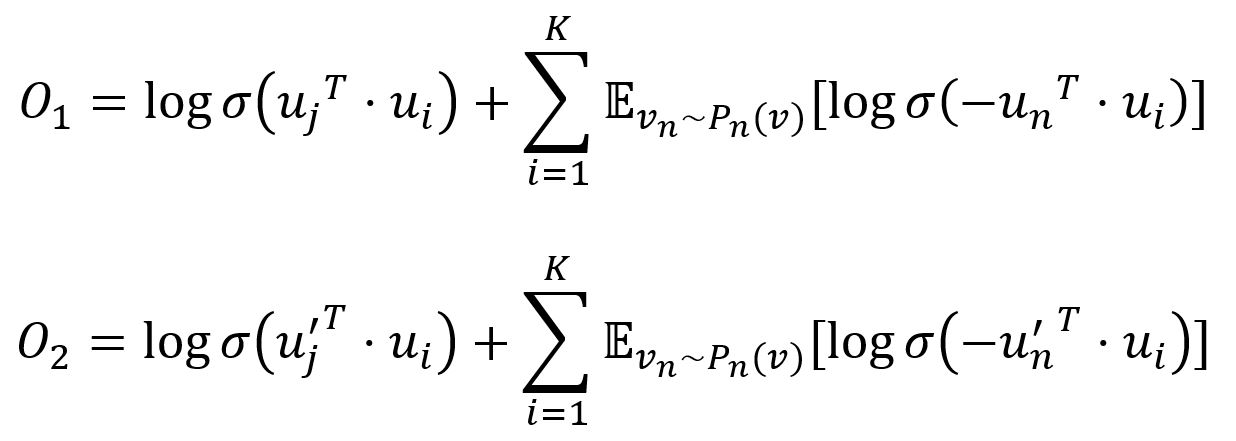
其中,σ是Sigmoid函数,K个负样本是依据噪声分布Pn(v) ∝ dv3/4选取的,dv是节点v的加权度。
边采样
两个目标函数中都包含边权重,这些权重与梯度相乘可能导致梯度爆炸,从而影响性能。为了解决这个问题,LINE以与边权重成正比的概率对边进行采样,然后将采样的边视为二进制边。
特殊说明
- LINE算法忽略边的方向,按照无向边进行计算。
示例图
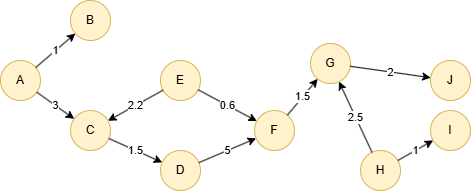
在一个空图中运行以下语句定义图结构并插入数据:
ALTER EDGE default ADD PROPERTY {
score float
};
INSERT (A:default {_id: "A"}),
(B:default {_id: "B"}),
(C:default {_id: "C"}),
(D:default {_id: "D"}),
(E:default {_id: "E"}),
(F:default {_id: "F"}),
(G:default {_id: "G"}),
(H:default {_id: "H"}),
(I:default {_id: "I"}),
(J:default {_id: "J"}),
(A)-[:default {score: 1}]->(B),
(A)-[:default {score: 3}]->(C),
(C)-[:default {score: 1.5}]->(D),
(D)-[:default {score: 5}]->(F),
(E)-[:default {score: 2.2}]->(C),
(E)-[:default {score: 0.6}]->(F),
(F)-[:default {score: 1.5}]->(G),
(G)-[:default {score: 2}]->(J),
(H)-[:default {score: 2.5}]->(G),
(H)-[:default {score: 1}]->(I);
create().edge_property(@default, "score", float);
insert().into(@default).nodes([{_id:"A"},{_id:"B"},{_id:"C"},{_id:"D"},{_id:"E"},{_id:"F"},{_id:"G"},{_id:"H"},{_id:"I"},{_id:"J"}]);
insert().into(@default).edges([{_from:"A", _to:"B", score:1}, {_from:"A", _to:"C", score:3}, {_from:"C", _to:"D", score:1.5}, {_from:"D", _to:"F", score:5}, {_from:"E", _to:"C", score:2.2}, {_from:"E", _to:"F", score:0.6}, {_from:"F", _to:"G", score:1.5}, {_from:"G", _to:"J", score:2}, {_from:"H", _to:"G", score:2.5}, {_from:"H", _to:"I", score:1}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:line
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
edge_schema_property |
[]"@<schema>?.<property>" |
/ | / | 否 | 作为权重的数值类型边属性,权重值为所有指定属性值的总和;不包含指定属性的边将被忽略 |
dimension |
Integer | ≥2 | / | 否 | 嵌入向量的维度 |
train_total_num |
Integer | ≥1 | / | 否 | 训练迭代总次数 |
train_order |
Integer | 1, 2 |
1 |
是 | 要保留的相似度类型,1为一阶相似度,2为二阶相似度 |
learning_rate |
Float | (0,1) | / | 否 | 模型训练的初始学习率,在每轮训练迭代后逐渐减少,直至达到min_learning_rate |
min_learning_rate |
Float | (0,learning_rate) |
/ | 否 | 学习率的最低阈值,在训练过程中逐渐减少 |
neg_num |
Integer | ≥1 | / | 是 | 每个正样本生成的负样本数量,建议设置在1到10之间 |
resolution |
Integer | ≥1 | 1 |
是 | 用于提高负采样效率的参数;数值越高,越能更好地接近原始噪声分布;建议设置为10、100等 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
CALL algo.line.write("my_hdc_graph", {
return_id_uuid: "id",
edge_schema_property: "score",
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 5,
resolution: 100
}, {
file: {
filename: "embeddings"
}
})
algo(line).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
edge_schema_property: "score",
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 5,
resolution: 100
}).write({
file:{
filename: 'embeddings'
}
})
_id,embedding_result
J,0.134156,0.147224,-0.127542,
D,-0.110004,0.0445883,0.101143,
F,0.0306388,0.00733918,-0.11945,
H,0.0739559,-0.145214,0.0416526,
B,-0.02514,-0.0317756,-0.110371,
A,-0.0629673,0.0857267,0.100926,
E,0.0989685,0.0532481,0.0514933,
C,-0.127659,-0.136062,0.166552,
I,0.126709,0.103002,-0.0201314,
G,0.134589,-0.0157018,0.0237946,
数据库回写
将结果中的embedding_result值写入指定点属性。该属性类型为float[]。
