本文介绍如何将CSV文件导入嬴图数据库。
以下步骤均在Windows系统上PowerShell中演示。
使用指南
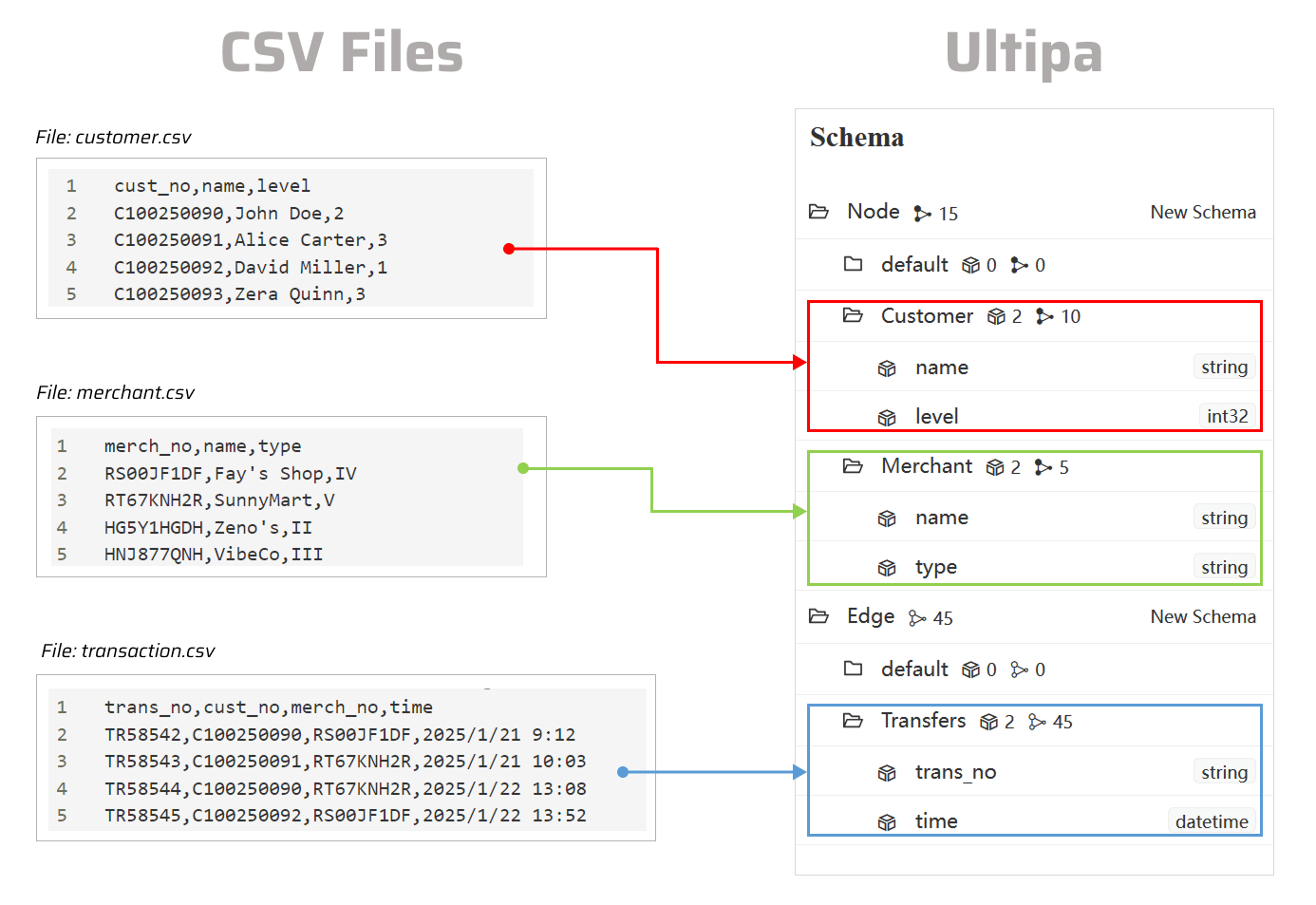
准备CSV文件
点击下载CSV示例文件:
您可将所有文件保存在ultipa-importer所在目录下。
生成配置文件
打开终端程序,导航至ultipa-importer所在文件夹。执行以下命令,选择csv,为导入CSV文件生成样本配置文件:
./ultipa-importer --sample

执行命令后,会在ultipa-importer所在目录下生成配置文件import.sample.csv.yml。如果目录下已有该文件,数据将被覆盖。
修改配置文件
根据实际使用场景修改import.sample.csv.yml文件。该文件包含以下部分:
mode:设置为csv。server:提供嬴图服务器信息,并为数据导入指定目标图(新图或已有图)。sftp:配置存储CSV文件的SFTP服务器。若将文件存储在本地计算机上,请删除此部分或留空。nodeConfig:定义点schema,其中每个schema对应一个CSV文件。文件中的各列将映射为点属性。edgeConfig:定义边schema,其中每个schema对应一个CSV文件。文件中的各列将映射为边属性。settings:为数据导入设置全局参数和偏好。
# 导入模式:csv/json/jsonl/rdf/graphml/bigQuery/sql/kafka/neo4j/salesforce
mode: csv
# 嬴图服务器配置
server:
# 主机IP/URI和端口;若为集群,使用英文逗号分隔
host: "10.11.22.33:1234"
username: "admin"
password: "admin12345"
# 目标图(新图或已有图)
graphset: "myGraph"
# 若上图为新图,指定图所在分片
shards: "1,2,3"
