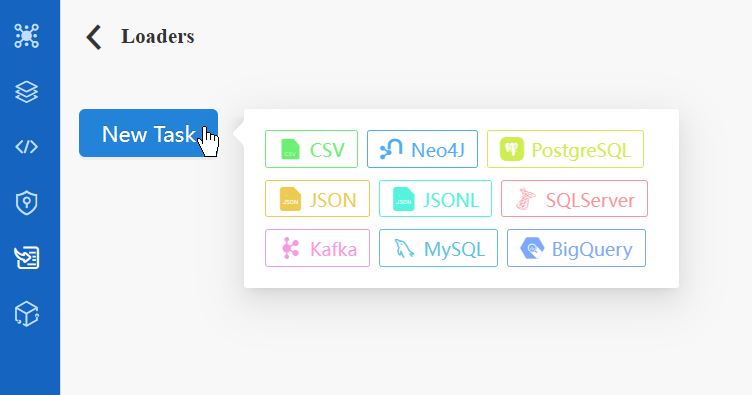
在入图功能模块中,你可以将不同来源的数据导入至嬴图数据库,支持的数据源包括CSV、JSON、JSONL、PostgreSQL、SQL Server、MySQL、BigQuery、Neo4j以及Kafaka。
Loader和Task
每个Loader(载入程序)包含一个或多个导入Task(任务)。一个Loader里的Task可以单独执行,也可以同时执行(串行或并行)。
创建Loader
在入图主页点击New Loader按钮创建新Loader,默认名称为My Loader。
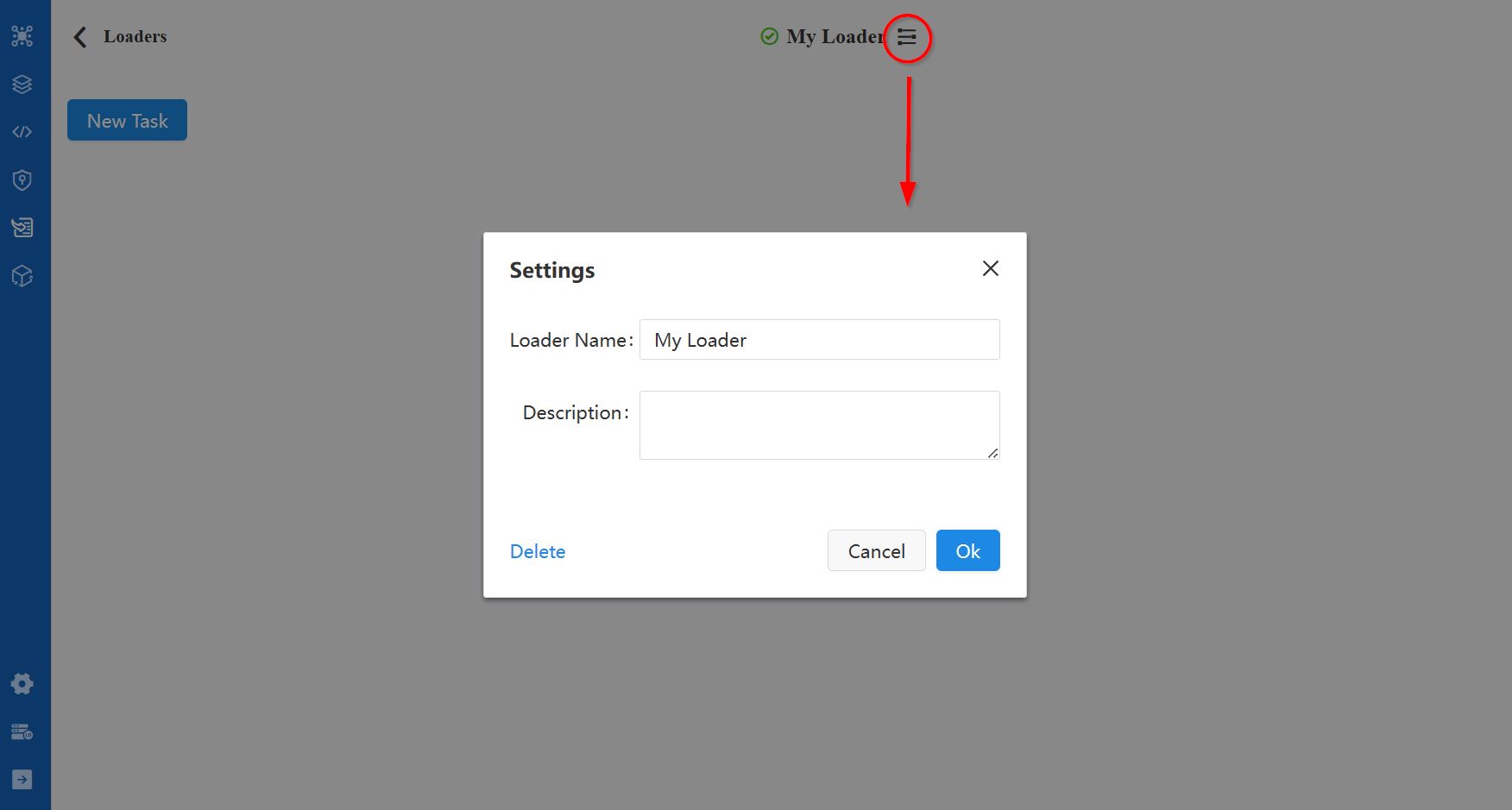
点击Loader进入配置页后,可修改Loader的名称和描述。
创建Task
在Loader配置页中点击New Task按钮可以创建新Task,创建每个Task时需选择数据源。每个Loader中可添加多个Task。
添加Task后,你可以在左侧的Task卡片上修改每个Task的名称。点击每个Task后,在右侧配置这个Task的详细信息,具体请参考附录:Task配置。
导入
导入单个Task
点击每个Task配置页的Import按钮可单独执行该Task的导入任务。
运行Loader
点击左侧Task列表顶部的Run按钮可批量执行该Loader中所有Task的导入任务。
关于所有Task的执行顺序:
- 自上而下执行Task,支持拖拽修改Task卡片顺序。
- 点击Task卡片右上角的
S(串行)或P(并行)标签,指定该Task是单独执行(S)还是和别的Task一起执行(P)。 - 相邻的
PTask,连同这一组Task之前的STask会并行执行。
同时导入点和边时可能会出现错误,因为边的创建要求其两个端点必须在图集中已存在。因此,考虑在导入边之前导入点,或者正确地配置好Create Node If Not Exist项目以及Insert/Upsert/Overwrite这几种插入方式。
导入日志
执行导入时,用户可以在Task卡片中看到进度条。导入结束后,嬴图Manager会提供相应的导入日志,说明导入是否全部成功。用户可在每个Task中下载相应的导入日志和未成功导入的数据。
导入/导出Loader
用户可以将Loader导出为ZIP文件,并在需要时重新导入至嬴图Manager。
附录:Task配置
Settings
每种数据源的Task配置有所不同,但Settings这部分的设置都是一样的。
项目 |
描述 |
|---|---|
| Graph | 选择一个已存在的图集,或输入一个新图集的名称 |
| Schema | 首先选择Node或Edge,然后选择一个Schema或输入一个新Schema的名称 |
| Mode | 选择Insert(插入)、Upsert(插入更新)或Overwrite(插入覆盖)作为数据插入的方式 |
| Batch Size | 每批导入的数据量 |
| Threads | 导入的最大线程数 |
| Skip | 导入时舍弃开头的若干行数据 |
| Timezone | 将timestamp属性值转换成普通日期和时间的时区;默认为浏览器的时区 |
| Stop When Error Occurs | 导入出错时,终止导入操作或跳过错误继续导入 |
| Create Node If Not Exist | 导入边时,如果在图集中找不到边的起点或终点,自动创建相应的点;没有勾选此项时,遇到这种情况则视为导入错误;此项仅导入边时可见 |
任何新的图集、Schema或属性旁会出现一个警告图标,它们会在导入过程中被自动创建。
CSV
File
项目 |
描述 |
|---|---|
| File | 上传一个CSV文件,或选择已上传的文件;已上传的文件可从下拉列表中删除 |
| Separator | CSV文件的列分隔符,选择,、;或| |
| Headless | 文件首行是数据还是表头(指明每列的属性名和数据类型) |
以下示例CSV文件用于导入@账户点,它的表头写明了属性名和数据类型:
