概述
带量词的路径模式构建了长度可变的路径,其中整个路径或路径中的一部分会重复指定次。将量词应用于边模式或带括号的路径模式即可形成带量词的路径模式。
<quantified path pattern> ::= <quantified edges> | <quantified paths>
<quantified edges> ::= <edge pattern> <quantifier>
<quantified paths> ::= <parenthesized path pattern> <quantifier>
使用时,必须通过点模式将带量词的路径模式与其他路径成分或显式或隐式地连接起来。详情请参阅以下示例。
量词
量词以后缀形式出现在边模式或带括号的路径模式之后。
量词 |
描述 |
|---|---|
{m,n} |
重复m到n次 |
{m} |
重复m次 |
{m,} |
重复至少m次 |
{,n} |
重复0到n次 |
* |
重复至少0次 |
+ |
重复至少1次 |
当重复次数为0时,拥有0条边的路径(或子路径),即只包含初始点的路径,将被纳入匹配结果中。
语法限制可以防止出现无限循环。例如使用无边界量词匹配包含循环的图时,就会出现无限循环。
带量词的边
带量词的边是通过在边模式后接一个量词构建的,其中量词用于指定边重复的次数。量词可应用于完整边模式和简写边模式。

上图的路径模式表达式等同于:

重复边通过空的点模式自动连接。
示例图集
以下示例根据该图集运行:
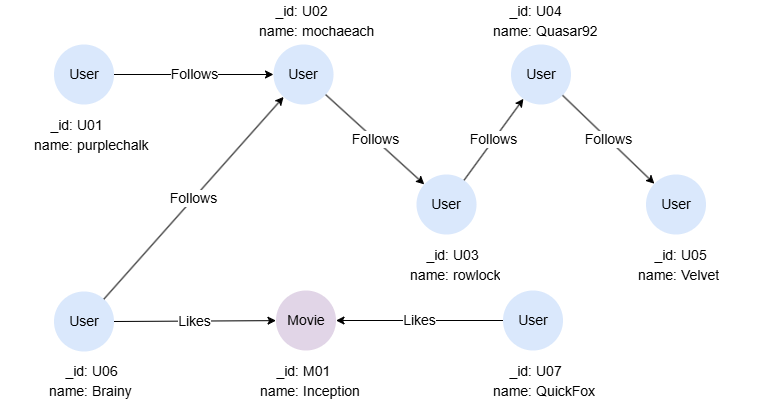
在空图集中运行以下语句创建示例图集:
INSERT (purplechalk:User {_id: "U01", name: "purplechalk"}),
(mochaeach:User {_id: "U02", name: "mochaeach"}),
(rowlock:User {_id: "U03", name: "rowlock"}),
(quasar92:User {_id: "U04", name: "Quasar92"}),
(velvet:User {_id: "U05", name: "Velvet"}),
(brainy:User {_id: "U06", name: "Brainy"}),
(quickfox:User {_id: "U07", name: "Quickfox"}),
(inception:Movie {_id: "M01", name: "Inception"}),
(purplechalk)-[:Follows]->(mochaeach),
(mochaeach)-[:Follows]->(rowlock),
(rowlock)-[:Follows]->(quasar92),
(quasar92)-[:Follows]->(velvet),
(brainy)-[:Follows]->(mochaeach),
(mochaeach)-[:Likes]->(inception),
(quickfox)-[:Likes]->(inception)
固定下界和上界
本例获取Brainy可通过1~3条标签为Follows的出边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]->{1,3}(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["mochaeach", "rowlock", "Quasar92"] |
固定长度
本例获取Brainy可通过2条标签为Follows的出边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]->{2}(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["rowlock"] |
固定下界
本例获取Brainy可通过至少2条标签为Follows的边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]-{2,}(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["rowlock", "purplechalk", "Quasar92", "Velvet"] |
本例获取Brainy可通过至少0条标签为Follows的出边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]->*(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["Brainy", "mochaeach", "rowlock", "Quasar92", "Velvet"] |
本例获取Brainy可通过至少1条标签为Follows的出边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]->+(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["mochaeach", "rowlock", "Quasar92", "Velvet"] |
固定上界
本例获取Brainy可通过0~2条标签为Follows的边到达的User点:
MATCH (:User {name: 'Brainy'})-[:Follows]-{,2}(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["Brainy", "mochaeach", "rowlock", "purplechalk"] |
带量词的简写边
简写边模式中没有对边的标签或属性进行限制。本例获取Brainy可通过1~2条边到达的User点:
MATCH (:User {name: 'Brainy'})-{1,2}(u:User)
RETURN COLLECT_LIST(u.name) AS names
结果:
| names |
|---|
| ["mochaeach", "rowlock", "purplechalk", "QuickFox"] |
带量词的路径
带量词的路径是通过在带括号的路径模式后接一个量词构建的,其中量词用于指定路径重复的次数。

