关系型数据库的表连接操作的性能损耗直接源自于关系型数据库的基础设计思想:
- 数据正则化(Data Normalization)
- 固定化的、预先设定的表模式(Fixed/Predefined Schema)
NoSQL对于以上两点的设计则刚好相反。首先,NoSQL在数据建模中突出了数据去正则化,即用空间换取时间;另一方面,NoSQL允许数据模式根据流入的数据进行动态调整,也就是支持 “Schema-Free或Schemaless” 的数据模式,不但能更好地适应那些日新月异的业务需求及其数据结构,还能将DBA从纷繁的表结构中解放出来,从某种程度上也增强了数据库系统的操作安全性。
NoSQL数据库一般而言被分为以下几个大类,每一类都有其各自的特性:
- 键值(Key-Value): 性能和简易性(Performance and simplicity)
- 宽列(Wide-Column):体量(Volume)
- 文档(Document):数据多样性(Variety of data structures)
- 时序(Time Series):IOT数据、时序优先性能(Performance for time-stamped/IOT data)
- 图(Graph): 深数据+快数据(Deep-data and fast-data)
下图形象地表达了NoSQL类数据库的发展过程:
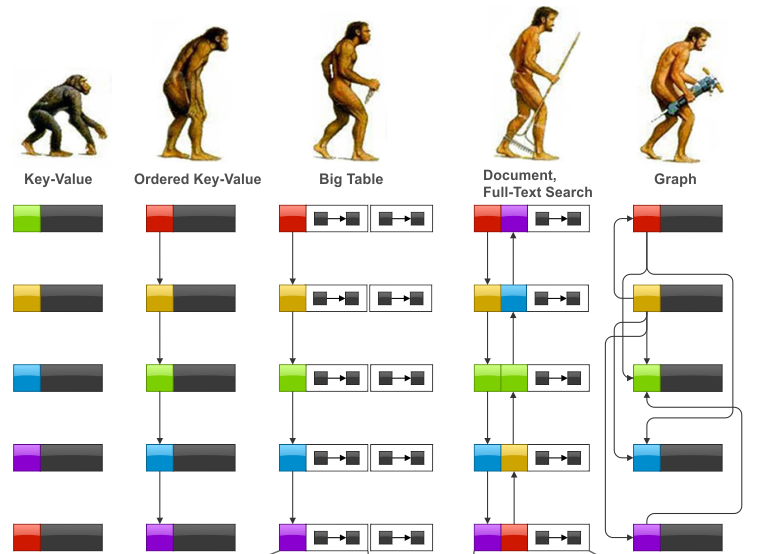
数据库存储结构的进化
在众多NoSQL类数据库中,最好的用来诠释无模式(Schema-Free 或 Demi-Schema)的例子就是图数据库——除了点和边这两种基础数据结构以外,图数据库不需要任何预先定义的模式或表结构。这种极度简化的理念恰恰和人类如何思考以及存储信息有着很大的相似性——人们通常并不在脑海中设定二维的、僵化的表结构,因为人脑是可以随机应变的。
由于图数据库、图计算、图中台是用图论的方式去构造实体间的关联关系,用顶点表达实体,用边表达实体间的关系,这种简洁、自由、高维且100% 还原世界的数据建模方式能让实体间的关联关系的计算轻而易举。
以嬴图数据库为例,关系型数据库所面临的一系列问题从根本上得到了解决:
- 支持高维建模、动态建模
- 用简单代码即可实现深度下钻、递归等“多表关联”类的复杂查询与计算
- 实时完成动态-海量复杂模型的计算与分析
- 进行白盒化的归因分析、溯源、溯因、反向追溯、传导模拟等操作