HDC
概述
Katz中心性(Katz Centrality)算法用于衡量点的影响力,其考虑因素包括点的直接连接和不同距离下的间接连接,同时为更远距离的点赋予较小的权重。
Katz中心性取值范围为0到1,分值越高,说明点在网络流动和连接性上影响力更大。
参考文献:
- L. Katz, A New Status Index Derived from Sociometric Analysis (1953)
基本概念
Katz中心性
Katz中心性是对特征向量中心性的扩展。特征向量中心性进行第k轮影响力传播时,中心向量更新为c(k) = Ac(k-1),其中A为邻接矩阵。Katz中心性在此计算过程中引入两个新参数,得到以下更新公式(之后需要重新缩放):
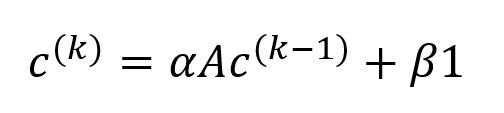
其中,
α(alpha)为衰减因子,用于控制每轮传播中的影响力衰减。在第k轮,k步外间接邻居带来的影响也会被考虑在内,其总贡献度经αk逐步衰减。为确保c(k)能够收敛,α必须小于1/λmax,其中λmax是邻接矩阵A的最大特征值。β(beta)为基准中心性常数,用于确保每个点的中心性分值均不为零,即便该点未收到任何影响。通常为β取值为1。1为n × 1的向量,所有元素均为1,其中n为图中点总数。
示例图集
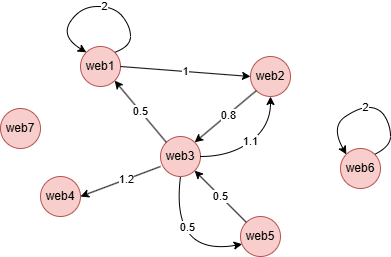
创建示例图集:
// 在空图集中逐行运行以下语句
create().node_schema("web").edge_schema("link")
create().edge_property(@link, "value", float)
insert().into(@web).nodes([{_id:"web1"}, {_id:"web2"}, {_id:"web3"}, {_id:"web4"}, {_id:"web5"}, {_id:"web6"}, {_id:"web7"}])
insert().into(@link).edges([{_from:"web1", _to:"web1",value:2}, {_from:"web1", _to:"web2",value:1}, {_from:"web2", _to:"web3",value:0.8}, {_from:"web3", _to:"web1",value:0.5}, {_from:"web3", _to:"web2",value:1.1}, {_from:"web3", _to:"web4",value:1.2}, {_from:"web3", _to:"web5",value:0.5}, {_from:"web5", _to:"web3",value:0.5}, {_from:"web6", _to:"web6",value:2}])
创建HDC图集
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为hdc_katz:
CALL hdc.graph.create("hdc-server-1", "hdc_katz", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: false
})
hdc.graph.create("hdc_katz", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: false
}).to("hdc-server-1")
参数
算法名:katz_centrality
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
max_loop_num |
Integer | ≥1 | 20 |
是 | 最大迭代轮数。算法将在完成所有轮次后停止 |
tolerance |
Float | (0,1) | 0.001 |
是 | 某轮迭代后,若所有点的分值变化小于指定tolerance时,表明结果已稳定,算法会停止 |
edge_weight_property |
"<@schema.?><property>" |
/ | / | 是 | 邻接矩阵A中用作权重的数值类型边属性;不包含指定属性的边将被忽略 |
direction |
String | in, out |
/ | 是 | 使用各点的入边(in)或出边(out)构建邻接矩阵A |
alpha |
Float | (0, 1/λmax) | 0.25 |
是 | 衰减因子,必须小于邻接矩阵A的最大特征值(λmax) |
beta |
Float | >0 | 1 |
是 | 基准中心性常数,用于确保每个点的中心性分值均不为零 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
order |
String | asc, desc |
/ | 是 | 根据katz_centrality分值对结果排序 |
文件回写
CALL algo.katz_centrality.write("hdc_katz", {
params: {
return_id_uuid: "id",
max_loop_num: 15,
tolerance: 0.01,
direction: "in"
},
return_params: {
file: {
filename: "katz_centrality"
}
}
})
algo(katz_centrality).params({
projection: "hdc_katz",
return_id_uuid: "id",
max_loop_num: 15,
tolerance: 0.01,
direction: "in"
}).write({
file: {
filename: "katz_centrality"
}
})
结果:
_id,katz_centrality
web3,0.399527
web7,0.335089
web1,0.40142
web5,0.368555
web6,0.365776
web2,0.401707
web4,0.368732
数据库回写
将结果中的katz_centrality值写入指定点属性。该属性类型为double。
CALL algo.katz_centrality.write("hdc_katz", {
params: {
edge_weight_property: "@link.value"
},
return_params: {
db: {
property: "kc"
}
}
})
algo(katz_centrality).params({
projection: "hdc_katz",
edge_weight_property: "@link.value"
}).write({
db:{
property: 'kc'
}
})
完整返回
CALL algo.katz_centrality("hdc_katz", {
params: {
return_id_uuid: "id",
max_loop_num: 20,
tolerance: 0.01,
edge_weight_property: "value",
direction: "in",
alpha: 0.25,
beta: 1,
order: 'desc'
},
return_params: {}
}) YIELD kc
RETURN kc
exec{
algo(katz_centrality).params({
return_id_uuid: "id",
max_loop_num: 20,
tolerance: 0.01,
edge_weight_property: "value",
direction: "in",
alpha: 0.25,
beta: 1,
order: 'desc'
}) as kc
return kc
} on hdc_katz
结果:
| _id | katz_centrality |
|---|---|
| web1 | 0.416245 |
| web2 | 0.400671 |
| web6 | 0.398739 |
| web3 | 0.373287 |
| web4 | 0.369527 |
| web5 | 0.347756 |
| web7 | 0.332239 |
流式返回
CALL algo.katz_centrality("hdc_katz", {
params: {
edge_weight_property: "@link.value",
direction: "in"
},
return_params: {
stream: {}
}
}) YIELD kc
RETURN CASE
WHEN kc.katz_centrality > 0.4 THEN "important"
ELSE "normal"
END as r, count(r) GROUP BY r
exec{
algo(katz_centrality).params({
edge_weight_property: "@link.value",
direction: "in"
}).stream() as kc
with case
when kc.katz_centrality > 0.4 then "important"
else "normal"
end as r
group by r
return r, count(r)
} on hdc_katz
结果:
| r | count(r) |
|---|---|
| important | 2 |
| normal | 5 |