概述
Leiden(莱顿)算法是一种社区检测算法,旨在最大化图的模块度。它是为了解决广泛使用的Louvain算法可能存在的社区连通性不良甚至是不连通的问题而提出的。Leiden算法比Louvain算法效率更高,并且能保证所有社区都是连通的。该算法也是以其作者所在地命名的。
- V.A. Traag, L. Waltman, N.J. van Eck, From Louvain to Leiden: guaranteeing well-connected communities (2019)
- V.A. Traag, P. Van Dooren, Y. Nesterov, Narrow scope for resolution-limit-free community detection (2011)
基本概念
模块度
模块度(Modularity)的概念在 Louvain算法中有所介绍。Leiden算法使用的是扩展的模块度公式,以处理不同密度的社区:
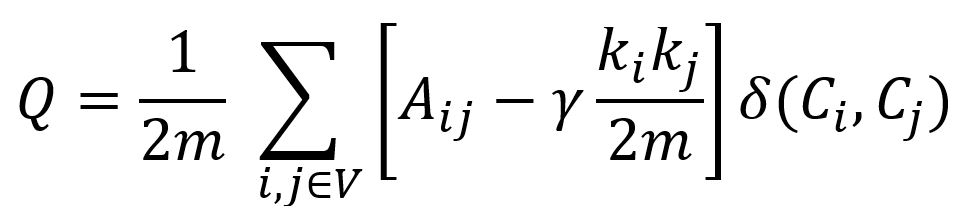
γ > 0是调节社区内部和社区之间连接密度的分辨率参数。当γ > 1时,会形成更多、更小且连接紧密的社区;当γ < 1时,会形成更少、更大但连接相对不那么紧密的社区。
Leiden
Leiden算法开始时,图中的每个节点都在自己的社区中。然后算法进行多次迭代,每轮迭代由三个阶段组成。
第一阶段:快速模块度优化
Louvain算法在第一阶段会一直遍历图中的所有节点,直到没有任何节点移动能增加模块度。Leiden算法则采用一种更高效的方法,它遍历完图中所有的节点一次后,只会访问那些邻居节点发生了变化的节点。为了实现这一点,Leiden算法使用一个队列,初始化时按随机顺序将图中的所有节点添加到队列中。
然后,重复下面的步骤直到队列为空:
- 从队列最前端移除一个节点。
- 将该节点分配至能获得最大模块度增益(ΔQ)的不同社区;如果加入任何社区都不能获得大于0的增益,则保留该节点在原社区。
- 如果该节点被移动到另一个社区,将所有不属于该节点新社区且不在队列中的邻居节点添加到队列尾端。
第一阶段以原图或聚合图的一种社区划分P结束。
第二阶段:社区优化
本阶段旨在获得一个基于P优化的社区划分Prefined,以确保所有的社区有良好的连通性。
初始化Prefined时,原图或聚合图中的每个节点都在自己的社区中,接着按如下方式对P中的每个社区C进行优化。
1. 只考虑在C内部连接良好的节点:
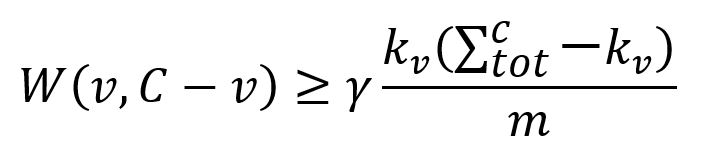
其中,
- W(v,C-v)是节点v与C中其余节点间的边权重之和;
- kv是与节点v相连的所有边的权重之和;
- 是社区C中与所有节点相连的边的权重之和。
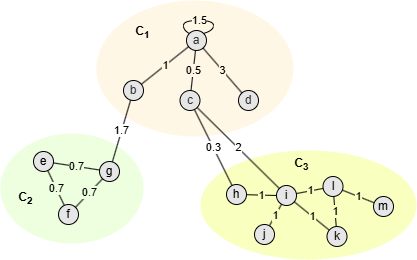
以上图中的社区C1为例,其中
- m = 18.1
- = ka + kb + kc + kd = 6 + 2.7 + 2.8 + 3 = 14.5
设置γ为1.2,则:
- W(a, C1) - γ/m ⋅ ka ⋅ ( - ka) = 4.5 - 1.2/18.1*6*(14.5 - 6) = 1.12
- W(b, C1) - γ/m ⋅ kb ⋅ ( - kb) = 1 - 1.2/18.1*2.7*(14.5 - 2.7) = -1.11
- W(c, C1) - γ/m ⋅ kc ⋅ ( - kc) = 0.5 - 1.2/18.1*2.8*(14.5 - 2.8) = -1.67
- W(d, C1) - γ/m ⋅ kd ⋅ ( - kd) = 3 - 1.2/18.1*3*(14.5 - 3) = 0.71
在这种情况下,社区C1中只有节点a和d被认为是连接良好的。
2. 按随机顺序访问每个节点v,如果它在Prefined中仍处于自己独立的社区,则将其随机合并到一个能使模块度增加的社区C'∈Prefined,同时C'必须也是与C连接良好的:
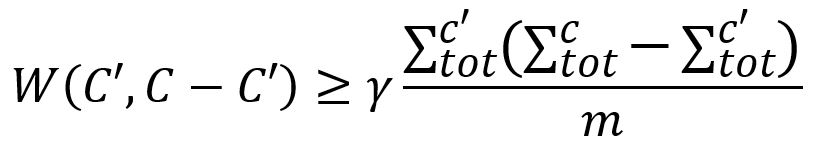
在这个阶段,每个节点并不一定会贪心地与产生最大模块度增益的社区合并。然而,与某个社区合并产生的增益越大,该社区被选择的可能性就越大。选择社区的随机程度由参数θ > 0决定:
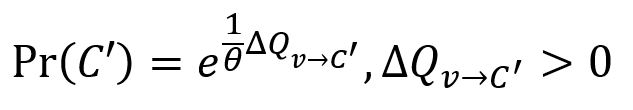
在社区合并过程中引入随机性,可以更广泛地探索分区空间。
在完成优化阶段后,P中的社区通常会被拆分为Prefined中的多个社区,但并不总是如此。
第三阶段:社区聚合
聚合图是基于Prefined创建的,但聚合图中的社区划分是基于P的。聚合过程与Louvain算法相同。
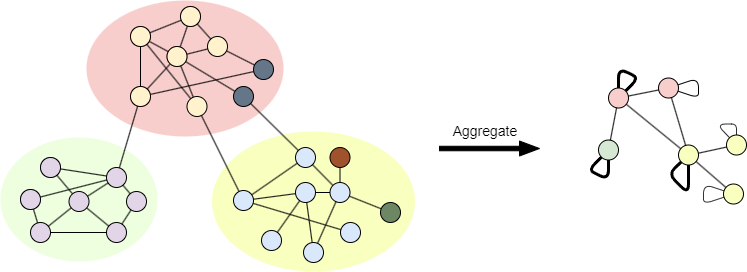
完成第三阶段后,对聚合图进行另一次迭代。迭代会一直进行,直至没有任何变化,达到最大的模块度。
特殊说明
- 如果节点i存在自环边,在计算ki时,自环边的权重只计算一次。
- Leiden算法忽略边的方向,按照无向边进行计算。
语法
- 命令:
algo(leiden) - 参数:
