概述
最短路径快速算法(Shortest Path Faster Algorithm, SPFA)是贝尔曼-福特(Bellman–Ford)算法的改进版本,用于计算图中源节点到所有可达节点的最短路径,即单源最短路径(Single-Source Shortest Paths, SSSP)。该算法适用于包含负权重边的图。
SPFA算法最早由E.F. Moore于1959年发表,但“最短路径快速算法(SPFA)”这个名称是由FanDing Duan在1994年重新发现该算法时赋予的。
- F. Duan, 关于最短路径的SPFA快速算法 [About the SPFA algorithm] (1994)
基本概念
SPFA
给定一个图G=(V, E)和一个源节点s∈V,使用数组d[]来存储从s到所有节点的最短路径距离。初始化d[]中的所有元素为无穷大,除了d[s] = 0。
SPFA的基本思想与贝尔曼-福特算法相同,即每个节点都被用作松弛其邻居节点的候选节点(Candidate)。相对于后者的改进在于,SPFA维护一个先进先出的队列Q来存储候选节点,并且只有被松弛的节点才会被添加到队列中。
松弛操作是指通过考虑经过节点u的路径,更新与节点u相连的节点v的距离,使其获得可能的更短距离。具体来说,节点v的距离会被更新为d[v] = d[u] + w(u,v),其中w(u,v)是边(u,v)的权重。此更新仅在当前d[v]大于d[u] + w(u,v)时进行。
算法开始时,除了源节点,所有节点的距离都被设为无穷大,因此源节点被视为第一个被松弛并推入队列的节点。
在每次迭代中,SPFA从队列Q中出队一个节点u作为候选节点。对于图中的每条边(u,v),如果节点v可以被松弛,则执行以下步骤:
- 松弛节点v:d[v] = d[v] + w(u,v)。
- 如果v不在队列Q中,则将节点v推入队列Q。
一直重复这个过程,直到没有更多的节点可以被松弛。
下面的步骤说明了SPFA如何计算以A为源节点的出边方向的带权最短路径:
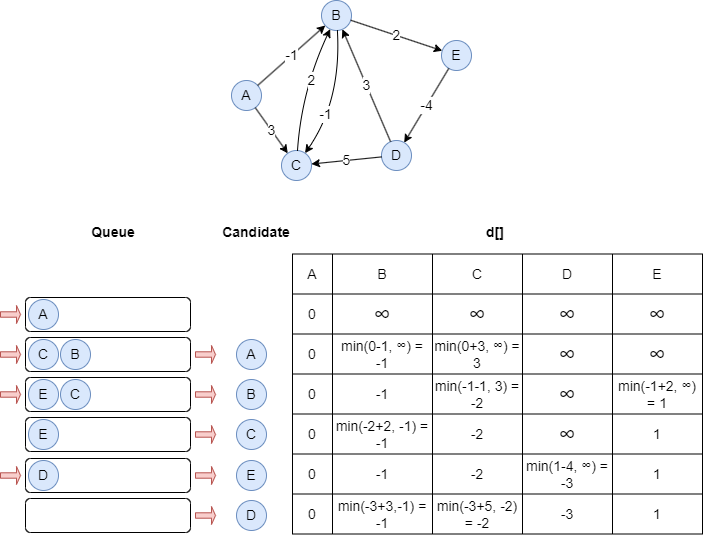
特殊说明
- SPFA能够处理具有负权重边的图,前提是(1)源节点无法访问任何位于负循环(Negative Cycle)中的节点,以及(2)最短路径是有向的。负循环是指边权重之和为负的循环。如果存在负循环,或者存在负权重但最短路径是无向的,该算法将产生距离为无限的结果。这是因为算法会在负循环内或负边上反复遍历,导致每次的距离都不断减小。
- 如果两个节点之间存在多条最短路径,算法会找出所有这些路径。
- 在非连通图中,算法只输出源节点所在的连通分量内所有节点到源节点的最短距离。
示例图
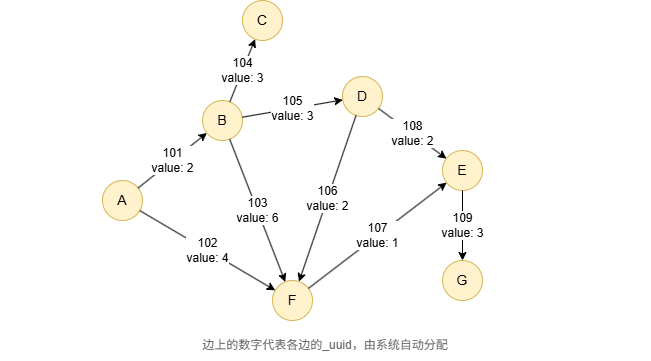
在一个空图中运行以下语句定义图结构并插入数据:
ALTER EDGE default ADD PROPERTY {
value int32
};
INSERT (A:default {_id: "A"}),
(B:default {_id: "B"}),
(C:default {_id: "C"}),
(D:default {_id: "D"}),
(E:default {_id: "E"}),
(F:default {_id: "F"}),
(G:default {_id: "G"}),
(A)-[:default {value: 2}]->(B),
(A)-[:default {value: 4}]->(F),
(B)-[:default {value: 3}]->(C),
(B)-[:default {value: 3}]->(D),
(B)-[:default {value: 6}]->(F),
(D)-[:default {value: 2}]->(E),
(D)-[:default {value: 2}]->(F),
(E)-[:default {value: 3}]->(G),
(F)-[:default {value: 1}]->(E);
create().edge_property(@default, "value", int32);
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}, {_id:"G"}]);
insert().into(@default).edges([{_from:"A", _to:"B", value:2}, {_from:"A", _to:"F", value:4}, {_from:"B", _to:"F", value:6}, {_from:"B", _to:"C", value:3}, {_from:"B", _to:"D", value:3}, {_from:"D", _to:"F", value:2}, {_from:"F", _to:"E", value:1}, {_from:"D", _to:"E", value:2}, {_from:"E", _to:"G", value:3}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:sssp
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
ids |
_id |
/ | / | 否 | 通过_id指定单个源节点 |
uuids |
_uuid |
/ | / | 否 | 通过_uuid指定单个源节点 |
direction |
String | in, out |
/ | 是 | 指定最短路径中所有边的方向,in表示仅包含入边,out表示仅包含出边;若未设置则不考虑边方向 |
