概述
RETURN子句向用户返回最终结果。RETURN子句可以直接返回别名代表的数据流,也可以对数据流进行函数运算或将多个数据流进行组装后再返回给用户。
语法
RETURN <expression> as <alias>, <expression> as <alias>, ...
<expression>是返回值表达式<alias>是为返回值定义的别名,可省略
RETURN子句通常出现在UQL语句末尾,个别情况时其后还可以接ORDER BY、LIMIT或SKIP子句,语法中的<alias>就是在这些RETURN子句后的子句中使用的。
请留意:
- RETURN子句返回多个别名时,不对异源数据流进行长度裁剪。
- 在RETURN子句中对某个别名使用
dedup()函数去重时,不影响其同源别名的长度。
例如,以下语句中,别名n2和path同源,别名n1与它们异源,RETURN子句中同时包含这三个别名:
- RETURN子句不根据n2和path的长度对n1进行裁剪,因为它们是异源的
- 尽管n2和path同源,但对n2.color的去重操作不影响pnodes(path)的长度
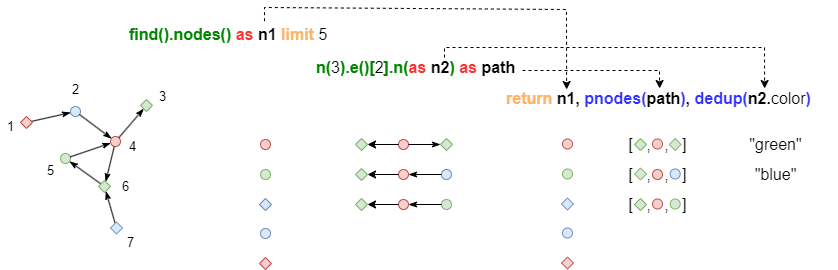
find().nodes() as n1 limit 5
n(3).e()[2].n(as n2) as path
return n1, pnodes(path), dedup(n2.color)
关于RETURN子句中如何指定有效的返回格式,请参见本篇末尾的表格。
示例
示例图集
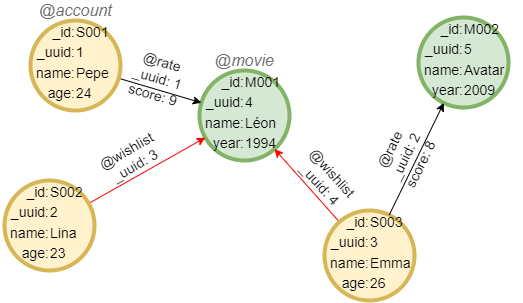
在一个空图集中,依次运行以下各行语句创建示例图集:
create().node_schema("account").node_schema("movie").edge_schema("rate").edge_schema("wishlist")
create().node_property(@*, "name").node_property(@account, "age", int32).node_property(@movie, "year", int32).edge_property(@rate, "score", int32)
insert().into(@account).nodes([{_id:"S001", _uuid:1, name:"Pepe", age:24}, {_id:"S002", _uuid:2, name:"Lina", age:23}, {_id:"S003", _uuid:3, name:"Emma", age:26}])
insert().into(@movie).nodes([{_id:"M001", _uuid:4, name:"Léon", year:1994}, {_id:"M002", _uuid:5, name:"Avatar", year:2009}])
insert().into(@rate).edges([{_uuid:1, _from_uuid:1, _to_uuid:4, score:9}, {_uuid:2, _from_uuid:3, _to_uuid:5, score:8}])
insert().into(@wishlist).edges([{_uuid:3, _from_uuid:2, _to_uuid:4}, {_uuid:4, _from_uuid:3, _to_uuid:4}])
返回NODE
本例返回NODE类型别名并携带其全部信息:
find().nodes({@account}) as n
return n{*}
|-------- @account ---------|
| _id | _uuid | name | age |
|------|-------|------|-----|
| S001 | 1 | Pepe | 24 |
| S002 | 2 | Lina | 23 |
| S003 | 3 | Emma | 26 |
本例返回NODE类型别名并携带两个指定属性:
find().nodes() as n
return n{name, year}
|------ @account -----|
| _id | _uuid | name |
|------|-------|------|
| S001 | 1 | Pepe |
| S002 | 2 | Lina |
| S003 | 3 | Emma |
|----------- @movie -----------|
| _id | _uuid | name | year |
|------|-------|--------|------|
| M001 | 4 | Léon | 1994 |
| M002 | 5 | Avatar | 2009 |
本例返回NODE类型别名并携带系统属性:
find().nodes({@movie}) as n
return n
|--- @movie ---|
| _id | _uuid |
|------|-------|
| M001 | 4 |
| M002 | 5 |
返回EDGE
本例返回EDGE类型别名并携带其全部信息:
find().edges({@rate}) as e
return e{*}
|------------------------ @rate -----------------------|
| _uuid | _from | _to | _from_uuid | _to_uuid | score |
|-------|-------|------|------------|----------|-------|
| 1 | S001 | M001 | 1 | 4 | 9 |
| 2 | S003 | M002 | 3 | 5 | 8 |
本例返回EDGE类型别名并携带其系统属性:
find().edges() as e
return e
|-------------------- @rate -------------------|
| _uuid | _from | _to | _from_uuid | _to_uuid |
|-------|-------|------|------------|----------|
| 1 | S001 | M001 | 1 | 4 |
| 2 | S003 | M002 | 3 | 5 |
|------------------ @wishlist -----------------|
| _uuid | _from | _to | _from_uuid | _to_uuid |
|-------|-------|------|------------|----------|
| 3 | S002 | M001 | 2 | 4 |
| 4 | S003 | M001 | 3 | 4 |
返回PATH
