我们之所以没有在本部分内容的一开就介绍UQL的查询机制,是希望能更早的抛出图查询语言的如何在真实业务场景下的落地,并让用户通过一系列示例对这些概念有一个感性的认知。而查询机制、数据流等概念较为抽象,我们留到现在进行介绍。
编写好的UQL语句输送给嬴图数据库后会进行语法解析、执行计划、执行优化后,分配给高性能图计算与存储引擎进行处理,其结果在执行完所有的处理、组装后,根据业务需求,客户端语言特性,适配并最终返回给用户。
一个UQL语句中除了增、删、改、查等链式语句外,其余的都是以关键词开头的子句。UQL的子句有:GROUP BY、ORDER BY、SKIP、LIMIT、WHERE、RETURN、WITH、UNCOLLECT等。子句可以对前面语句的结果进行运算和处理,从而得到新的结果并传给后面的语句。UQL的查询结果正是以数据流的形式在不同的链式语句、子句之间进行传递。
当数据流进入一个链式语句时,该语句执行的次数等于数据流的长度,该语句相当于被并发循环执行。同时,系统会对各个环节进行并发和计算的加速优化:

如上例所示,进入delete()语句的数据流中有4个顶点,则delete()会删除这4个顶点。
被循环执行多次的语句,其所产生的数据流的总长度等于其每次执行所产生的结果的总和:
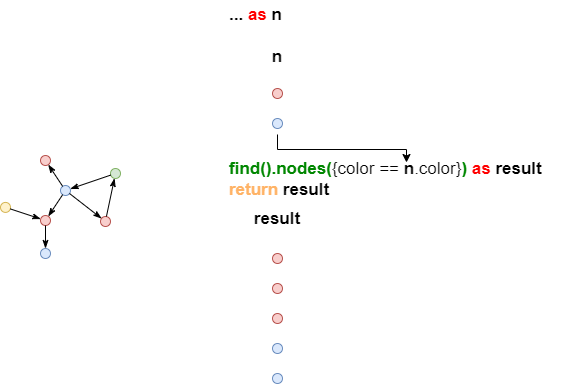
上例中的find()语句总共执行了两次,分别产生了三条数据和两条数据,最终其所产生的数据流的长度为5。