_id:_id,username:string,brithYear:int32
U001,risotto4cato,1978
U002,jibber-jabber,1989
U003,LondonEYE,1982
以下示例CSV文件用于导入@关注边,它没有表头:
103,risotto4cato,jibber-jabber,1634962465
102,LondonEYE,jibber-jabber,1634962587
Mapping
上传或选择文件后,此部分才可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;自动填充CSV表头(如有)指定的属性名 |
| Type | 选择属性的数据类型;自动填充CSV文件表头(如有)指定的属性数据类型,或从数据内容识别出的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Row Preview | 预览前4行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
JSON, JSONL
File
项目 |
描述 |
|---|---|
| File | 上传一个JSON/JSONL文件,或选择已上传的文件;已上传的文件可从下拉列表中删除 |
以下示例JSON文件用于导入@用户点:
[{
"_uuid": 1,
"_id": "U001",
"level": 2,
"registeredOn": "2018-12-1 10:20:23",
"tag": null
}, {
"_uuid": 2,
"_id": "U002",
"level": 3,
"registeredOn": "2018-12-1 12:45:12",
"tag": "cloud"
}]
以下示例JSONL文件用于导入@用户点:
{"_uuid": 1, "_id": "U001", "level": 2, "registeredOn": "2018-12-1 10:20:23", "tag": null}
{"_uuid": 2, "_id": "U002", "level": 3, "registeredOn": "2018-12-1 12:45:12", "tag": "cloud"
}
Mapping
上传或选择文件后,此部分才可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;自动填充文件中的键名 |
| Type | 选择属性的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Original | 自动填充文件中的键名 |
| Row Preview | 预览前3行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
PostgreSQL, SQL Server, MySQL
Source Database
项目 |
描述 |
|---|---|
| Host | 数据库服务器的IP地址 |
| Port | 数据库服务器的端口号 |
| Database | 要导入的数据库名称 |
| User | 数据库服务器的用户名 |
| Password | 用户名对应的密码 |
| Test | 检查是否能成功连接数据库服务器 |
SQL
书写SQL查询语句从数据库获取数据,然后点击Preview将结果映射为点或边的属性。
以下示例SQL返回users表里的name和registeredOn这两列数据:
SELECT name, registeredOn FROM users;
Mapping
SQL返回结果后,此部分可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;自动填充结果中的列名 |
| Type | 选择属性的数据类型;自动填充结果中每列的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Original | 自动填充结果中的列名 |
