HDC
概述
总邻居(Total Neighbors)算法计算两个节点不重复的邻居总数,作为衡量它们相似性的指标。
该算法考虑两个节点的整个邻域,相对于只关注共同邻居的算法,给出了更全面的相似性视角。它的计算公式如下:
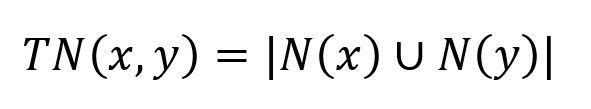
其中,N(x)和N(y)分别是与节点x和节点y相连的节点集合。
总邻居数量较多表示节点间的相似度较大,数量为0则表示两个节点间没有相似性。
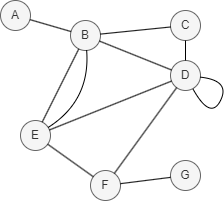
在上图中,TN(D,E) = |N(D) ∪ N(E)| = |{B, C, E, F} ∪ {B, D, F}| = |{B, C, D, E, F}| = 5。
特殊说明
- 总邻居算法忽略边的方向,按照无向边进行计算。
示例图
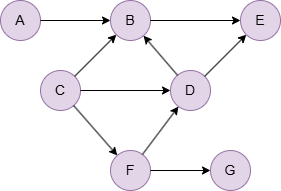
在一个空图中运行以下语句定义图结构并插入数据:
INSERT (A:default {_id: "A"}),
(B:default {_id: "B"}),
(C:default {_id: "C"}),
(D:default {_id: "D"}),
(E:default {_id: "E"}),
(F:default {_id: "F"}),
(G:default {_id: "G"}),
(A)-[:default]->(B),
(B)-[:default]->(E),
(C)-[:default]->(B),
(C)-[:default]->(D),
(C)-[:default]->(F),
(D)-[:default]->(B),
(D)-[:default]->(E),
(F)-[:default]->(D),
(F)-[:default]->(G);
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}, {_id:"G"}]);
insert().into(@default).edges([{_from:"A", _to:"B"}, {_from:"B", _to:"E"}, {_from:"C", _to:"B"}, {_from:"C", _to:"D"}, {_from:"C", _to:"F"}, {_from:"D", _to:"B"}, {_from:"D", _to:"E"}, {_from:"F", _to:"D"}, {_from:"F", _to:"G"}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:topological_link_prediction
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
ids |
[]_id |
/ | / | 否 | 通过_id指定参与计算的第一组点;若未设置则计算所有点 |
uuids |
[]_uuid |
/ | / | 否 | 通过_uuid指定参与计算的第一组点;若未设置则计算所有点 |
ids2 |
[]_id |
/ | / | 否 | 通过_id指定参与计算的第二组点;若未设置则计算所有点 |
uuids2 |
[]_uuid |
/ | / | 否 | 通过_uuid指定参与计算的第二组点;若未设置则计算所有点 |
type |
String | Total_Neighbors |
Adamic_Adar |
否 | 指定待计算的相似度类型;计算总邻居时,设置为Total_Neighbors |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
CALL algo.topological_link_prediction.write("my_hdc_graph", {
ids: ["C"],
ids2: ["A","E","G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}, {
file: {
filename: "tn"
}
})
algo(topological_link_prediction).params({
projection: "my_hdc_graph",
ids: ["C"],
ids2: ["A","E","G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}).write({
file: {
filename: "tn"
}
})
结果:
_id1,_id2,result
C,A,3
C,E,3
C,G,3
完整返回
CALL algo.topological_link_prediction.run("my_hdc_graph", {
ids: ["C"],
ids2: ["A","C","E","G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}) YIELD tn
RETURN tn
exec{
algo(topological_link_prediction).params({
ids: ["C"],
ids2: ["A","C","E","G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}) as tn
return tn
} on my_hdc_graph
结果:
| _id1 | _id2 | result |
|---|---|---|
| C | A | 3 |
| C | E | 3 |
| C | G | 3 |
流式返回
CALL algo.topological_link_prediction.stream("my_hdc_graph", {
ids: ["C"],
ids2: ["A", "B", "D", "E", "F", "G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}) YIELD tn
FILTER tn.result >= 4
RETURN tn
exec{
algo(topological_link_prediction).params({
ids: ["C"],
ids2: ["A", "B", "D", "E", "F", "G"],
type: "Total_Neighbors",
return_id_uuid: "id"
}).stream() as tn
where tn.result >= 4
return tn
} on my_hdc_graph
结果:
| _id1 | _id2 | result |
|---|---|---|
| C | B | 6 |
| C | D | 5 |
| C | F | 5 |