数据与查询执行
一条UQL查询通常包含多个语句,可从数据库中检索或构造数据,然后将数据依次传递处理,最终返回至客户端。在此过程中,可以声明别名来表示特定数据,后续语句可以直接引用这些别名,进一步处理数据。
记录与列
语句间传递的数据可能由多条记录(行)组成,每条记录包含一或多个列。
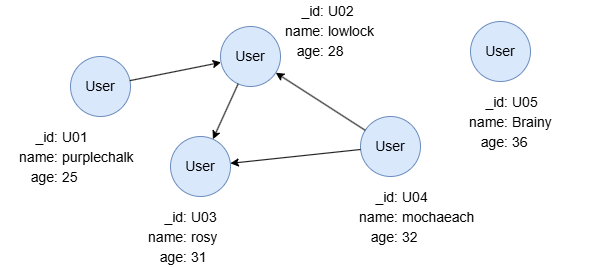
find().nodes({@user}) as n
return n.name as Name
本条查询中,n代表从图中获取的点,共有5条记录。每条记录由列schema、_id、_uuid、name和age组成,储存了点的schema和属性信息。RETURN语句引用了别名n,获取点的name值,将其作为Name输出。Name同样包含5条记录,但每条记录仅有一列。
引用外部别名
当前语句引用的别名如果是在之前的语句中声明的,那么该别名被称为外部别名。
外部别名如何影响语句执行时长?
语句引用外部别名时,其执行次数通常与别名中的记录数一致,分别对每条记录进行处理,并根据具体上下文和场景进行系统优化。
find().nodes({age > 30}) as users
n(users).e().n() as paths
return paths{*}
n({age > 30}).e().n() as paths
return paths{*}
以上两条查询结果相同。第一条查询里,路径模板n().e().n()引用了外部别名users,其中包含3条记录;语句针对users中的每条记录执行1次,共执行了3次。而在第二条查询里,n().e().n()不依赖于外部别名,因此仅执行了1次。
为何引用外部别名?
本例中,使用find().nodes()来获取路径模板n().e().n()的起点可以提升查询效率。这是因为find().nodes()专为点过滤设计并优化;引用外部别名后,执行路径模板将不存在额外计算开销。随着图集规模增大、路径查询深度增加,查询效率将得到显著提升。
有时需要查看是否每条记录均有结果产出。这种情况下,可在引用外部别名时使用前缀OPTIONAL。
find().nodes({age > 30}) as users
optional n(users).e().n() as paths
return paths{*}
本条查询中,n().e().n()带有前缀OPTIONAL,如果执行时users中的记录没有数据返回(例如,点U05的记录),路径模板将对应返回null。
同源数据
流入和流出同个语句的数据被视为同源。同源数据的记录数通常相同,且同一行中的各列互相关联。
示例:tail和path是同源数据,因为二者均由路径模板生成;length由path生成,因此也与其同源。
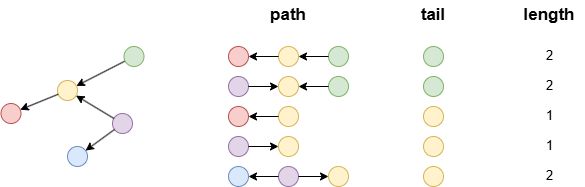
n().e()[:2].n(as tail) as path limit 5
with length(path) as length
return path, tail, length
示例:n、n.s1、n.s2与mean同源。
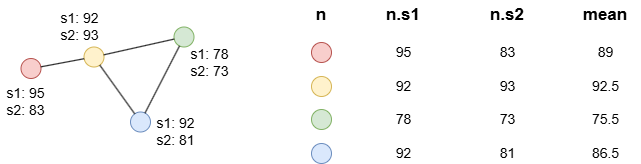
find().nodes() as n
return (n.s1 + n.s2) / 2 as mean
聚合操作如何影响同源数据?
聚合操作将多条数据记录压缩为一条,并丢弃其他记录。聚合数据的同源数据也将受到影响,仅保留一条记录。所有同源数据所保留的一条记录通常没有对应关系。
示例:n和n.s1同源,最初均包含4行数据。当n.s1在RETURN中聚合,n也只有一条记录保留。

find().nodes() as n
return n, min(n.score1)
异源数据
引用了相同别名的语句互相关联。由互不关联的语句生成的数据是被视为异源。异源数据的记录数可能不同。
当语句引用多个异源外部别名时,会对所有异源数据进行笛卡尔积运算,然后再根据语句逐行计算。
示例:n1和n2异源。二者的记录生成笛卡尔积,随后传入路径模板。然后针对每组记录执行路径查询。
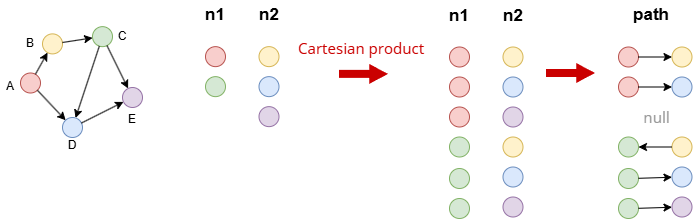
find().nodes({_id in ["A", "C"]}) as n1
find().nodes({_id in ["B", "D", "E"]}) as n2
optional n(n1).e().n({_id == n2._id}) as path
return path