| Row Preview | 预览前3行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
BigQuery
Source Database
项目 |
描述 |
|---|---|
| Project ID | Google Cloud Platform上的项目ID |
| Key (JSON) | 服务账户密钥,是一个JSON文件;上传一个JSON文件,或选择已上传的文件;已上传的文件可从下拉列表中删除 |
| Test | 检查是否能成功连接数据库服务器 |
SQL
书写SQL查询语句从BigQuery获取数据,然后点击Preview将结果映射为点或边的属性。
以下示例SQL返回users表里的全部列数据:
SELECT * FROM users;
Mapping
SQL返回结果后,此部分可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;自动填充结果中的列名 |
| Type | 选择属性的数据类型;自动填充结果中每列的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Original | 自动填充结果中的列名 |
| Row Preview | 预览前3行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
Neo4j
Neo4j
项目 |
描述 |
|---|---|
| Host | 数据库服务器的IP地址 |
| Port | 数据库服务器的端口号 |
| Database | 要导入的数据库名称 |
| User | 数据库服务器的用户名 |
| Password | 用户名对应的密码 |
| Test | 检查是否能成功连接数据库服务器 |
Cypher
书写Cypher查询语句从Neo4j获取数据,然后点击Preview将结果映射为点或边的属性。
以下示例Cypher返回所有标签为user的点:
MATCH (n:user)
Mapping
Cypher返回结果后,此部分可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;自动填充结果中的属性名 |
| Type | 选择属性的数据类型;自动填充结果中属性的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Original | 自动填充结果中的属性名 |
| Row Preview | 预览前3行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
Kafka
Kafka
Item |
Description |
|---|---|
| Host | Kafka代理运行的服务器IP地址 |
| Port | Kafka代理监听传入连接的端口 |
| Topic | 消息(数据)发布的Topic |
| Offset | 选择偏移量以指定要消费(导入)的消息: - Newest:接收消费者(Task)启动后发布的新消息- Oldest:接收Topic中当前存储的所有消息以及消费者启动后发布的新消息- Since:接收指定日期后发布的消息以及消费者启动后发布的新消息- Index:接收索引大于等于指定索引的消息以及消费者启动后发布的新消息 |
| Test | 检查是否能成功建立连接 |
| Preview | 将接收到的消息映射为点或边的属性 |
Mapping
接收到消息结果后,此部分可见:
项目 |
描述 |
|---|---|
| Property | 编辑属性名;以消息内容中的英文逗号(,)划分属性,默认属性名为col<N> |
| Type | 选择属性的数据类型;如果属性名在指定的schema下已存在,数据类型无法修改 |
| Row Preview | 预览前4行数据 |
| Include Check | 取消勾选的在导入时跳过该属性 |
Kafka的Task(消费者)开始后会一直保持运行来接收新发布的消息,需要时请手动停止。