CALL algo.line.write("my_hdc_graph", {
return_id_uuid: "id",
edge_schema_property: "score",
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 5,
resolution: 100
}, {
db: {
property: "vector"
}
})
algo(line).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
edge_schema_property: "score",
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 5,
resolution: 100
}).write({
db: {
property: "vector"
}
})
完整返回
CALL algo.line.run("my_hdc_graph", {
return_id_uuid: "id",
edge_schema_property: '@default.score',
dimension: 4,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001
}) YIELD embeddings
RETURN embeddings
exec{
algo(line).params({
return_id_uuid: "id",
edge_schema_property: '@default.score',
dimension: 4,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001
}) as embeddings
return embeddings
} on my_hdc_graph
结果:
_id |
embedding_result |
|---|---|
| J | [0.10039449483156204,0.11040361225605011,-0.095774807035923,-0.0819125771522522] |
| D | [0.0338507741689682,0.07575879991054535,0.023179633542895317,0.005116916261613369] |
| F | [-0.08940199762582779,0.05569583922624588,-0.10888427495956421,0.03145558759570122] |
| H | [-0.018580902367830276,-0.024093549698591232,-0.08332693576812744,-0.04651310294866562] |
| B | [0.0645807683467865,0.07539491355419159,0.07396885752677917,0.040248531848192215] |
| A | [0.03878217190504074,-0.09487584978342056,-0.10220742225646973,0.12434131652116776] |
| E | [0.09489674866199493,0.07733562588691711,-0.015262083150446415,0.10043458640575409] |
| C | [-0.01225052960216999,0.018636001273989677,-0.0036492166109383106,-0.0745576024055481] |
| I | [0.0327218696475029,-0.033543504774570465,-0.09600748121738434,0.11864277720451355] |
| G | [0.1094101220369339,-0.02683556079864502,-0.006420814897865057,0.012586096301674843] |
流式返回
CALL algo.line.stream("my_hdc_graph", {
return_id_uuid: "id",
edge_schema_property: '@default.score',
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001
}) YIELD embeddings
RETURN embeddings
exec{
algo(line).params({
return_id_uuid: "id",
edge_schema_property: '@default.score',
dimension: 3,
train_total_num: 10,
train_order: 1,
learning_rate: 0.01,
min_learning_rate: 0.0001
}).stream() as embeddings
return embeddings
} on my_hdc_graph
结果:
_id |
embedding_result |
|---|---|
| J | [0.13375547528266907,0.14727242290973663,-0.12761451303958893] |
| D | [-0.10898537188768387,0.045617908239364624,0.09961149096488953] |
| F | [0.030374202877283096,0.0074587357230484486,-0.11920187622308731] |
| H | [0.0746561735868454,-0.1447625607252121,0.04158430173993111] |
| B | [-0.02504475973546505,-0.0319061279296875,-0.1105244979262352] |
| A | [-0.0629904493689537,0.08570709079504013,0.1011749655008316] |
| E | [0.09852229058742523,0.0527675524353981,0.05207677558064461] |
| C | [-0.1265311986207962,-0.1361672431230545,0.16603653132915497] |
| I | [0.12704375386238098,0.10234453529119492,-0.0199428740888834] |
| G | [0.1342623233795166,-0.016277270391583443,0.0242084339261055] |