上述路径模式表达式等同于:

相邻路径组由两个点模式连接。这些点模式合并成单个点模式,并对过滤条件取并集。显而易见,在本例中,唯一的过滤条件应用在User标签上:

合并后,上述表达式可简写为:

示例图集
以下示例根据该图集运行:
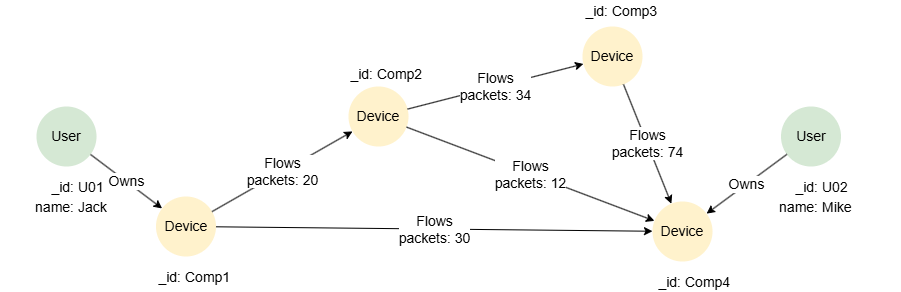
在空图集中运行以下语句创建示例图集:
INSERT (jack:User {_id: "U01", name: "Jack"}),
(mike:User {_id: "U02", name: "Mike"}),
(c1:Device {_id: "Comp1"}),
(c2:Device {_id: "Comp2"}),
(c3:Device {_id: "Comp3"}),
(c4:Device {_id: "Comp4"}),
(jack)-[:Owns]->(c1),
(mike)-[:Owns]->(c4),
(c1)-[:Flows {packets: 20}]->(c2),
(c1)-[:Flows {packets: 30}]->(c4),
(c2)-[:Flows {packets: 34}]->(c3),
(c2)-[:Flows {packets: 12}]->(c4),
(c3)-[:Flows {packets: 74}]->(c4)
固定下界和上界
本例获取的路径从Jack拥有的设备出发,通过1~3条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device)){1,3}
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id:"U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 30}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 20}]->(:Device {_id: "Comp2"})-[:Flows {packets: 34}]->(:Device {_id: "Comp3"})-[:Flows {packets: 74}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
固定长度
本例获取的路径从Jack拥有的设备出发,通过3条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device)){3}
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 20}]->(:Device {_id: "Comp2"})-[:Flows {packets: 34}]->(:Device {_id: "Comp3"})-[:Flows {packets: 74}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
固定下界
本例获取的路径从Jack拥有的设备出发,通过至少2条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device)){2,}
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 20}]->(:Device {_id: "Comp2"})-[:Flows {packets: 34}]->(:Device {_id: "Comp3"})-[:Flows {packets: 74}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
本例获取的路径从Jack拥有的设备出发,通过至少0条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device))*
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 30}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 20}]->(:Device {_id: "Comp2"})-[:Flows {packets: 34}]->(:Device {_id: "Comp3"})-[:Flows {packets: 74}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
本例获取的路径从Jack拥有的设备出发,通过至少1条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device))+
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 30}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 20}]->(:Device {_id: "Comp2"})-[:Flows {packets: 34}]->(:Device {_id: "Comp3"})-[:Flows {packets: 74}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
固定上界
本例获取的路径从Jack拥有的设备出发,通过0~2条出向数据流到达Mike拥有的设备,其中每条数据流包含超过15个数据包:
