概述
使用语句CALL可以调用子查询,每次通过传入的别名获取一条记录,执行子查询。CALL子查询优化了资源管理,从而降低内存开销,提高查询效率,在处理大型数据集时效果尤为明显。

语法
call {
with <alias_in_1>, <alias_in_2?>, ...
...
return <item1> as <alias_out_1?>, <item2?> as <alias_out_2?>, ...
}
详情
CALL中的子查询以WITH开头,传入别名;以RETURN结尾,将结果传出,供后续查询使用。- 如果省略了开头的
WITH语句,则自动传入所有前置查询中可用的别名,并通过笛卡尔积对任何异源别名进行组合。
示例图集
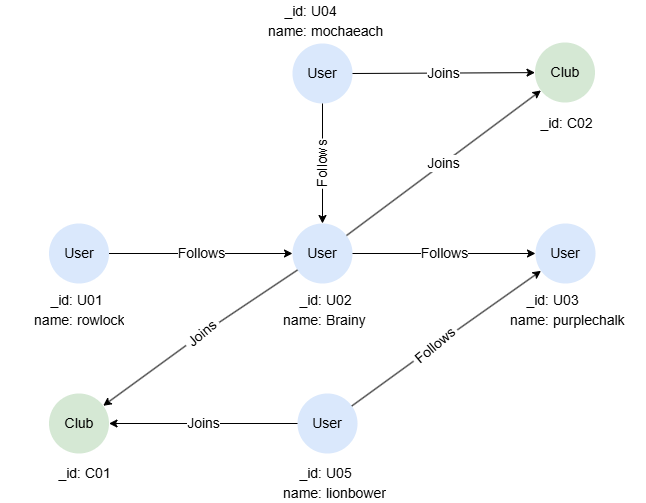
在一个空图集中,逐行运行以下语句,创建示例图集:
create().node_schema("User").node_schema("Club").edge_schema("Follows").edge_schema("Joins")
create().node_property(@User, "name").edge_property(@Joins, "rates", float)
insert().into(@User).nodes([{_id:"U01", name:"rowlock"},{_id:"U02", name:"Brainy"},{_id:"U03", name:"purplechalk"},{_id:"U04", name:"mochaeach"},{_id:"U05", name:"lionbower"}])
insert().into(@Club).nodes([{_id:"C01"},{_id:"C02"}])
insert().into(@Follows).edges([{_from:"U01", _to:"U02"},{_from:"U02", _to:"U03"},{_from:"U04", _to:"U02"},{_from:"U05", _to:"U03"}])
insert().into(@Joins).edges([{_from:"U02", _to:"C01"},{_from:"U05", _to:"C01"},{_from:"U02", _to:"C02"},{_from:"U04", _to:"C02"}])
查询
查询每个用户加入的俱乐部:
find().nodes({@User}) as u
call {
with u
n(u).e({@Joins}).n({@Club} as c)
return c{*}
}
return u.name, c._id
结果:
| u.name | c._id |
|---|---|
| mochaeach | C02 |
| Brainy | C01 |
| Brainy | C02 |
| lionbower | C01 |
聚合
计算每个俱乐部成员的粉丝数:
n({@User} as u).e({@Joins}).n({@Club} as c)
call {
with u
n(u).le({@Follows}).n(as follower)
return count(follower) as followersNo
}
return u.name, c._id, followersNo
结果:
| u.name | c._id | followersNo |
|---|---|---|
| mochaeach | C02 | 0 |
| Brainy | C01 | 2 |
| Brainy | C02 | 2 |
| lionbower | C01 | 0 |
数据修改
为边@Joins的属性rates设定属性值:
uncollect [1,2,3,4] as score
call {
with score
find().edges({@Joins.rates is null}) as e1 limit 1
update().edges(e1).set({rates: score}) as e2
return e2{*}
}
return e2{*}
结果: e2
_uuid |
_from |
_to |
_from_uuid |
_to_uuid |
schema |
values |
|---|---|---|---|---|---|---|
| Sys-gen | U04 | C02 | UUID of U04 | UUID of C02 | Joins | {rates: 1} |
| Sys-gen | U02 | C01 | UUID of U02 | UUID of C01 | Joins | {rates: 2} |
| Sys-gen | U02 | C02 | UUID of U02 | UUID of C02 | Joins | {rates: 3} |
| Sys-gen | U05 | C01 | UUID of U05 | UUID of C01 | Joins | {rates: 4} |
传入多个别名
判断边@Follows连接的任意两个用户是否加入同一个俱乐部:
n({@User} as u1).le({@Follows}).n({@User} as u2)
call {
with u1, u2
optional n(u1).e().n({@Club}).e().n({_id == u2._id}) as p
return p
}
return u1.name, u2.name,
case when p is not null then "Y"
else "N" end as sameClub
结果:
| u1.name | u2.name | sameClub |
|---|---|---|
| Brainy | rowlock | N |
| Brainy | mochaeach | Y |
| purplechalk | Brainy | N |
| purplechalk | lionbower | N |
子查询执行顺序
子查询的执行顺序并未预先确定。如需指定执行顺序,须在CALL前使用ORDER BY语句来强制执行该顺序。
本条查询统计每个用户的粉丝数。这里的子查询将根据升序排列的用户名称依次执行:
find().nodes({@User}) as u
order by u.name
call {
with u
n(u).le({@Follows}).n(as follower)
return count(follower) as followersNo
}
return u.name, followersNo
结果:
| u.name | followersNo |
|---|---|
| Brainy | 2 |
| lionbower | 0 |
| mochaeach | 0 |
| purplechalk | 2 |
| rowlock | 0 |