# 若上图为新图,指定分片分区算法(Crc32/Crc64WE/Crc64XZ/CityHash64)
partitionBy: "Crc32"
# TLS加密证书文件路径
crt: ""
# SFTP服务器配置
# 若文件保存在本地计算机,请删除此部分或留空
sftp:
# 主机IP/URI和端口
host:
username:
password:
# SFTP的SSH密钥路径(若设置了密钥路径,将不再使用密码)
key:
# 点配置
nodeConfig:
# 指定schema
- schema: "Customer"
# 本地计算机或SFTP上的文件路径
file: "./customer.csv"
# 文件是否包含标题行
head: true
# properties:将文件中的各列映射为属性;若未设置,将自动映射所有列
## name:文件中的列名;若文件没有标题行,则使用此名称作为属性名
## new_name:属性名;默认为上述名称
## type:属性类型;可设置为_id,_from,_to或其他嬴图属性,如int64,float,string等:设置为_ignore时可跳过导入该列
## prefix:为属性值增加前缀;仅适用于_id,_from和_to类型
properties:
- name: cust_no
new_name: _id
type: _id
prefix:
- name: name
type: string
- name: level
type: int32
- schema: "Merchant"
file: "./merchant.csv"
head: true
properties:
- name: merch_no
type: _id
- name: name
type: string
- name: type
type: string
# 边配置
edgeConfig:
- schema: "Transfers"
file: "./transaction.csv"
head: true
