在了解过嬴图数据库的极致性能以后,我们来谈一谈图技术对人工智能的加持。由于人工智能所涉及的知识范围较广、内容难度较大,我们尽可能以通俗易懂的语言、简单地将其阐述清楚。
大数据时代所产生的海量数据一个最重要的用途是帮助商家和企业预测商业前景、进行商业决策。围绕着其中所用到的机器学习以及其他技术手段,三个问题一直萦绕不断:
- AI生态中的多系统间割裂问题(Siloed Systems within AI Eco-system)
- AI 低性能(Low Performance AI)
- AI 黑盒化(Black-Box AI)
另一方面,AI与大数据这两个基础的技术架构也在明显的出现融合趋势(如下图):
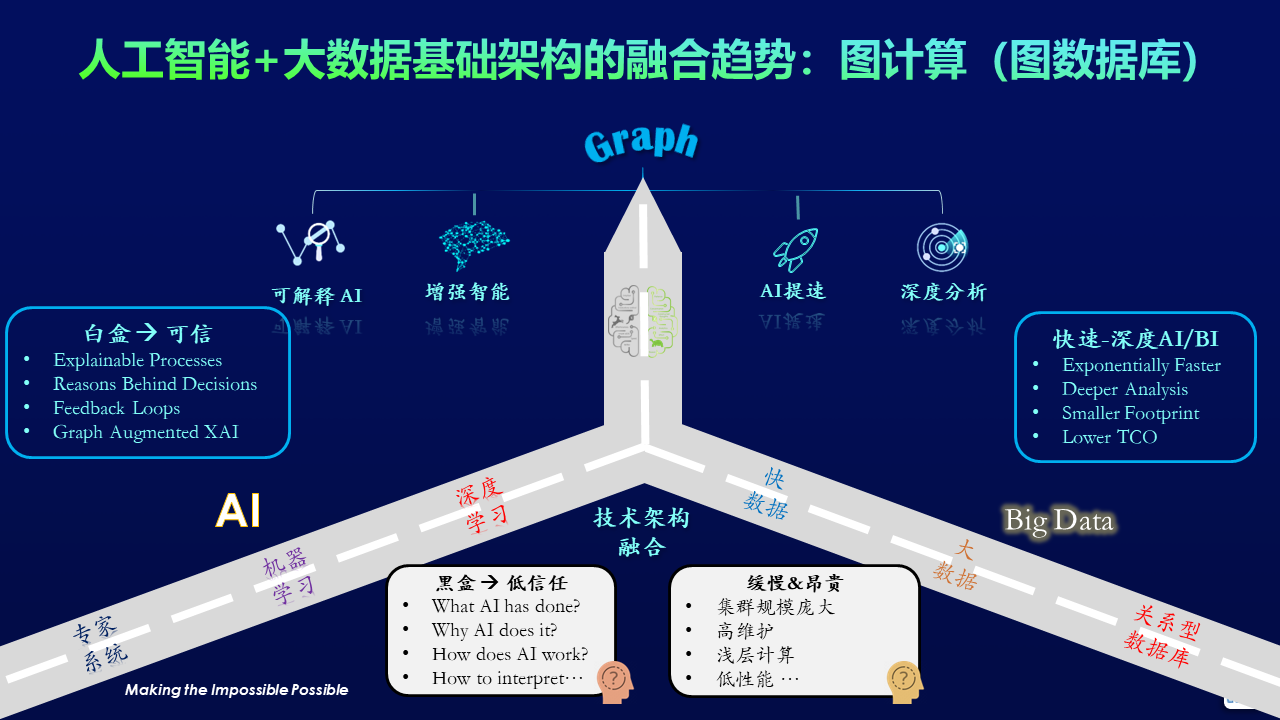
人工智能与大数据基础架构的融合趋势
我们需要基础架构层的创新来一揽子地应对并解决这些挑战,而嬴图数据库当之无愧是这个基础架构层的一个创新。我们以图嵌入为例来说明为嬴图是如何解决以上三个问题的。
之前提到的嬴图在内存存储与计算架构中所使用的“向量计算”,实际上是以原生图的方式把图的元数据(点、边、属性等)映射到向量空间数据结构。这种存储图的做法,正是一个图嵌入(Graph Embedding)的过程,即把一张属性图(Property Graph)转换到向量空间(Vector Space)进行表示,任何在此基础之上的数学、统计学、并发计算等需求都可以更容易的实现。当数据结构、基础架构、算法工程实现层面都做到充分释放和利用底层硬件的并发能力的时候,原先图上的很多非常耗时的图嵌入操作就能以非常高效的方式完成。
举一个Word2Vec的例子,该方法的目的是把自然语言中的每个单词或词组映射为实数域上的一个向量,经常一起出现的单词将被映射为相似的向量,这在几何意义上等同于越是一起出现的单词之间的距离也就越近。从数据建模的角度看,这是个典型的图计算挑战,当一个单词被看作是图中的一个顶点时,它的邻居(和它直接关联的顶点)是那些经常在自然语句中出现在它前后的单词。按照这个逻辑我们就可以构建一张自然语言的完整的图。每个顶点、每条边都可以有它们各自的属性、权重、标签等等。
例如,我们想要根据用户在一个搜索框中输入的一个(或多个)单词来预测这个用户接下来可能想要输入的其它单词,那么这个问题在嬴图面前就被分解为两个清晰(但不简单)的步骤:
- 基于统计分析预处理,为图中每个关联两个单词(顶点)的有向边赋值一个“可能性”权重;
- 通过遍历已输入单词节点的1-Hop邻居来完成单词推荐。
上面第二步操作将以递归的方式在图中前进,每次用户输入一个新的单词(顶点)后,就会实时进行新的推荐;当然也可以通过DFS路径计算的方式实现类似于返回一个完整的长句子的推荐效果。这其实非常类似于一套实时搜索系统&推荐系统,并且它的整个计算逻辑就是一个人脑进行自然语言处理(NLP)的白盒化过程。
以上描述的是一个完整的、白盒化的、图嵌入的处理过程,每一个步骤都是确定、可解释、清晰的,和那种传统AI中的黑盒化、带有隐藏层(多层)的方法截然不同。当随机游走、深度学习、神经元网络等计算过程都变成了图上直观、易懂的K邻查询和BFS/DFS遍历,就是我们所说的由深度实时图计算技术驱动的XAI的发展——可解释的人工智能(XAI, eXplainable AI)。