| 名称 | 类型 | 规范 |
默认 |
可选 |
描述 |
|---|---|---|---|---|---|
| phase1_loop_num | int | ≥1 | 5 |
是 | 每轮迭代第一阶段的最大循环次数 |
| min_modularity_increase | float | [0,1] | 0.01 |
是 | 第一阶段将节点重新分配到另一社区时,需产生的最小模块度增益阈值(ΔQ) |
| edge_schema_property | []@<schema>?.<property> |
数值类型,需LTE | / | 是 | 用作边权重的边属性,权重值为所有指定属性值的和;忽略则所有边的权重为1 |
| gamma | float | >0 | 1 | 是 | 分辨率参数γ |
| theta | float | >0 | 0.01 | 是 | 第二阶段的社区合并中,控制随机程度的参数θ |
| limit | int | ≥-1 | -1 |
是 | 返回的结果条数,-1返回所有结果 |
| order | string | asc, desc |
/ | 是 | 按社区中的节点数对结果进行排序(仅在stream()执行方式mode为2时有效) |
示例
文件回写
| 配置项 | 回写内容 | 描述 |
|---|---|---|
| filename_community_id | _id,community_id |
节点及其社区号 |
| filename_ids | community_id,_id,_id,... |
社区号及其中所有节点的ID |
| filename_num | community_id,count |
社区号及其节点数 |
algo(leiden).params({
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}).write({
file:{
filename_community_id: 'communityID',
filename_ids: 'ids',
filename_num: 'num'
}
})
属性回写
| 配置项 | 回写内容 | 类型 | 数据类型 |
|---|---|---|---|
| property | community_id |
点属性 | uint32 |
algo(leiden).params({
phase1_loop_num: 5,
min_modularity_increase: 0.1,
edge_schema_property: 'weight'
}).write({
db:{
property: 'communityID'
}
})
直接返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | []perNode | 点及其社区号 | _uuid, community_id |
| 1 | KV | 社区数量,模块度 | community_count, modularity |
algo(leiden).params({
phase1_loop_num: 6,
min_modularity_increase: 0.5,
edge_schema_property: 'weight'
}) as results, stats
return results, stats
流式返回
| 配置项 | 参数 | 别名序号 | 类型 | 描述 | 列名 |
|---|---|---|---|---|---|
| mode | 1 或忽略 |
0 | []perNode | 点及其社区号 | _uuid, community_id |
2 |
[]perCommunity | 社区及其节点数 | community_id, count |
algo(leiden).params({
phase1_loop_num: 6,
min_modularity_increase: 0.5,
edge_schema_property: 'weight'
}).stream() as results
group by results.community_id
return table(results.community_id, max(results._uuid))
algo(leiden).params({
phase1_loop_num: 5,
min_modularity_increase: 0.1,
order: "desc"
}).stream({
mode: 2
}) as results
return results
统计返回
别名序号 |
类型 |
描述 | 列名 |
|---|---|---|---|
| 0 | KV | 社区数量,模块度 | community_count, modularity |
algo(leiden).params({
phase1_loop_num: 5,
min_modularity_increase: 0.1
}).stats() as stats
return stats