# _from和_to为边的必需类型
properties:
- name: trans_no
type: string
- name: cust_no
type: _from
- name: merch_no
type: _to
- name: time
type: datetime
# 全局设置
settings:
# CSV文件的分隔符
separator: ","
# 日志文件路径
logPath: "./logs"
# 每批次导入的点或边的数量
batchSize: 10000
# 插入模式:insert/overwrite/upsert
importMode: insert
# 插入边时,自动创建缺失端点
createNodeIfNotExist: false
# 报错时停止数据导入
stopWhenError: false
# 导入无标题CSV文件时,若配置的属性数量与文件中的列数不同,设置为false以抛出错误并终止数据导入
fitToHeader: true
# 设置为true时,自动创建新的图、schema和属性
yes: true
# 最大线程数
threads: 32
# RPC最大消息传输量(单位:MB)
maxPacketSize: 40
# 定义CSV文件中双引号的处理方式;设置为false(默认)时,将其视为字段分隔符,设置为true时,将其视为值的一部分
quotes: true
# 时间戳对应时区
# 默认时区:"+0200"
# 时间戳单位,支持毫秒(ms)或秒(s)
timestampUnit: s
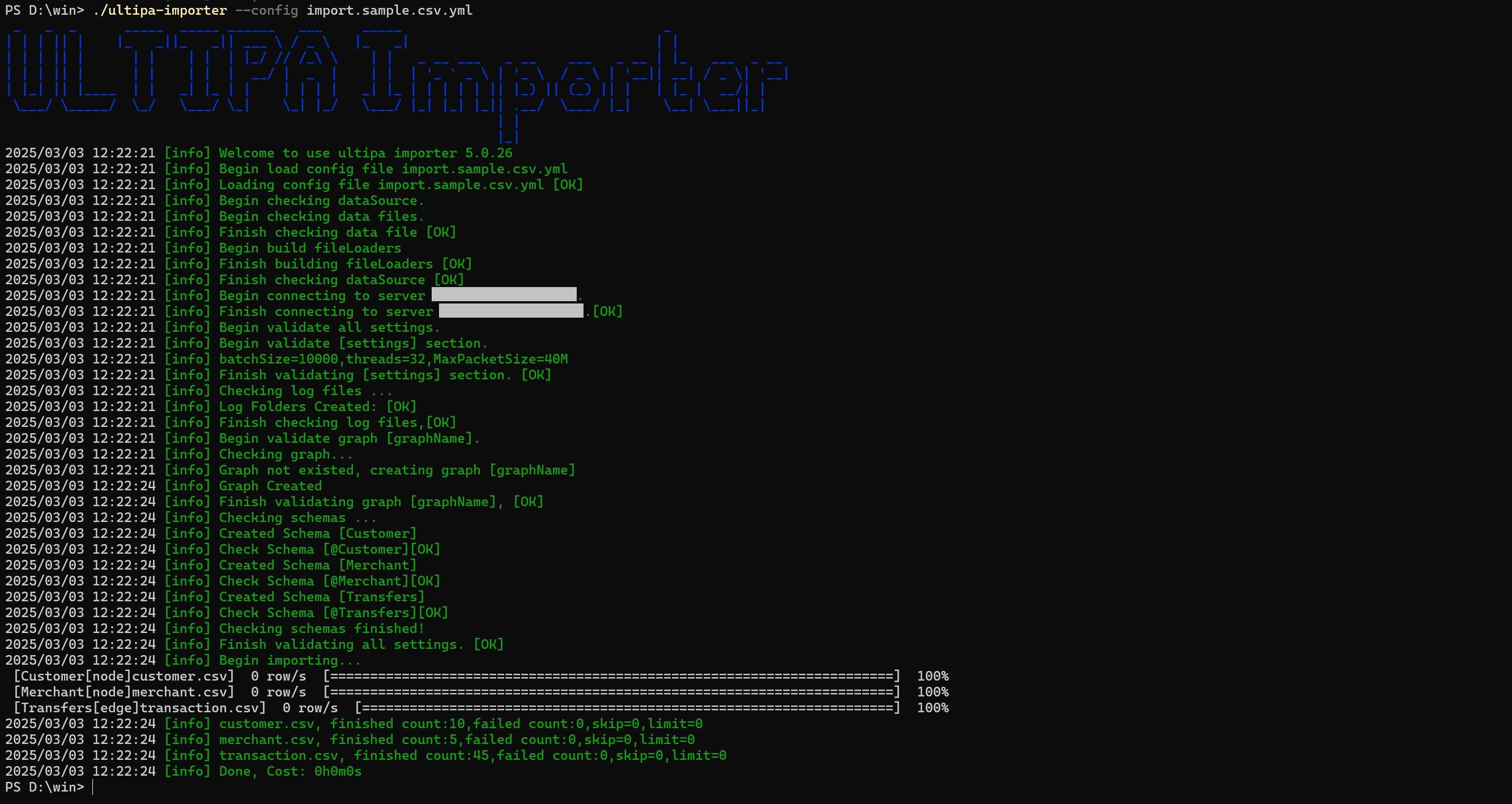
执行导入
使用--config标志指定配置文件,执行数据导入:
./ultipa-importer --config import.sample.csv.yml
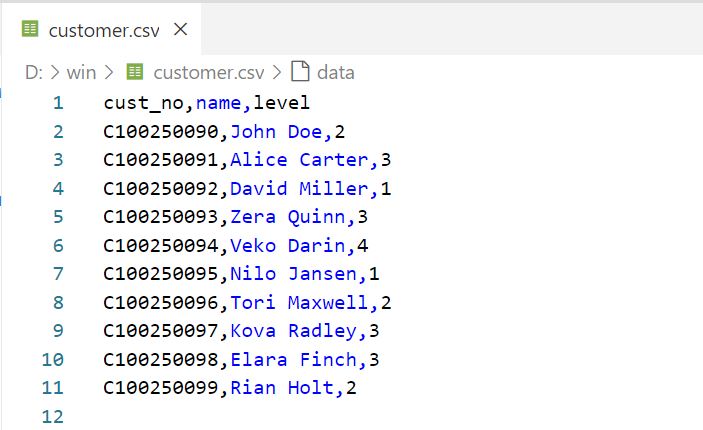
如何设置CSV文件表头