edge_schema_property |
[]"<@schema.?><property>" |
/ | / | 是 | 作为权重的数值类型边属性,权重值为所有指定属性值的总和;不包含指定属性的边将被忽略 |
record_path |
Integer | 0, 1 |
0 |
是 | 是否在结果中包含最短路径。设定为1时,返回totalCost和最短路径;设置为0时,仅返回totalCost |
impl_type |
String | spfa |
beta |
否 | 指定SSSP算法的执行类型;计算SPFA时,设置为spfa;beta是嬴图默认最短路径算法 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点。仅可使用_uuid表示边 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
order |
String | asc, desc |
/ | 是 | 根据totalCost值对结果排序 |
文件回写
CALL algo.sssp.write("my_hdc_graph", {
ids: "A",
edge_schema_property: "@default.value",
impl_type: "spfa",
return_id_uuid: "id"
}, {
file: {
filename: "costs"
}
})
algo(sssp).params({
projection: "my_hdc_graph",
ids: "A",
edge_schema_property: "@default.value",
impl_type: "spfa",
return_id_uuid: "id"
}).write({
file: {
filename: "costs"
}
})
结果:
_id,totalCost
D,5
F,4
B,2
E,5
C,5
G,8
CALL algo.sssp.write("my_hdc_graph", {
ids: "A",
edge_schema_property: "@default.value",
impl_type: "spfa",
record_path: 1,
return_id_uuid: "id"
}, {
file: {
filename: "paths"
}
})
algo(sssp).params({
projection: "my_hdc_graph",
ids: "A",
edge_schema_property: "@default.value",
impl_type: "spfa",
record_path: 1,
return_id_uuid: "id"
}).write({
file: {
filename: "paths"
}
})
结果:
totalCost,_ids
8,A--[102]--F--[107]--E--[109]--G
5,A--[101]--B--[105]--D
5,A--[102]--F--[107]--E
5,A--[101]--B--[104]--C
4,A--[102]--F
2,A--[101]--B
完整返回
CALL algo.sssp.run("my_hdc_graph", {
ids: 'A',
edge_schema_property: 'value',
impl_type: 'spfa',
record_path: 0,
return_id_uuid: 'id',
order: 'desc'
}) YIELD r
RETURN r
exec{
algo(sssp).params({
ids: 'A',
edge_schema_property: 'value',
impl_type: 'spfa',
record_path: 0,
return_id_uuid: 'id',
order: 'desc'
}) as r
return r
} on my_hdc_graph
结果:
| _id | totalCost |
|---|---|
| G | 8 |
| D | 5 |
| E | 5 |
| C | 5 |
| F | 4 |
| B | 2 |
流式返回
CALL algo.sssp.stream("my_hdc_graph", {
ids: 'A',
edge_schema_property: '@default.value',
impl_type: 'spfa',
record_path: 1,
return_id_uuid: 'id'
}) YIELD r
RETURN r
exec{
algo(sssp).params({
ids: 'A',
edge_schema_property: '@default.value',
impl_type: 'spfa',
record_path: 1,
return_id_uuid: 'id'
}).stream() as r
return r
} on my_hdc_graph
结果:
totalCost |
_ids |
|---|---|
| 8 | ["A","102","F","107","E","109","G"] |
| 5 | ["A","101","B","105","D"] |
| 5 | ["A","102","F","107","E"] |
| 5 | ["A","101","B","104","C"] |
| 4 | ["A","102","F"] |
| 2 | ["A","101","B"] |