HDC
概述
p-Cohesion算法能识别网络中彼此高度关联的一组参与者(节点),并由内聚子图(Cohesive Subgraph)表示。通过了解各组内的连通性和相互依赖程度,该算法能够帮助深入分析图结构及其影响。
p-Cohesion的概念最初是由S. Morris在大群人相互作用的传染模型中提出的:
- S. Morris, Contagion. The Review of Economic Studies, 67(1), 57–78 (2000)
基本概念
p-Cohesion
关于群体的Cohesion(凝聚力),一个很自然的衡量标准是:与非成员相比,群体内成员之间互相联系的相对概率。令常数p∈(0,1),p-Cohesion是一个连通子图,其中每个节点至少有占比为p的邻居在该子图中,每个节点在子图外的邻居占比不超过(1−p)。
与其他内聚子图模型相比,p-Cohesion模型具有两个明显的优势:
- p值较大时,p-Cohesion能同时保证内部的凝聚性和外部的稀疏性。
- 在很多场景下,由于图中各节点度的差异,考虑邻居的占比相较于考虑固定的邻居数(比如 k-Core)更为合适。
在下面的示例图中,假设p=0.6,每个节点旁的灰色标签表示该节点在p-cohesion中所需的最小邻居数。
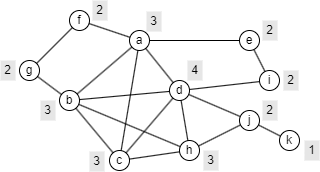
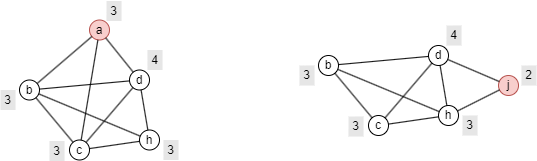
以下分别是包含节点a和节点j的最小(指节点数量)p-cohesion 子图。
嬴图的p-Cohesion算法寻找包含查询节点的近似最小p-cohesion子图,并以节点集的形式返回子图。
特殊说明
- p-Cohesion算法忽略边的方向,按照无向边进行计算。
示例图
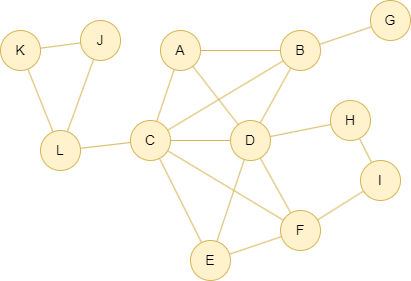
在一个空图中运行以下语句定义图结构并插入数据:
INSERT (A:default {_id: "A"}),
(B:default {_id: "B"}),
(C:default {_id: "C"}),
(D:default {_id: "D"}),
(E:default {_id: "E"}),
(F:default {_id: "F"}),
(G:default {_id: "G"}),
(H:default {_id: "H"}),
(I:default {_id: "I"}),
(J:default {_id: "J"}),
(K:default {_id: "K"}),
(L:default {_id: "L"}),
(K)-[:default]->(J),
(K)-[:default]->(L),
(J)-[:default]->(L),
(L)-[:default]->(C),
(C)-[:default]->(A),
(A)-[:default]->(B),
(C)-[:default]->(B),
(A)-[:default]->(D),
(B)-[:default]->(G),
(B)-[:default]->(D),
(D)-[:default]->(C),
(C)-[:default]->(E),
(C)-[:default]->(F),
(D)-[:default]->(E),
(E)-[:default]->(F),
(D)-[:default]->(F),
(D)-[:default]->(H),
(I)-[:default]->(H),
(F)-[:default]->(I);
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}, {_id:"G"}, {_id:"H"}, {_id:"I"}, {_id:"J"}, {_id:"K"}, {_id:"L"}]);
insert().into(@default).edges([{_from:"K", _to:"J"}, {_from:"K", _to:"L"}, {_from:"J", _to:"L"}, {_from:"L", _to:"C"}, {_from:"C", _to:"A"}, {_from:"A", _to:"B"}, {_from:"C", _to:"B"}, {_from:"A", _to:"D"}, {_from:"B", _to:"G"}, {_from:"B", _to:"D"}, {_from:"D", _to:"C"}, {_from:"C", _to:"E"}, {_from:"C", _to:"F"}, {_from:"D", _to:"E"}, {_from:"E", _to:"F"}, {_from:"D", _to:"F"}, {_from:"D", _to:"H"}, {_from:"I", _to:"H"}, {_from:"F", _to:"I"}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:p_cohesion
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
ids |
[]_id |
/ | / | 是 | 通过_id指定目标点,查找包含目标点的近似最小p-Cohesion子图;若未设置则指定所有点 |
uuids |
[]_uuid |
/ | / | 是 | 通过_uuid指定目标点,查找包含目标点的近似最小p-Cohesion子图;若未设置则指定所有点 |
p |
Float | (0,1) | / | 否 | p-Cohesion子图中,每个点至少有占比为p的邻居在该子图中,在子图外的邻居数占比不超过(1−p) |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
文件回写
CALL algo.p_cohesion.write("my_hdc_graph", {
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}, {
file: {
filename: "cohesion"
}
})
algo(p_cohesion).params({
projection: "my_hdc_graph",
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}).write({
file: {
filename: "cohesion"
}
})
结果:
subgraph contains A: D,F,B,A,E,C,
subgraph contains I: I,D,F,H,B,A,E,C,
统计回写
CALL algo.p_cohesion.write("my_hdc_graph", {
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}, {
stats: {}
})
algo(p_cohesion).params({
projection: "my_hdc_graph",
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}).write({
stats: {}
})
结果:
| max size of subgraphs |
|---|
| 8 |
流式返回
CALL algo.p_cohesion.stream("my_hdc_graph", {
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}) YIELD s
RETURN s
exec{
algo(p_cohesion).params({
ids: ["A","I"],
p: 0.7,
return_id_uuid: "id"
}).stream() as s
return s
} on my_hdc_graph
结果:
| subgraph contains(id) | _ids |
|---|---|
| A | [D,F,B,A,E,C] |
| I | [D,F,H,B,A,E,C,I] |
统计返回
CALL algo.p_cohesion.stats("my_hdc_graph", {
ids: ["A","I"],
p: 0.7
}) YIELD s
RETURN s
exec{
algo(p_cohesion).params({
ids: ["A","I"],
p: 0.7
}).stats() as s
return s
} on my_hdc_graph
结果:
| max size of subgraphs |
|---|
| 8 |