概述
将GQL查询提交至嬴图系统后,首先需过解析验证其语法。解析完成后,查询将进入优化阶段,嬴图会根据数据库的当前状态评估可能的执行策略。
嬴图的查询优化器将基于数据分布、索引和潜在瓶颈等情况,选择最有效的执行计划。该执行计划将展示操作的最佳顺序,最大限度减少资源消耗并提升查询性能。
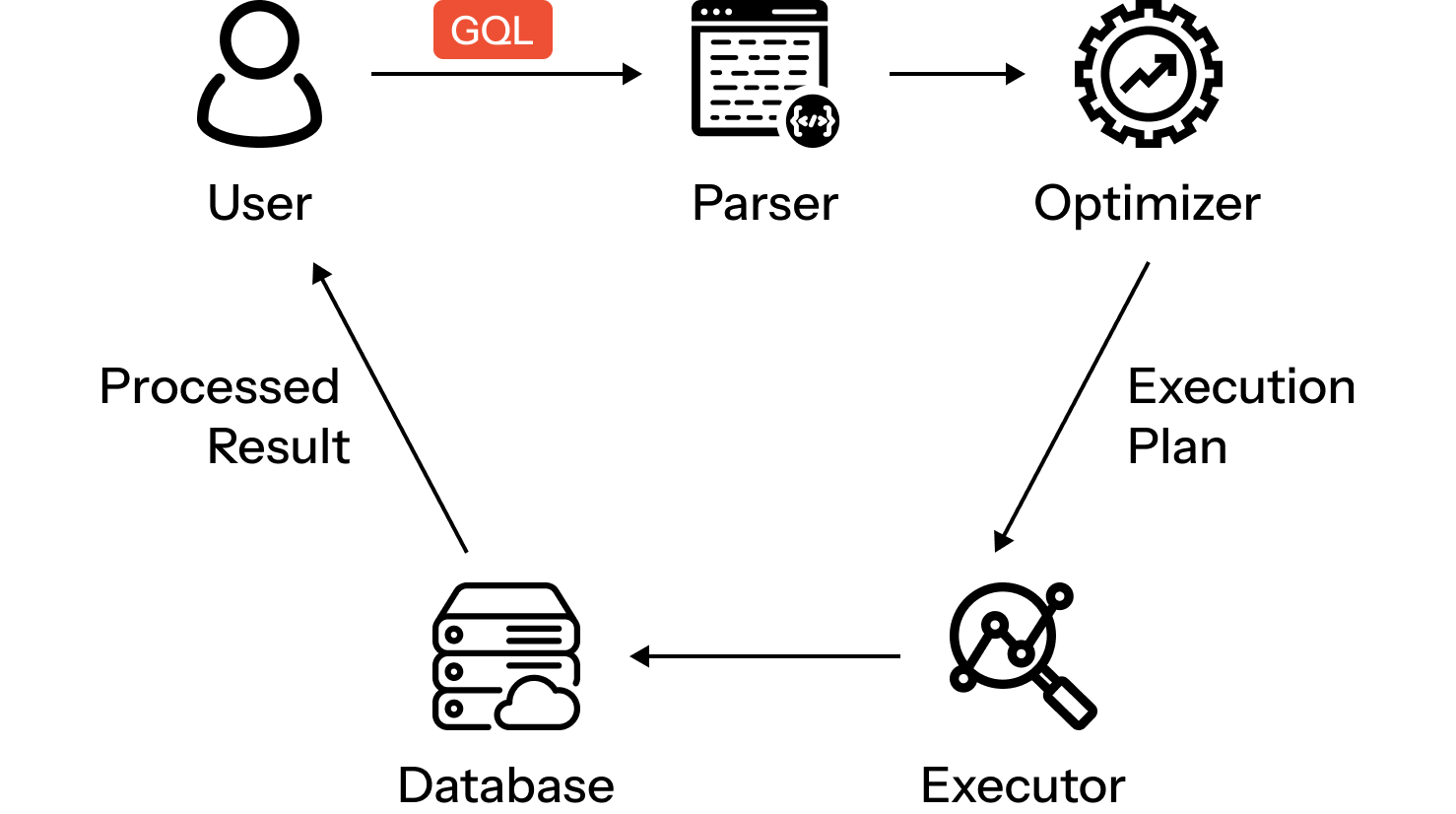
GQL查询生命周期
解释执行计划
使用前缀EXPLAIN可在不执行GQL查询的情况下查看执行计划。该操作生成一个详细的操作树,概述查询进程中所需的每个步骤。
EXPLAIN
MATCH (m:movie)-[]-(:country {name: "US"})
RETURN m.genre AS genre, count(m) GROUP BY genre
Return{expr:[genre,count(m)] row_type:genre:ANY,count(m):ANY}
-> With{exprs:[genre,$value_7 as count(m)],row_type:genre:STRING,count(m):UINT64}
-> Aggregate{key:[genre],agg:[sum(#agg_27_0) as $value_7],phase:GLOBAL_MERGE}
-> Exchange(PartitionByNode){distribution:distribution_type:ANY,gap_type:SOURCE}
-> Aggregate{key:[genre],agg:[count(m) as #agg_27_0],phase:PARTIAL}
-> With{exprs:[m,m.genre as genre],row_type:m:NODE{},genre:ANY}
-> With{exprs:[m_4 as m],row_type:m:NODE{}}
-> Filter{predicate:(&&,(&&,(PROPERTY_EXISTS,anno_6,name),(eq,anno_6.name,US)),(is_schema,anno_6,country,4,NODE)),row_type:m_4:NODE{},anno_5:EDGE{},anno_6:NODE{}}
-> Extend(INTO)(start){(m_4)-[anno_5]-(anno_6)}::m_4:NODE{},anno_5:EDGE{},anno_6:NODE{} on $2[m_4]
-> ExchangeApply{CORRELATE,row_type:m_4:NODE{},anno_5:EDGE{},anno_6:NODE{},cors:m_4:ANY,cor_id:2}
-> NodeSearch{alias:m_4,row_type:m_4:NODE{},access_method:{condition:@movie,index_name:schema,query_type:SK_SCHEMA_SCAN}}
-> Exchange(PartitionByNode){cors:2,distribution:distribution_type:ANY,gap_type:SOURCE,cor_ids:[2] }
-> NodeSearch{alias:anno_6,predicate:(&&,(PROPERTY_EXISTS,anno_6,name),(eq,anno_6.name,US)),row_type:anno_6:NODE{},access_method:{condition:@country,index_name:schema,query_type:SK_SCHEMA_SCAN}}
EXPLAIN功能展示了操作的结构和顺序,有助于分析查询的性能影响。有了这种预览,您可在执行完整查询前进行调整,以实现更高效率,这对优化查询非常重要。