您可选择是否为CSV文件增加表头。在示例文件customer.csv中,表头包含三个列名:cust_no,name和level。
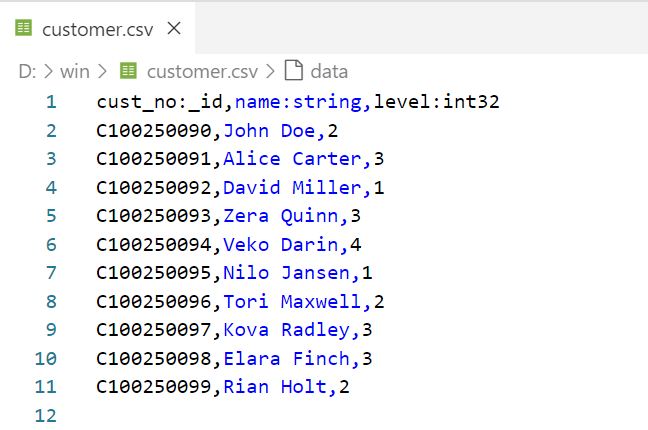
有表头无类型的CSV文件
可在配置文件的nodeConfig/edgeConfig > properties > name部分引用列名。
可使用<colName>:<valueType>格式为各列指定值类型,如:
有表头有类型的CSV文件
指定格式后,可省略在配置文件nodeConfig/edgeConfig > properties > type部分定义属性类型。
如果CSV文件无表头,系统将按照顺序将各列映射为属性。如果配置的属性个数与文件中总列数不一致,需在配置文件中将settings > fitToHeader设定为true,以避免报错。
无表头的CSV文件
如何从文件夹导入数据
您可从包含多个CSV文件的文件夹将数据导入嬴图数据库。需确保这些CSV文件符合以下标准:
- 文件名: 以
<xxx>.node.csv或<xxx>.edge.csv格式为点文件或边文件命名。 - 表头:所有CSV文件必须有表头,并使用
<propName>:<propType>格式为各列指定属性名和值类型。- 点数据可包含一列数据,对应唯一标识符
_id,列名为_id:_id。 - 边数据必须包含两列数据,用来指定起点和终点,列名分别为
_from:_from和_to:_to。
- 点数据可包含一列数据,对应唯一标识符
点击下载示例文件夹:
解压缩文件后,可将文件夹保存在ultipa-importer所在目录下。
从文件夹导入数据时,配置文件不支持配置点或边的详细信息。只能在nodeConfig和edgeConfig部分指定同个文件夹目录。
...
# 点配置
nodeConfig:
# 本地计算机或SFTP上的文件夹路径
- dir: "./dataset"
# 边配置
edgeConfig:
# 本地计算机或SFTP上的文件夹路径
- dir: "./dataset"
...