MATCH p = (:User {name: 'Jack'})-[:Owns]->()
((:Device)-[f:Flows WHERE f.packets > 15]->(:Device)){,2}
()<-[:Owns]-(:User {name: 'Mike'})
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "Jack"})-[:Owns]->(:Device {_id: "Comp1"})-[:Flows {packets: 30}]->(:Device {_id: "Comp4"})<-[:Owns]-(:User {_id: "U02", name: "Mike"}) |
元素变量的引用度
在带量词的路径模式中声明的元素变量,可以同多个图元素绑定。对该元素变量的引用将根据上下文解释。
单一引用度
暂不支持该功能。
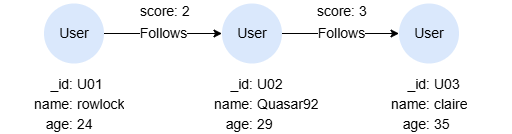
如果引用出现在带量词的路径模式里,则该引用具有单一引用度,且最多引用一个图元素。
MATCH p = ((a)-[]->(b) WHERE a.age < b.age){1,2}
RETURN p
结果:
| p |
|---|
| (:User {_id: "U01", name: "rowlock", age: 24})-[:Follows {score: 2}]->(:User {_id: "U02", name: "Quasar92", age: 29}) |
| (:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) |
| (:User {_id: "U01", name: "rowlock", age: 24})-[:Follows {score: 2}]->(:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) |
本条查询中,a和b是代表单个点的单一变量。匹配路径时,条件a.age < b.age用于评估每一对点a和点b。
组引用度
如果引用出现在带量词的路径模式外,则该引用具有组引用度,且引用完整的图元素列表。在这种情况下,元素变量被视为组变量。
MATCH p = ((a)-[]->(b)){1,2}
RETURN p, a, b
结果:
p |
a | b |
|---|---|---|
| (:User {_id: "U01", name: "rowlock", age: 24})-[:Follows {score: 2}]->(:User {_id: "U02", name: "Quasar92", age: 29}) | [(:User {_id: "U01", name: "rowlock", age: 24})] | [(:User {_id: "U02", name: "Quasar92", age: 29})] |
| (:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) | [(:User {_id: "U02", name: "Quasar92", age: 29})] | [(:User {_id: "U03", name: "claire", age: 35})] |
| (:User {_id: "U01", name: "rowlock", age: 24})-[:Follows {score: 2}]->(:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) | [(:User {_id: "U01", name: "rowlock", age: 24}), (:User {_id: "U02", name: "Quasar92", age: 29})] | [(:User {_id: "U02", name: "Quasar92", age: 29}), (:User {_id: "U03", name: "claire", age: 35})] |
RETURN语句里的变量a和b都被视为组变量,分别代表匹配路径中出现的点列表,而非单个点。
以下查询会引发语法错误,因为它将a和b视为带量词的路径模式外的单变量:
MATCH p = ((a)-[]->(b)){1,2}
WHERE a.age < b.age
RETURN p
暂不支持横向聚合功能。
组变量可用于沿带量词的路径或带量词的边聚合数据,又称横向聚合。
MATCH p = ()-[e]->{1,2}()
WHERE SUM(e.score) > 2
RETURN p, COLLECT_LIST(e.score) AS scores
结果:
p |
scores |
|---|---|
| (:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) | [3] |
| (:User {_id: "U01", name: "rowlock", age: 24})-[:Follows {score: 2}]->(:User {_id: "U02", name: "Quasar92", age: 29})-[:Follows {score: 3}]->(:User {_id: "U03", name: "claire", age: 35}) | [2, 3] |