本例返回PATH类型别名并携带一个指定点属性和边的全部信息:
n({@account}).e({@rate}).n({@movie}) as p
return p{name}{*}
[
{
"nodes":[
{"id":"S001","uuid":"1","schema":"account","values":{"name":"Pepe"}},
{"id":"M001","uuid":"4","schema":"movie","values":{"name":"Léon"}}
],
"edges":[
{"uuid":"1","from":"S001","to":"M001","from_uuid":"1","to_uuid":"4","schema":"rate","values":{"score":"9"}}
],
"length":1
},
{
"nodes":[
{"id":"S003","uuid":"3","schema":"account","values":{"name":"Emma"}},
{"id":"M002","uuid":"5","schema":"movie","values":{"name":"Avatar"}}
],
"edges":[
{"uuid":"2","from":"S003","to":"M002","from_uuid":"3","to_uuid":"5","schema":"rate","values":{"score":"8"}}
],
"length":1
}
]
本例返回PATH类型别名并携带一个点和边的系统属性:
n({@movie}).e({@rate}).n({@account}).e({@wishlist}).n({@movie}) as p
return p
[
{
"nodes":[
{"id":"M002","uuid":"5","schema":"movie","values":{}},
{"id":"S003","uuid":"3","schema":"account","values":{}},
{"id":"M001","uuid":"4","schema":"movie","values":{}}
],
"edges":[
{"uuid":"2","from":"S003","to":"M002","from_uuid":"3","to_uuid":"5","schema":"rate","values":{}},
{"uuid":"4","from":"S003","to":"M001","from_uuid":"3","to_uuid":"4","schema":"wishlist","values":{}}
],
"length":2
}
]
返回TABLE
本例查找“账号-[]-电影”1步路径,将起点和终点的name属性组装为表格后返回:
n({@account} as a).e({@wishlist}).n({@movie} as b)
return table(a.name, b.name)
| a.name | b.name |
|--------|--------|
| Lina | Léon |
| Emma | Léon |
返回ATTR(原子)
本例返回独立的指定点属性:
find().nodes() as n
return n.name, n.age, n.year
Pepe
Lina
Emma
Léon
Avatar
24
23
26
null
null
null
null
null
1994
2009
返回ATTR(列表)
本例将每个电影点的1步邻居的name属性组装为列表后返回:
khop().n({@movie} as a).e().n() as b
group by a
return a.name, collect(b.name)
Léon
Avatar
["Pepe","Lina","Emma"]
["Emma"]
有效的返回格式
假设nodes、edges、paths、myTable、myList、myPoint和myItem分别是数据类型为NODE、EDGE、PATH、TABLE、list、point和其他类型(如string, int32, datetime等)的别名。这些别名在RETURN子句中有效的返回格式如下:
| 返回格式 | 返回内容 | 返回数据类型 |
|---|---|---|
nodes |
点(携带schema和系统属性) | NODE |
nodes.<property> |
点的一个指定属性 | ATTR(指定属性不存在时返回null) |
nodes.@ |
点的schema | ATTR |
nodes{<property>, ...} |
点(携带schema、系统属性和指定的属性) | NODE |
nodes{*} |
点(携带schema和全部属性) | NODE |
edges |
边(携带schema和系统属性) | EDGE |
edges.<property> |
边的一个指定属性 | ATTR(指定属性不存在时返回null) |
edges.@ |
边的schema | ATTR |
edges{<property>,...} |
边(携带schema、系统属性和指定的属性) | EDGE |
edges{*} |
边(携带schema和全部属性) | EDGE |
paths |
路径(携带点、边的schema和系统属性) | PATH |
paths{<property>, ...}{<property>, ...} |
路径(携带点、边的schema、系统属性和指定的属性) | PATH |
paths{*}{<property>, ...} |
路径(携带点的schema和全部属性,携带边的schema、系统属性和指定的属性) | PATH |
paths{<property>, ...}{*} |
路径(携带点的schema、系统属性和指定的属性,携带边的schema和全部属性) | PATH |
paths{<property>, ...} |
路径(携带点和边的schema、系统属性和指定的属性) | PATH |
paths{*} |
路径(携带点和边的schema和全部属性) | PATH |
myTable |
整个表格 | TABLE |
myList |
整个列表 | ATTR |
myList[n] |
列表中下标为n的元素 | ATTR |
myList[n1:n2] |
由列表中下标为n1~n2的元素构成的列表 | ATTR |
myList[:n] |
由列表中下标为0~n的元素构成的列表 | ATTR |
myList[n:] |
由列表中下标为n到最大下标的元素构成的列表 | ATTR |
myPoint |
整个坐标 | ATTR |
myPoint.x |
坐标x的值 | ATTR |
myPoint.y |
坐标y的值 | ATTR |
myItem |
数据本身 | ATTR |